Applications are increasingly delivered for cloud deployment as set of composite artefacts such as containers. The composition descriptions vary widely: There are Docker compose files, Vamp blueprints, Kubernetes descriptors, OpenShift service instance templates, and more. Ideally, taking these compositions and deploying them somewhere would always work. In practice, it is more complex than that. Commercial production environments are often constrained depending on the chosen pricing plan. Many applications would still run but due to over-estimating deployment information do not “fit” into the target environment. In this blog post, we look at how to “right-size” an application deployed into such a constrained Kubernetes instance, and furthermore propose a tool to automate this process.

A composite application typically appears as shown in the diagram below. Specifically in the case of Kubernetes, it consists of ephemeral containers to be deployed on one or more pods with certain horizontal scaling (replication) rules, as well as long-lived service definitions which ensure that a certain quorum of container instances is alive and servicing client requests. Applications can be deployed into dedicated namespaces to group all artefacts together. Furthermore, they can be resource-constrained on various levels, including the allotment of CPU cycles per container instance.
Kubernetes deployments are not adhering to ACID properties, even though rudimentary rollback exists. The undesired effect is that a deployment (using for instance kubectl create -f <appdir>) is starting, the first objects (deployments, services, namespaces) are created, while all of a sudden a permission error or quota exceedance occurs. The first result is a half-deployed application which needs to be cleaned up manually. The second, more severe, result is that the application provider is left wondering what to do.
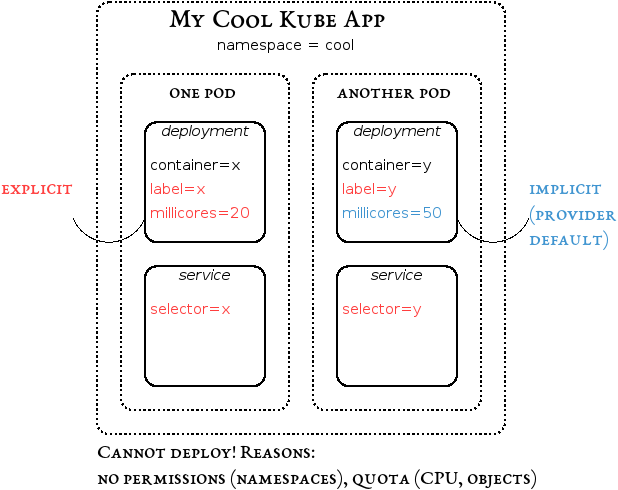
Through our research initiative on Cloud-Native Applications, we propose a tool to ease the onboarding. The tool will minimise a Kubernetes application as much as possible. It does so by a combination of rewriting and rewiring actions which depend on the constraints present in the target environment. The actions encompass replacing namespace declarations by labels, grouping of multiple containers into single deployments, and resource-constraining containers to explicitly use only few CPU cycles, called millicores in Kubernetes metric terms. The rewriting is smart in the sense of only grouping containers whose exposed ports do not conflict. Still, it requires properly engineered containers which make heavy use of discovery features to figure out where the respective dependency containers are running.
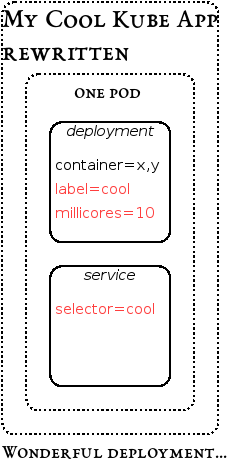
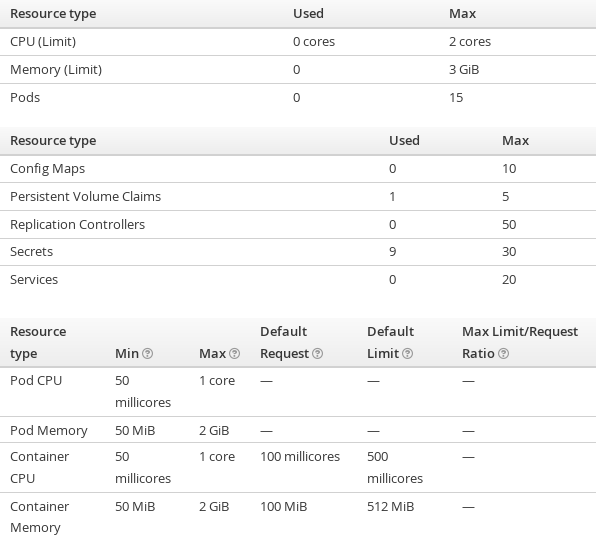
We have tested an initial version of this approach with our generic reference ARKIS Microservices application project which consists of two handful of frontend, backend and database containers in various composition variants depending on for instance multi-tenancy preferences. The resulting prototypical implementation is called Kube App Sizer. While it does not solve the ACID issue (yet), it increases the chances of getting an application running. We have performed several tests with a managed OpenShift environment which is a primary use case for restricted Kubernetes environments. The following slightly compacted screenshot shows representative limits and constraints in this environment.
The rewrite is invoked on the command line, specifying which files or directories make up the application. The JSON or YAML files are parsed, processed, structurally changed and rewritten into an output folder which contains both merged and unmerged deployment and service descriptors. A sample invocation using a script from the Git repository which ensures a prior checkout of the reference application is shown next.
$ ./rewrite-descriptors.run # convert namespace arkis to label (19 repetitions...) # constrain to 100 millicores (9 repetitions...) ! port conflict 27017 excluding arkismicroservices/KubernetesBlueprints/DatabaseMicroServices/nopersistance/USERS/arkismongo-users-deployment-no-persistance.json ! port conflict 80 excluding arkismicroservices/KubernetesBlueprints/FrontendMicroServices/userFrontendMS/user-deployment.json ! port conflict 80 excluding arkismicroservices/KubernetesBlueprints/FrontendMicroServices/loginFrontendMS/login-deployment.json # merge 7 out of 10 containers into a single deployment # rewrite into output.json # rewrite label selector service (6 repetitions...)
Several research results of the Cloud-Native Applications research initiative, including this tool as well as other composition, deployment and scaling innovations, will be demonstrated live at the upcoming Open Cloud Day on June 14 at the University of Bern. Register and join us at this event!