Vienna, the second-largest city in the German-speaking world, had become a meeting place earlier this week for software and service engineers who explore the crossroads of software architecture, DevOps processes and continuous-* (software development, integration, delivery) approaches. The 1st Vienna Software Seminar had mixed business and academic participants and has been of particular interest to architects and practitioners who want to migrate applications or related processes into cloud environments and are in need of relevant methods and tools. With its interactive agile format and focus on break-out groups, the seminar was structured so that topics could be discussed in detail and grouped by interest. This report summarises the four-day event including some highlights from selected discussions from a participant perspective.

First day of VSS
While reporting on the first day is limited because of initial absence due to lecturing commitments by the reporter, the mix of topics warrants a brief summary with key points conveyed in brief interactions with the speakers. The first keynote by David Lebutsch and Daniel Pittner from IBM focused on continuous integration with contract testing with challenges in microservice environments due to the connectivity complexity. The talk then hinted to Pact as suitable testing support. They keynote was followed by two lightning talks, the first of which was given by Petr Tůma and Lubomir Bulej from Charles University’s Department of Distributed and Dependable Systems in Prague, on the topic of reality-checking performance testing. The identified issue has been the inaccurate measurement, representation and reproduction of experiments especially for systems research. The second talk focused on code reviews in combination with continuous integration and was delivered by Shane McIntosh from McGill University in Montréal, Canada. Among the break-out session topics was a deeper look into the role of standards for DevOps, a recurring topic during many of the presentations and discussions, given the relative immaturity of many DevOps processes.
The second keynote by Bram Adams from Polytechnique Montréal inspected the build lifecycle which can be triggered by a single commit, akin to the butterfly effect in chaos theory. Lightning talks then complemented the view on build pipelines. Robert Chatley from Imperial College London looked at practical considerations of pipelines, and Jussi Tuovila from F-Secure Corporation gave a business perspective on client-side continuous deployment, which was also a discussion point for the next break-out session. Robert has presented his work on release cycle maps which follow a path of analysis, approval, operation and validation, starting from a product (or service) vision to a set of measured values.
The first day concluded with a reception in the basement of the seminar venue, the new computer science department building of University of Vienna.

Second day of VSS
Eberhard Wolff, a fellow for the 100+ people strong German and Swiss consultancy InnoQ, gave insights into the limits of continuous delivery in the third keynote. As the author has written a couple of books about microservices and knows of practical cases, the limitations seem to appear more frequently than desired in practical work. According to the speaker, the highest priority in continuous delivery shall be the customer satisfaction, with a focus on the continuous part and less on technical aspects of the actual delivery process. A further related statement has been that CI/CD is about people and less about technology and that companies should embrace it despite perhaps not having the management buy-in. Naturally, these statements provoked a discussion. Should BMW perform over-the-air firmware updates for safety-critical functionality, just because Tesla is doing it (in some jurisdictions)? Are managers still needed beyond agile teams in larger organisations? Are there limits of applicability?
Afterwards, two lightning talks by academic researchers were given, starting with Carmine Vassalo from the University of Zurich’s SEAL team on the topic of breaking code in simplified source-build-deploy-test pipelines. Breaks can be good or bad, according to popular opinion, but are rather good according to the speaker’s statements for reasons such as early feedback and indication of a healthy work environment if experimental code pushes are tolerated or even encouraged. The subsequent discussion evolved around the details of when a breakage occurs. The second talk, by Vasilios Andrikopoulos at the University of Groningen, presented application engineering principles for cloud-based applications, which according to the speaker encompass both cloud-enabled and cloud-native architectures. By definition, cloud-based applications (CBA) depend on at least one cloud service. However, the definition of cloud-enabled more closely resembles cloud-aware in other presentations and literature. Therefore, a more refined and formalised definition of cloud application maturity levels is still needed. The speaker sees the cloud as a platform for software development which drives DevOps, largely through the concentration on microservices. Despite improving technology, we as engineers are still notoriously bad at designing service interfaces and scopes. References were given to the Netflix dependency diagram which had only little connection to hosted VMs anymore, and to the older S-Cube reference lifecycle. An interesting future research topic are autonomic (MAPE-K-loop controlled) topology variations to make cloud applications more portable. The discussion then picked up on one of the principles that stated that engineering needs to optimise for the cost at scale, which does not seem to be a relevant problem for 95% of companies. Furthermore, the relationship between CBA and the 12-factor app methodology was clarified.
The resulting break-out session continued on CBA including the current trend of monopolisation among the big four public cloud providers, and the fate of private clouds, given that feature parity and portability appears to be impossible even for the large vendors (Azure Stack, IBM Cloud Private). The changing role of software architects was also highlighted, given that their role now includes touching code and exploring software and service ecosystems more than drawing connected boxes in isolation.
The fourth keynote was given by Uwe van Heesch from HAN, an applied sciences university in The Netherlands. He reported on fighting documentation smells, referring to version mazes, cyclic references or simply zombie docs in continuous software development. According to the speaker, the solution is to integrate the documentation process explicitly into the software engineering process, including executable documentation (Swagger, Docker Compose, Ansible, Cucumber tests) and clean code which needs less implementation-level documentation. The discussion suggested to maintain documentation in version control systems along with code instead of using isolated wikis, although there may be limits for Doxygen or architecture metaphors. Model/code integration and tools were also discussed.
In the afternoon, Ta’id Holmes from Deutsche Telekom talked about project Terastream, or CI/CD in hyperscale. The speaker put emphasis on combining model-driven and non-model-driven code with requirements per role (application engineer/vendor, platform provider, legislator, service provider and end customer). Deployment scripts such as Ansible or Heat can be generated by transforming models into code. Patrizio Pelliccione from Chalmers/Gothenburg University in Sweden reported on an industrial cooperation with Volvo. He mentioned a new car brand which focuses on design and software and outsources all manufacturing to Volvo, becoming the first software-only carmaker. According to the speaker, formalisms to express architecture are missing (beyond UML and ADL), as are architecture frameworks and process models beyond the V-model and the *-in-the-loop approaches, due to the high complexity. The discussion then picked up this point and asked for the sources of complexity, which was answered with references to many possible sources.
The break-out session then changed topic to teaching of DevOps. First, the participants compared their curriculums also in related disciplines like agile software engineering, service prototyping, cloud computing and engineering, as well as administration and operations. Several books on these matters were recommended. The degree of using research in labs was debated, using labrats as metaphor. Furthermore, exposing the students upfront to non-technical and more managerial topics such as agile development was questioned, and the positioning of Docker as dev or ops tool was raised. An interesting argument for teaching DevOps has been that build pipelines can be more complex than the actual business logic nowadays. In the second part of the session, the discussion shifted to expected competences, including keywords found in job advertisements by companies.
The day was concluded with a gala dinner in the great city hall of Vienna where participants were greeted on behalf of the mayor.

Third day of VSS
On the third day, Laurie Williams from North Carolina State University dedicated her keynote to the reflection on the Continuous Delivery Summit. The event has been run each year since 2015 with the rule of allowing only one participant per company for a more intimate setting. Ten repeating themes could be identified. Among them is experimentation of features on production systems, flaky tests which show non-deterministic behaviour, shameless retrospectives on failures, technical debt due to switched off feature flags but still present dead code, and customer acceptance of forced updates. The keynote statements were vividly discussed, starting with key metrics for features, which typically consist of a few KPIs and some explanatory variables. CD appears to not yet have arrived in the mainstream given that only few summit participant already use it across their software product and service lines. After initial hype, some reality checking has occurred concerning continuous experimentation and CE is now used more carefully for features which need it. For user interfaces and performance, defining hypotheses is easy but beyond it gets harder. Security metrics and processes are typically isolated from CD but first counterexamples are known from for instance Slack and Twitter development practices.

Again, two technical talks followed, the first one by Erik Wilde, CA API Academy, who evangelises ideas and technologies related to API management and gateways. He reasoned about microservice architectures which essentially are about service autonomy and effectiveness in service-oriented landscapes. One interesting point raised was that service ecosystem engineering differs considerably from system engineering. This point was taken up in the discussion about why it is hard to bring web architectures into the enterprise, which can be partially explained by architects struggling to take a step back and let developers work more self-guided.
A highly analytical talk by Cesare Pautasso from the University of Lugano followed about the BAC theorem which, in analogy to CAP, postulates that, under certain circumstances, consistency and availability of data can only be achieved when no backups are made across polyglot data persistence stores attached to microservices. The circumstances require that parts of the data reference other data indirectly through microservice interfaces. This applies to some extent event to applications assuming eventual consistency, as eventual simply means never when data is lost and cannot be restored, which could nevertheless be somewhat mitigated with auto-snapshotting databases.
The interesting BAC and eventual inconsistency finding was embedded into a broader discussion on how to decompose monoliths into microservices, followed on in the breakout session. Experience around the seminar participants suggests that there is an inherent difficulty with splitting data and furthermore with developer qualification who at the same time need to learn new skills, new mindsets, and new domain-specific languages and other technologies. Debugging, for instance, can no longer be done by setting breakpoints, and distributed debugging tooling is not yet ready for primetime. Eventually, developers will have to accept not having a global picture anymore when there are hundreds or thousands of microservices involved. An open question is the decomposition methodology, following a solar system approach where additional microservices orbit around the remaining monolith, or rather a big bang change. Few experiences are known for parallel refactoring as typically the short-term goals would not be matched. Yet, there is a risk with ending up with a big distributed monolith.
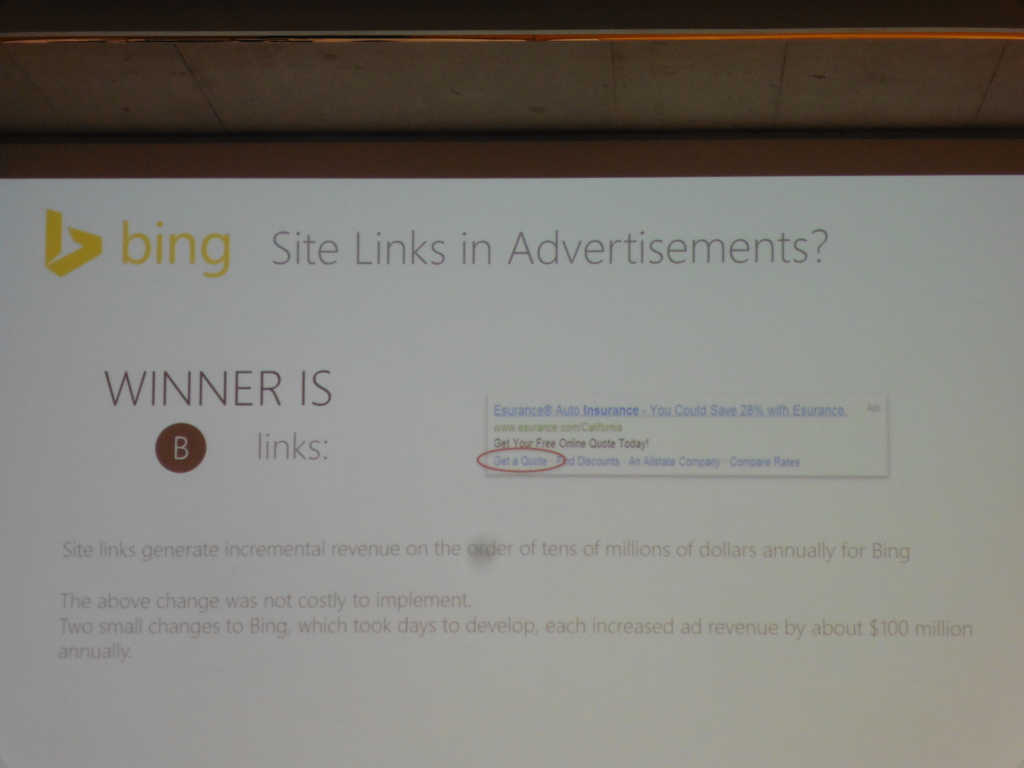
In the afternoon session, Katja Kevic and Brendan Murphy from Microsoft Research demonstrated continuous experimentation at scale in Microsoft products, ranging from search engines (where failing fast is an option) to mail servers (less so) and database management servers (not at all). The workflow foresees the definition of hypotheses, running A/B tests, collecting behaviour, deriving data-driven or manual decisions, and eventually filtering all deployments depending on whether or not changes were considered positive. The speakers showed how a small change resulted in an annual revenue change to the tune of 100 million USD, based on the vast collection of more than 1400 metrics per experiment. Again, the handling of technical debt was discussed, with a hint on distinguishing cheap and expensive feature flags. The discussion raised the subtle difference between feature flags and software product lines. The flags convey customer acceptance metrics, but are very subjective and may be flaky.
In the subsequent lightning talk, Gerald Schermann from the University of Zurich contrasted with the academic view on continuous experimentation. The main purpose is to practice the mitigation of risks in software release processes which are sped up considerably by the introduction of CD. Four main identified techniques encompass canary releases, incremental releases, dark launches and A/B testing based on hypotheses, while the technical implementation might use feature toggles or traffic routing through sidecars and proxies in microservice architectures. The service calls are traced, call latency is related to synchronised duplicate data, and compositions are traced as well to troubleshoot with all responsible developers or teams in a (virtual chat/war) room to ensure the assignment of responsibility for fixing. In the discussion, it was acknowledged that current tools such as Zipkin require manual header injection in a framework which supports that, e.g. Kubernetes.

The other technical talk was given by Christian Macho, University of Klagenfurt, adding to Carmine’s talk on build breakage but advancing the ideas into automated repairs. A clear motivation has been given with a project in which 900 person hours were spent to fix breakages. The speaker developed a tool to analyse Maven log files to find out dependency-related failures. The two research questions then were concerned with the strategy side, how to repair, and the automation side, how to derive and execute a repair plan.
In the breakout session, a continuation of the discussion on breaking up monoliths was realised. In practice, there are now often larger data lakes on top of which newer microservices are built to load and, if necessary, transform and normalise the relevant data. This can be partially automated by generating APIs from database schemas. Tool support is still immature, especially for debugging and in the runtimes, for instance for secret management. Another discussion subject has been the path from monolithic codebases into one-repository-per-microservice conventions. The support in programming languages to build distinct services without code duplication or monolithic code collections has also been discussed.
The day was concluded with a visit to the Viennese Christmas market where discussions continued often in bilateral format.
Fourth day of VSS
The last day started with a keynote on DICE, a European-funded project to explore DevOps for Big Data and high-quality data-intensive applications, by Giuliano Casale from Imperial College London. The project aims to delivery a DevOps toolchain as well as an automated quality analysis of logs abouts builds and other steps in the pipeline. It assumes a triangle of data, platforms, and methods/tools, and sees Lambda and Kappa architectures as new trend. However, the practical focus of DICE is on the integration of four projects to get a baseline system for performance engineering: Hadoop, Cassandra, Spark and Storm. According to the speaker, what is still missing is a workflow-like expression for “DataOps” which can be used by data scientists. DICE’s approach of mutating and combining configuration options resembles our work on quantifiable elasticity boundaries in that wrong configuration can have a high performance cost. The DICE work is advanced in the sense of considering a proper configuration optimisation workflow, starting with initial design and model fitting, through sequential blackbox optimisation, but also Bayesian optimisation. The project approach has been demonstrated in a scenario which shows that even expert administrators who fine-tune the data processing tools can be outperformed by automated optimisation in just a few iterations. The ensuing discussion was short and focused on whether production systems would be considered, which is not the case and also not necessary beyond the initial optimisation, and whether the semantics and complexity of configurations can be compared. Our future work on elasticity could benefit from the suggested optimisation approaches.
In the next talk, Andreas Steffens from RWTH Aachen presented his work on self-organising continuous delivery pipelines. This work kind of resolved the issue raised in the earlier breakout session on teaching that sometimes the build pipelines are more complex than the code. In the approach, the pipelines are generated from a higher-level domain-specific language. Showing the example of a large German travel booking portal, the pipelines could be optimised to fail a lot faster despite requiring a little amount of extra time to run overall. Yet, the developer turnaround times will benefit greatly from the faster fails.

Afterwards, our own work on serverless tools was presented, coupled with a few speculative, opportunistic and generally forward-looking statements on how delivering code as functions can be streamlined and improved in the future. The approach foresees the combination of debugging, tracing, profiling and autotuning techniques. Within the lightning talk, a short half-minute FaaSification demo was given. The slides for the talk are available online.
Due to the high interest in discussing serverless issues, two breakout groups were established which discussed only few overlapping topics. The first group in particular debated about security shortcomings, composition languages, and various other aspects such as application models, operational patterns (like sidecars for functions) and the bifurcation of software engineering due to the trend towards adding glue functions between provider-specific services.
After lunch, a few additional lightning talks were given. However, the reporter was unable to attend due to travel planning. We would like to thank the VSS’17 organisers for putting together such an impressive programme schedule and opportunity for meeting, learning, discussion and planning of future activities.