
The computer science department of AGH University of Science and Technology in Kraków has produced substantial analytical research contributions to assess the suitability of cloud functions as a basis for scientific workflows and computing platforms. Therefore, representing our similar research interests in the Service Prototyping Lab at Zurich University of Applied Sciences, we arranged an intensive two-day exchange including a research seminar, some live experiments and many inspiring discussions. This blog post summarises the talks and experimental results and provides an overview about evident trends and possibilities for future research in this area.
On June 6, a research seminar entitled «Understanding Mixed-Technology Cloud Applications» (slides) drew the interest of a dozen research staff, candidates, infra operators and students. Obviously, the title is flavoured with a slight portion of irony because such an understanding is hard and mixed-technology engineering of cloud applications is only in its infancy. Nevertheless, the talk increasingly turned into an interactive discussion which raised several concerns regarding the data access, the microbilling granularity, and the handling of authentication in applications partially or wholly based on cloud functions.

Local research on applications, systems, stacks and workflows is highly interconnected with the operational perspective through Cyfronet, the university entity which among other systems runs Prometheus, a watercooled TOP500 system. Through this link, the interest to execute jobs in workflow systems through cloud functions has led to extensions to the distributed HypeFlow workflow engine. However, as workflows in scientific computing infrastructure are subject to scheduling and allocation planning, predictable cloud functions with stable latency and machine-readable limitation descriptions are needed which are practically not available. Driven by this unfulfilled need, there is a trend to add placement hints into workflow and microservice composition languages which contain information whose automated inference by the execution environment, for instance the workflow engine, would be non-trivial due to the mix of technical and economic factors which decide which part of the application runs best where. In line with these requirements, and in conjunction with our monitoring of digital service ecosystem monitoring, we are calling for community contributions to the FaaS characteristics and constraints database.

Adding to the economic model argumentation, applications which process a large amount of small volumes of data in parallel may be a source of loss due to the cumulation of sub-100ms idle periods in commercial FaaS contexts. A debate was sparked whether reusing the remaining tiny time slices would do any good. Previous work on reusing, recycling and reselling unused VM capacities is widely available (one paper, another paper) and in principle should apply to cloud functions but the short intervals combined with high latency due to external data access may prevent such mechanisms from being successful.

As results-oriented researchers, we quickly wrote a simple simulation of a bag-of-tasks processing system which would perform image processing over a collection of photos (git repository). It is clear that due to variable file and image sizes, a prediction of the duration of processing would not be feasible. Rather, a reactive approach which only checks for the amount of loss based on proximity to the microbilling interval of 100 ms has been chosen. There are two extremes in such a setting: A fully serial approach, in which the total loss is less than a single billing interval but the overall computing time may be prohibitively long (and even exceed the maximum processing duration imposed by FaaS providers); and a fully parallel approach, which yields the fastest results but also would on average lead to the loss of n/2 billing intervals (out of the theoretic maximum of n intervals) for any large n being the number of data units to be processed. The desired pareto front of solutions therefore includes combinations whose maximum processing time and whose idle periods are minimised. Early results from running the simulation suggest that for example with a continuation of processing in case 60-80% of the microbilling interval would be wasted, almost all savings to be expected on average can be achieved (i.e. serial processing cost equality becomes feasible) while the processing time can still be squeezed to 27-52%.
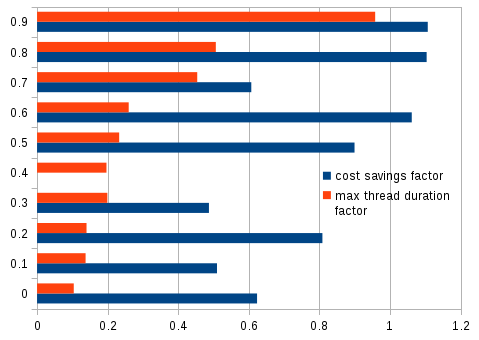
This optimisation makes online processing affordable for a range of applications otherwise confined to (slow) batch processing. From a software developer perspective, such concerns should however be handle by generated code or middleware at runtime, and current technology is far from that goal. Obviously, being able to exploit the potential savings will moreover depend a lot on low-latency FaaS techniques such as function instance-affine data stores and quick interconnects.

We would like to thank AGH for hosting us and for good input to important upcoming research plans, academic exchange and institutional structures and procedures. Certainly, we will jointly look closer into scheduling, placement and interoperability matters in FaaS offerings both in simulations and in actual systems. Several of the recent results will be reflected in a full-day tutorial on serverless computing at ICDCS’18 in Vienna on July 2, 2018. We encourage registrations and participations in this upcoming event.