The Elastic Compute Cloud (EC2) offered by AWS as public commercial service has been one of the first and probably the seminal service for the research on cloud applications and infrastructure. From an application perspective, hosting in EC2 means wrapping the application into one of the provided virtual machine (VM) images and instantiating it in sufficient numbers (e.g. with autoscaling). Ultimately, for custom applications, it also possible to import custom VM images. This involves creating the machine image, testing it on a local hypervisor (KVM, Xen, VirtualBox, …) or in a local cloud stack (OpenStack, CloudStack, OpenNebula, …), then copying the image into the Simple Storage Service (S3) (in a reliable manner), initiating the import process, and waiting for the VM image called Amazon Machine Image (AMI) to become available. This import process is not well-documented and regularly causes high effort with application providers. Hence, this blog post offers a detailed walk-through and points out common pitfalls.
The first step towards explaining the EC2 import process is to represent it as abstract state machine with transitions. According to the states documentation, there would be four states: active, deleting, deleted, completed. However, by experimental use of the service, logging the (sub-)state every second, and extracting the timed state transitions, we found out that at least 12 distinct states exist. These are:
- pending
- validating / validated
- converting
- updating / updated
- preparing to boot
- booting / booted
- preparing ami
- completed
- deleting / deleted
- a few more which are probably not by design, as shown below
The transitions can be divided into success, failure and endless loops. In the following figure, which represents measurements with a typical small image file of about 500 MiB, success is measured by a north-bound transition, failure by a south-bound one, and an endless loop by an east-bound one.
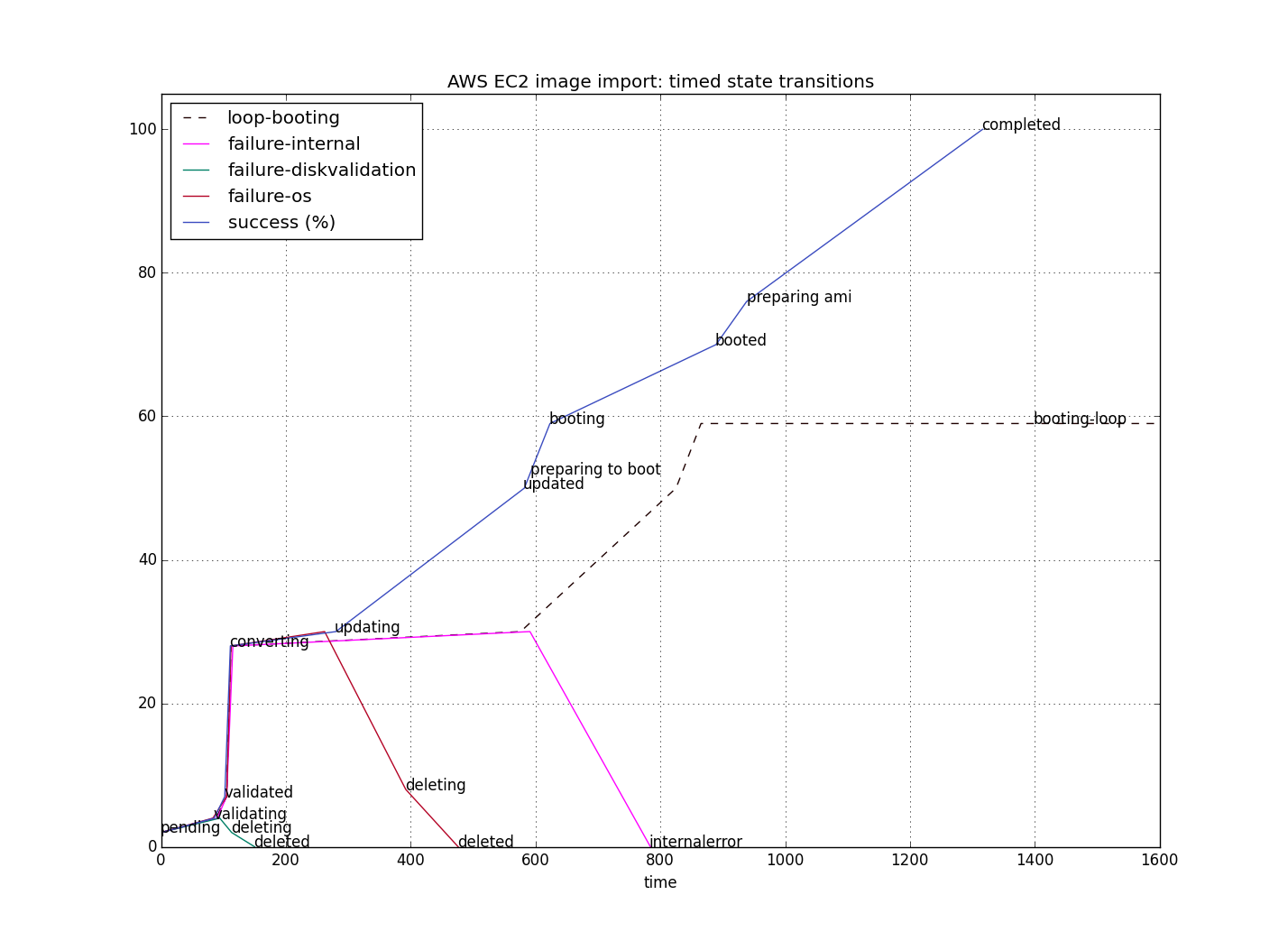
Some of the values are hard-coded estimations. The estimation for converting is clearly too conservative; using a value of 20 instead of 28 would be more appropriate. Using the command-line tool
aws ec2 describe-import-image-tasks
the failures manifest as follows in human-readable text format:
IMPORTIMAGETASKS MyVM import-ami-xxxxxxxx deleted ClientError: Unknown OS / Missing OS files. IMPORTIMAGETASKS MyVM import-ami-xxxxxxxx deleted ClientError: No valid partitions. Not a valid volume. IMPORTIMAGETASKS MyVM import-ami-xxxxxxxx deleted ClientError: Unsupported kernel version 3.16.0-4-686-pae IMPORTIMAGETASKS MyVM import-ami-xxxxxxxx deleted ClientError: Disk validation failed [Unsupported OVA format] IMPORTIMAGETASKS MyVM import-ami-xxxxxxxx active ServerError: an internal error has occurred during conversion. IMPORTIMAGETASKS MyVM import-ami-xxxxxxxx active booting [endless]
Most failures are deterministic, either caused by issues already present in the VM image (e.g. non-bootable images) or caused by limitations of EC2’s hypervisor setup (using Xen and PV-Grub) compared to local hypervisors. Some failures can be assumed to be implementation bugs within EC2. In particular, endless loops should never happen, and failure sources should be identified more clearly so that internal errors are not propagated to EC2 clients. This means that despite being assumed to be one of the most seasoned and reliable cloud computing services, EC2 still suffers from unnecessary limitations and runtime bugs. The categorisation of decisions to be taken by the application developer (more appropriately, packager) which triggers the associated limitations and faults is shown in the following table. It takes into account the image format (raw disk file with or without partitions, VDI, VMDK wrapped into OVA) and the early boot stages: bootloader, init process. It omits later stages including the network setup and eventual connectivity to services exposed by the VM instance.

The odgxr combination corresponds to a stock Debian VM installation which is known to work well with the import service. The derived recommendation for VM images is therefore to build them with the Grub boot loader and its configuration, using a partitioned disk with at least one partition, and an appropriate 64-bit Xen-enabled kernel booting with initrd. Yet, when building a minimal image from scratch using this combination of configuration choices, it still results in the ominous Unknown OS / Missing OS files error message, which is not very helpful without further details. There are small differences between the images which need further investigation. Looking into the trend of massively booting tiny instances, a design which would support small pieces in all aspects (e.g. using recvirt minimal kernels with recursively nested virtualisation support, extlinux as bootloader and partitionless boots with just initrd) would be a helpful innovation to let users experiment with the most recent microservice designs, including the recently proposed clear containers concept.
We make our preliminary findings available as preliminary analysis of EC2 without rating the service compared to others, but we will also analyse other compute services in the future and report about them. This will help cloud providers to streamline the onboarding process with improved tools, and application developers to migrate into the cloud with less effort. As usual, our experiment setup is publicly available through a Git repository maintained by the Service Prototyping Lab.
Hi! I’m running into the “Unknown OS / Missing OS Files” issue trying to make an AMI of Alpine Linux. Apparently the OS check is more than just /etc/os-release. Did you make any further progress?
Hello Joseph. We did not advance our analysis yet as we wanted to take a short break to get back to our other research topics. But the general issue of how to deterministically import VM and containers into IaaS providers remains. We’ll blog about it once we resume. If you find any pointers to resolve your issue, please feel free to mention it here.
Hi,
Thanks for this blog. We will like to see deeper insights especially in booting loop phase.
Thank you for your feedback. We haven’t gained more insight yet but will keep this on our radar as topic of interest.
Hello something surprising….same OVA file when uploaded and converted to AMI however when attempted second time it stuck in booting phase at 59%. I tested multiple times, not sure why in one attempt it goes through successfully in next it stuck in booting phase.