Cloud services are meant to be elastically scalable and robust against all kinds of failures. The core services are very mature nowadays, but the tools which glue them together are often in need of quality improvements. Two common risks in networked environments are (1) unavailability and (2) slowness of services. The first risk is easier to detect but more severe in its effects. Furthermore, there is a dependency between the two as timeouts in many layers of the software cause unavailability failures upon strong slowdown. Timeouts should be avoided but are often part of protocols, libraries, framework and stacks with almost arbitrary combinations, so that in practice, failures happen more often than necessary. This post shows how research initiatives in the Service Prototyping Lab work on improving the situation to make cloud services access more robust and easier to handle for application developers.
Imagine the scenario of uploading a virtual machine or container image with a footprint of several hundred megabytes with the goal of making it available to compute instances. On faulty network connections, any upload can be interrupted which would require subsequent retries until the upload succeeds. AWS S3, Git and Git-hosted cloud offerings (e.g. OpenShift) are such services with tooling issues related to these interruptions. The AWS and Git command-line tools will not attempt any re-uploads and will instead report failures. For automated scenarios in which such tools are used, this is not always the desired behaviour. In our work, we have observed, measured and improved the service behaviour of AWS S3 but generalise the results for similar services.
The figure below shows how many 33 MB file upload attempts are necessary at an (artificially emulated) slow network connection with a packet delay of 5s. Of 29 attempts, only two have been successful, and 12 retries are needed on average. This suggests that although such a retry functionality is desirable, it is not economically to push the same file again and again, and a better solution is needed. An advantage is that the functionality can be and has been implemented in a drop-in wrapper script to aws-cli without further modifications.

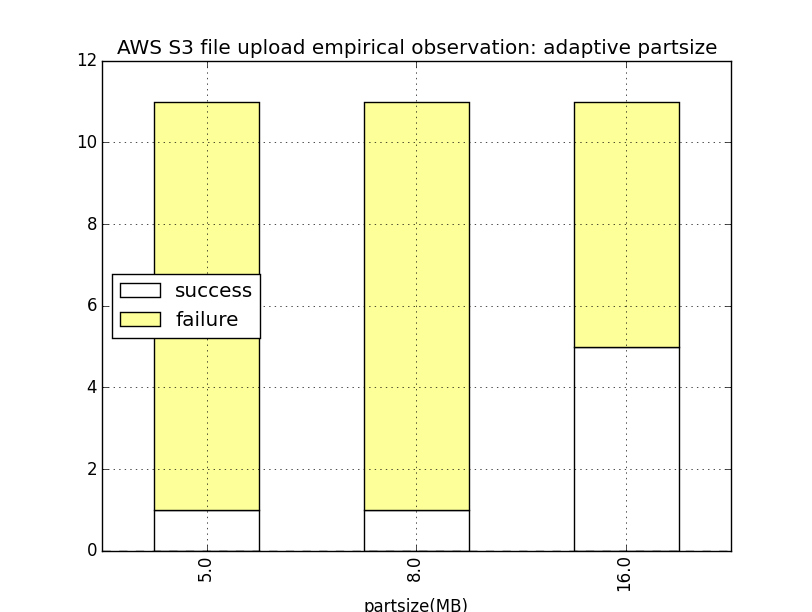
Multiple tools support the incremental (delta) transmission of files. Git does not support it, but Rsync is a traditional example, and the S3 tool of aws-cli also supports it. But again, it does not automate retries for uploads, even though the functionality is foreseen in several other methods. It merely offers multi-part uploads which can however be a building block towards more fine-grained retries. The next figure shows how the success rate depends on the file sizes (9 to 33 MB) and, by extension, on the underlying part sizes for multi-part uploads (4.5 to 8.25 MB). While the quantity of measurements is small, the observation that mid-sized parts have the least success rate suggest that there is most likely no linear correlation between the two metrics, and hence, no optimal start configuration. Still, we have added a new parameter –chunk-size so that each session of aws-cli can be invoked with custom values instead of relying on the global configuration.

The next figure details the same observation for a single file with fixed size (33 MB à 7 parts using the S3-imposed minimum part size of 5 MB).
With some minor modifications, the aws-cli tool obeys to user policies on whether and how often to retry uploads, either in whole or in parts. Each unimpaired upload consists of a prepare statement, n * parallel part uploads, and a commit statement. With retries, which are executed directly after failures, the (n+2) factor is multiplied with another one which depends on the average retry rate. Advanced tools such as CloudFusion offer retries with exponential back-off times, but for our observation, we are merely interested in the trade-off between success rate and retransmission overhead. The policy is therefore expressed through two environment variables, AWSRETRY (positive number for limited attempts, negative one for unlimited attempts) and AWSRETRYDEBUG (for experiments).
The figure below shows how depending on the network delay (5-15s) and the maximum attempts for repeated uploading (3, 5 or ∞) the trade-off is between pure quality (at any cost), pure cost (no matter what quality), or anything in between. Depending on the scenario, all configurations are useful. For instance, an application transmitting mass data can be hosted much cheaper if occasionally lost messages are tolerated, and AWSRETRY=0 is appropriate. An application transmitting records with individual value will go for AWSRETRY=-1 (∞). The ideal situation would be 100% success rate with an overhead factor of 1.0, which can be reached with any configuration only in case of perfect networks.
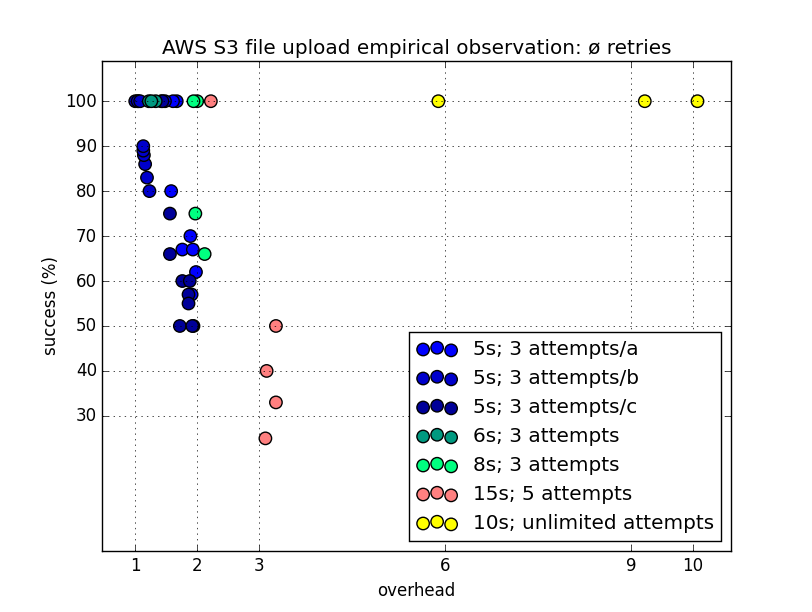 Yet, the results show that even in extreme network conditions, unlimited file-part retries work and are still economically viable compared to limited whole-file uploads due the failure probability distribution over all parts. Furthermore, these retries simplify the creation of automation tools with contract programming which requires a clear specification of the behaviour of tools given user policies.
Yet, the results show that even in extreme network conditions, unlimited file-part retries work and are still economically viable compared to limited whole-file uploads due the failure probability distribution over all parts. Furthermore, these retries simplify the creation of automation tools with contract programming which requires a clear specification of the behaviour of tools given user policies.
The Service Tooling research initiative in the Service Prototyping Lab hence investigates more appropriate tooling for service-based cloud applications, and the Active Service Management research initiative considers controlled active fault provocation and injection to trigger the robustness and resilience properties of Cloud-Native Applications, Cloud Application Development Tooling and other cloud tools.
A Git repository aws-cli-retry is available to fetch the necessary code modifications in aws-cli. Among them are the introduction of the AWSRETRY environment variable as well as a bugfix against wrong part counting. According to scientific research expectations, all experiment scripts (including the awsretry wrapper) and logs containing the raw data are available as well in another repository called aws-cli-experiments.