In a previous series of blog posts (1, 2, 3), we have discussed how to install Monasca to monitor OpenStack, how to create alarms based on specific events happening in the monitored system, and how to setup notifications when any of these alarms are triggered.
Going further, in the context of the Cloud Orchestration initiative and the Hurtle framework, we go further by using Monasca to detect events in orchestrated applications and perform callbacks to the orchestrator so it can react to events. The motivation behind this is provide hurtle with processes able to perform continuous health management of any orchestrated application.
While initially designed to monitor the Cloud itself, it is easy to install the monasca agent on any platform, making it simple to monitor deployed VMs behaviour.
Concepts
Below is the logical architecture of the reactive orchestration in Hurtle:
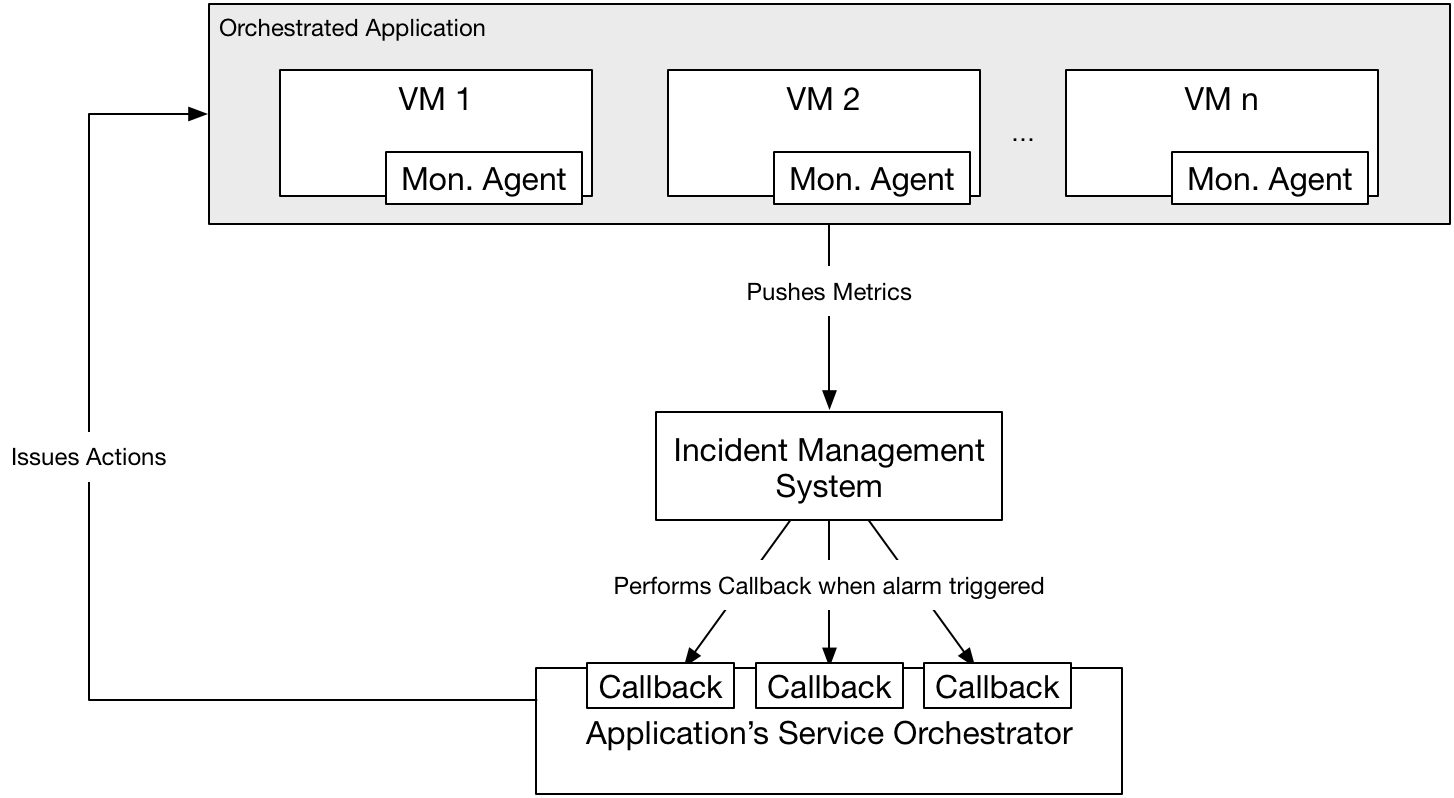
Each VM comprising an orchestrated application (see the logical architecture of hurtle to learn about how hurtle orchestrates services) hosts a Monasca Agent which pushes metrics to Monasca.
Monasca aggregates these metrics and performs a periodic alarm check process, checking all alarms against the metrics it receives.
If a threshold is reached, Monasca issues an alarm, which in turns sends a notification as an OCCI request to the Service Orchestrator controlling the deployed application. This orchestrator can then perform corrective action as required. Multiple alarms can be registered for the same systems, so it is easy to build a service orchestrator able to react to multiple types of events and in each case issue a specific action.
Implementation
Creating a service orchestrator able to react to triggered alarms requires a few modifications to the methods triggered at the deployment and dispose phases of the lifecycle. It also requires the implementation of a notify method which is called when a service orchestrator instance receives a notification callback.
Note that you can find a complete example of a runtime SO can be found in the sample_so hurtle repository, with a detailed explanation of each method in the notify function README file. Below is a summary of what happens at each step of the lifecycle.
Deploy phase
At this phase, the Heat template of a service is deployed on an underlying infrastructure using the Hurtle SDK.
Setting up Monasca Agent on VMs
Remember that we said that a Monasca agent needs to be present on each virtual machine of the application, so the Heat template must contain a configuration script able to install this agent dynamically on each virtual machine as it is created. The agent is setup using the monasca-setup utility using a command similar to:
monasca-setup --username monasca_username --password monasca_password --project_name monasca_tenant --service service_id --keystone_url http://bart.cloudcomplab.ch:35357/v3
Every metric sent to Monasca is authenticated through a keystone token, which is why it is necessary to provide authentication information the agent, so it can use a valid token at all times.
This setup can be done in the user_data section of each Server resources in a Heat template.
Setting up alarms and notifications
The SDK provides helper functions to create alarms and notifications in a single command. First one needs to get familiar with the alarm model used by Monasca, found in their API documentation. An alarm is defined as a threshold based on a specific set of metrics, and has three states: OK (threshold has not been reached), ALARM (threshold has been reached) an UNDETERMINED (no metrics received over a period of time). Here are a few examples:
avg(cpu.user_perc{service=monitoring,hostname=mini-mon})>60avg(cpu.system_perc{hostname=host1}, 120) > 95 times 3The first alarm is triggered when the average of all cpu.user_perc metrics tagged by the service monitoring and the hostname mini-mon received by Monasca over one period (one period is hardcoded to 60 seconds in Monasca) is above 60.
The second alarm is triggered when the average of cpu.system_perc metrics tagged by the hostname host1 over a period of 120 seconds is above 95, three times consecutively.
A commonly used alarm is one which is always OK unless no metrics are received, in which case it goes to UNDETERMINED. This is useful as there is no other way to detect that a monitored system is offline (besides external checks by another system), as suddenly no metrics are sent, it is not possible to trigger an ALARM state, which can only happen if metrics are received by Monasca. The alarm used in our example is:
avg(cpu.user_perc{hostname=host1}) > 200)
Notifications are separate from alarms, by default nothing happens when an alarm is triggered. If the user wants to be notified, he needs to configure his alarm definition with notifications on state changes, for instance when an alarm goes from OK to UNDETERMINED or from OK to ALARM.
A SO developer can use the SDK which provides the function notify to create an alarm and an associated notification in one call. Here is an example:
n_name, n_id = rt.notify('(avg(cpu.user_perc{hostname=rcb_serv_1}) > 200)', 'http://inst1.rcb.cloudcomplab.ch/orchestrator/default', runtime.ACTION_UNDETERMINED)
This creates the alarm and sets up a notification to be sent to the orchestrator if the state of the alarm goes from OK (or ALARM) to UNDETERMINED. The alarm name needs to be unique across all Monasca alarms, so it is automatically generated by the SDK. The SO developer can then store this name and associate it with a specific action. This needs to be saved as it will be used later when the alarm is triggered.
The notification is set to be sent to ‘http://inst1.rcb.cloudcomplab.ch/orchestrator/default’, which in this example is the hardcoded address of the SO. In a real implementation, the SO developer needs to retrieve the dynamic address of the deployed SO, which differs based on if it is deployed on OpenShift v2 or OpenShift v3.
Notification
When an alarm set up during the deploy phase is triggered, a OCCI-formatted POST is sent by Monasca to the SO instance, with a special attribute alarm_name displaying the name of the triggered alarm. This reaches the SO notify method, which can then act based on which alarm name it receives and can choose which action to perform.
Restart a resource with Heat
Using the SDK, the only mean of the SO to modify the deployed resources is through Heat. It can only issue update commands to this end. The issue is that if a resource has disappeared, Heat will not know it as by default it includes no health management capabilities (besides using specific resources); this means that if an update is sent with resources using the same resource names, Heat will simply do nothing. A workaround to that is to create a new resource with a different name, and simply link it to the previous Neutron Port used by the old resource.
For example, take this initial template, to restart the server rcb_si while using the same port, Heat can receive a template similar to this one. The only difference is that the Nova Server resource name has been changed to rcb_si_1.
Dispose phase
In this phase, on top of destroying the deployed Heat templates, all previously created alarms and notifications have to be deleted. The SDK provides the dispose_monasca function for that purpose.
Conclusion
This addition to Hurtle provides what the health management functionality that is required of a full-scale orchestrator, and is very flexible as users have full control over which metrics they send (the monasca agent is completely configurable, and can send any metrics so long as they conform to the common Monasca formatting and are accompanied with a valid token, so any application-specific metrics can be configured on top of typical resource metrics like CPU usage), and can create very diverse alarms.
Current limitations are due to the fact that Monasca is relatively slow to react to events and can not easily be configured with a period below 60 seconds, meaning that alarms are slow to trigger. This is even worse with UNDETERMINED triggers, which can only happen when no metrics have been received for three consecutive periods (180 seconds!).