There is an ongoing debate in the community about the level of awareness (and related to this, influence) an application or SaaS instance should have concerning where and how it is hosted. The arguments range from “none at all”, spoken with a deploy-and-forget mindset, to “as much as possible”, spoken with a do-it-yourself attitude. In practice, some awareness and influence is certainly present, for instance in application-specific autoscaling, self-healing, self-management in general.
One particular aspect in the discussion is about whether an application should know in which cloud environment it is running. Even though the engineer may have targeted a specific stack with project conventions, there may be migrations between several instance of the same, e.g. different installations of OpenShift, Cloudfoundry or other stacks to run cloud applications, across regions or even across providers. Already some time ago we looked into identifying the level of virtualisation in a nested virtualisation context. Now we complement this vertical view with a horizontal one. This blog post does not argue for or against cloud provider identification; it merely describes a tool to gain this knowledge and exploit it in any possible way. The tool is called whatcloud.
An application running in the cloud has two sources of provider identity sourcing: Internal, e.g. through special files similar to what virt-what does for hypervisor detection; and external, through network characteristics. Whatcloud is running as a service and therefore uses the network location a.k.a. outbound IP address of the provider for the determination.
The workflow is simple: An application performs a GET request on the whatcloud service and receives either the name of the provider or an unknown status back. The service consults a database which is curated manually by performing the same request in known provider configurations and entering the network information. One simple pingwhatcloud tool for the curation is available for easy OpenShift deployment or standalone use under the name peeraddress. The quality of the database is currently rather low, both in terms of completeness and of accuracy. A crowdsourcing attempt to complete and verify it will help to raise its quality.
The following figure explains the workflow.
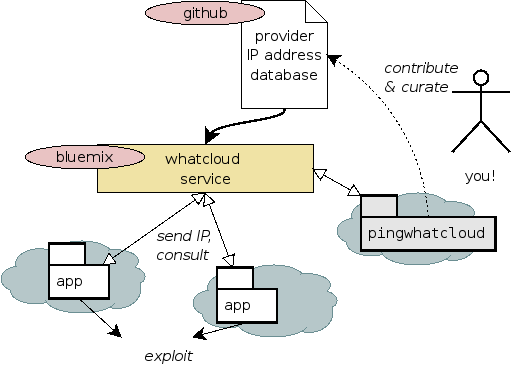
Whatcloud including the database is published in a dedicated Git repository. The tool is furthermore running online hosted as a Cloundfoundry application at Bluemix.
Apart from the possible exploitation of the knowledge, the implementation of whatcloud has led to interesting insights into the limits of cloud application development. The runtime environments isolate the application to a varying degree. While a first idea has been to prototype whatcloud as a hosted function, none of the FaaS executors seem to provide any identification of the caller identity. On the PaaS level, some application servers do (e.g. through environment variables) but not all and not in a uniform manner. Another interesting point is that several disjoint regions of cloud providers share the same subnets. It is not clear if there is always some magic network-foo behind or if the regions are merely placeholders for future data centre expansion.
The topic also tangents the definitions of cloud-enabled and cloud-aware application designs. Further discussion about the self-awareness of a cloud application is provided in a recent open access article published on arXiv. Ten problems which may benefit from self-awareness are mentioned, among them recovery planning, autoscaling, performance isolation and discovery of application topology. Judging by the findings of this article, the debate on the level of awareness will continue. The open challenges raised by the authors encompass the extent of self-awareness which is necessary for cloud applications (to which we could add: is desirable), and how self-aware computing can learn and maintain this knowledge across releases.
For the time being, we consider knowledge of the provider as practical first step in this direction. We are curious to see if anybody uses whatcloud and for which purpose and encourage contributions to the network database. Just fork and push your suggested changes.