Among the lectures offered by the Service Prototyping Lab is Scripting. Aimed at students of advanced studies, it teaches essential practical programming skills and conveys approaches how to automate the exploration of data retrieved from the Internet. Python is taught as programming languages and consequently a Python (Django) web application has thus far been used to automatically score the results submitted by students of a particular advanced task towards the end of the lecture. There’s nothing wrong with Django per se, but its roots have evidently been in the era of monolithic web applications. Armored with our Function-as-a-Service experience we decided to drop it and go purely serverless. In production.
Production services in a teaching context refer to services whose downtime is not affordable due to ensuing complaints by students. Therefore, we needed a solution which combines awesome FaaS features with reliable operation. Despite our ongoing research on FaaS runtimes such as Snafu, we took a step back and opted for Apache OpenWhisk instead. It is not only one of the more advanced systems, but also available as a production installation branded as IBM Cloud Functions integrated with the Bluemix PaaS. The upfront constraints on this platform include a maximum function execution time of five minutes paired with a maximum memory allocation of 512 MB and a maximum HTTP POST (submission) size of 1 MB. These constraints enforce either small service implementations or a decomposition into microservices.
Python is among the programming languages natively supported by OpenWhisk, along with Node.js, PHP and Swift, while others are supported indirectly through Docker containers. One of the more compelling features of OpenWhisk is the ability to execute functions as web actions. By signalling specific keys in the response JSON structure and invoking the action through the HTML multi-views handler, the associated HTTP controller renders the JSON instructions into HTTP headers and HTML body. This way, web applications with page transitions can be engineered as user-facing functions.
The nature of FaaS calls for stateless services. State needs to be offloaded to non-local file systems or, more commonly, databases offered as a service. In practice, however, the containers isolating function instances are not immediately disposed. Instead, they stay around for a (non-guaranteed) amount of time. This behaviour has been observed with most major providers. According to our own preliminary observations, IBM Cloud Functions lets function instances survive for ten minutes. The probability of thirty students in a lecture unit of 90 minutes leading to a ten-minute period without submissions is rather low. (A back-of-the-envelope calculation suggests that following the generalised birthday problem, the probability of not at least two students submitting once at the same minute is less than 1%.) For an application such as ours in which keeping the state from previous invocations is sort of a non-necessary fun feature and losing everything older than a few minutes is acceptable, an opportunistic handling of state within the function container instance is absolutely fine and leads to an extremely simplified setup with just a single function file as entire service implementation. And for everything else, there are heating pads to keep function instances warm which can be deployed easily on top.
Hence, our implementation of the cloud function service named Titanic due to the student task of submitting results related to datasets which describe survivors from the sinking ship. When the function is invoked without application-specific parameters, the initial web form is rendered. It asks for two parameters, a CSV file and a unique identifier.
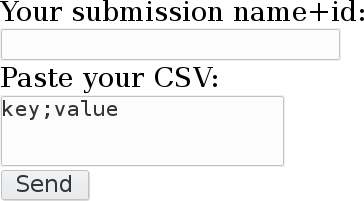
Once the button is sent, the function is invoked again, this time with additional parameters in the input JSON structure. Subsequently, it branches out into the calculation of the score, its insertion into a local score file (if it exists in the current instance), and the reading and in-memory sorting of the same file. The sorted scores are then shown as second web screen as leaderboard. Students with the highest score have achieved a vectorised prediction closest to the actual results.

The score calculation requires a reference CSV file. As the OpenWhisk model does not foresee the inclusion of (read-only) files, in contrast to the typical application server model, the Titanic function implementation contains the file contents as base64-encoded blob structure.
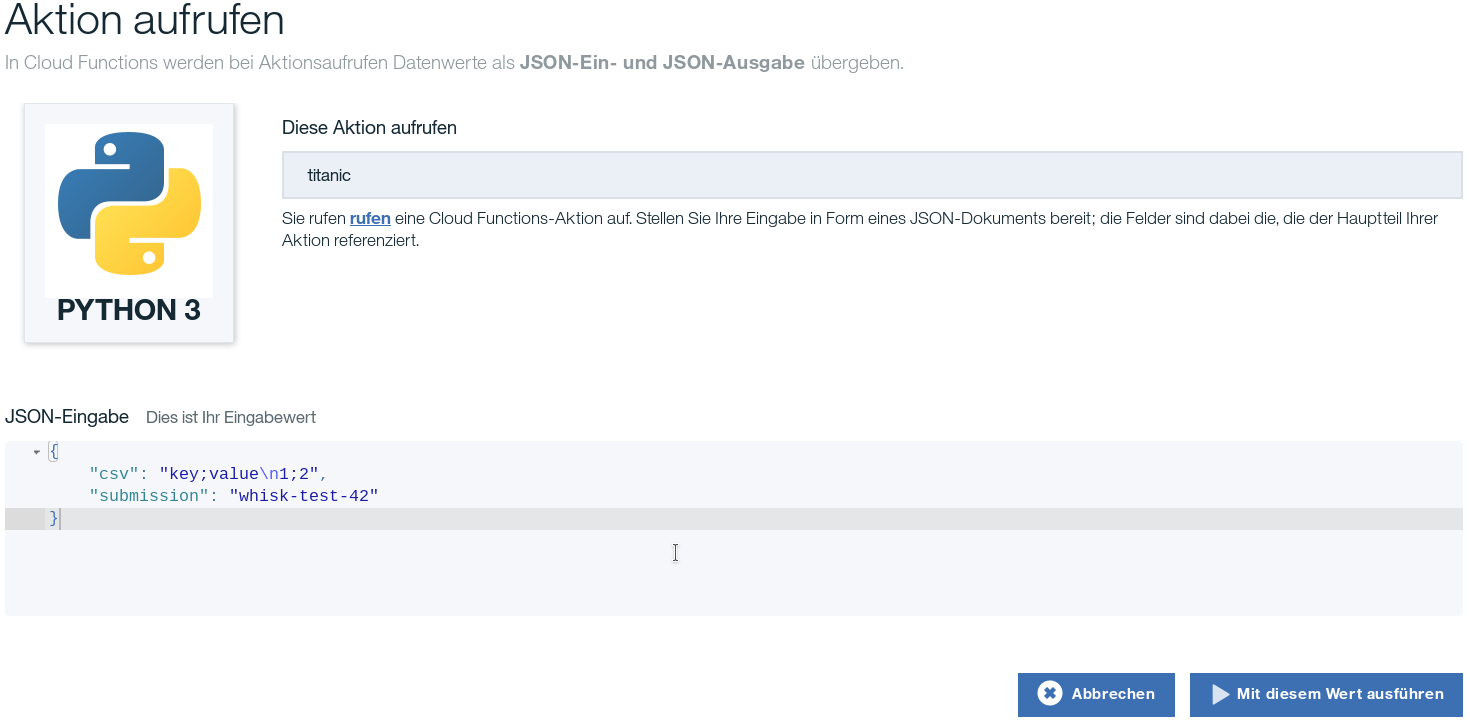
It is straight-forward to test the function by pasting its code into OpenWhisk and setting up an appropriate test request. The screenshot below shows a suitable JSON structure which corresponds to manual input from the web form.
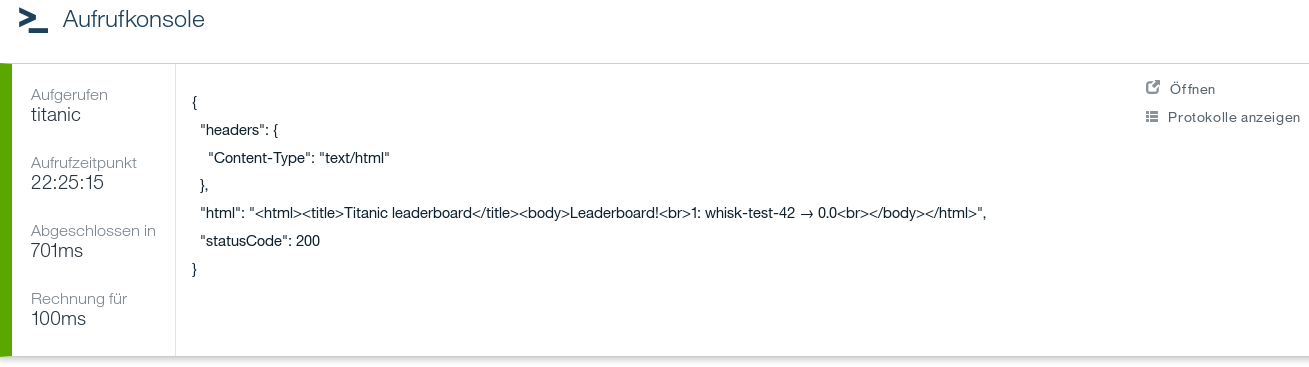
 The next screenshot demonstrates the performance of the function. As it obviously does not perform a lot of calculation, a true pay-per-use (per invocation) occurs. The net invocation time is less than 100ms and we are charged for a tenth of a second, accordingly.
The next screenshot demonstrates the performance of the function. As it obviously does not perform a lot of calculation, a true pay-per-use (per invocation) occurs. The net invocation time is less than 100ms and we are charged for a tenth of a second, accordingly.
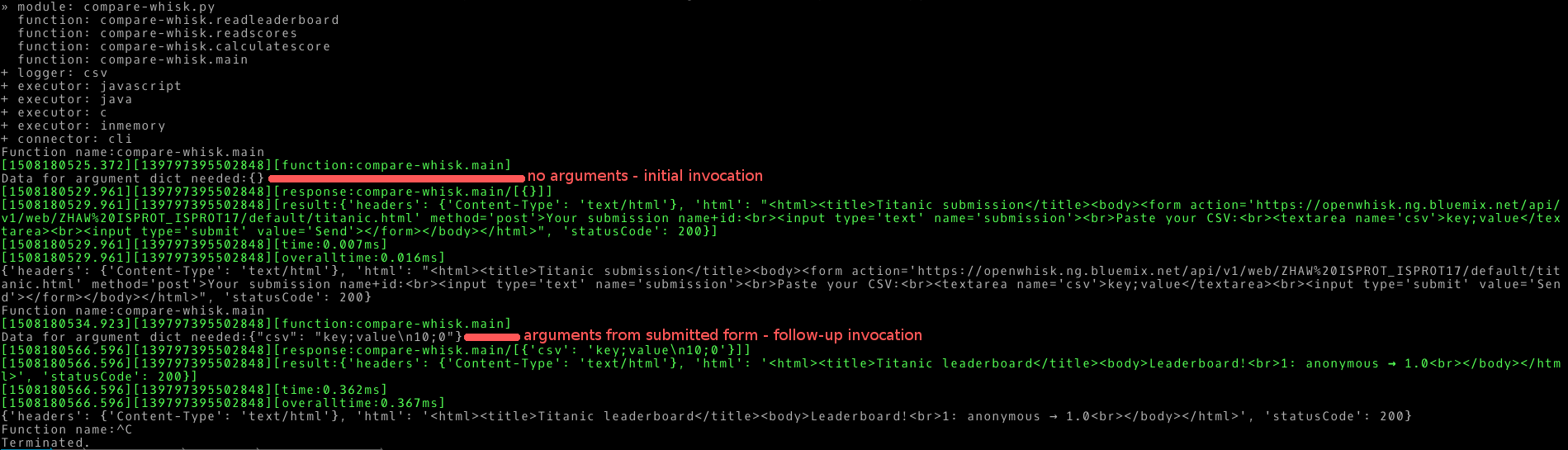
 As no state will accumulate over a larger time, we currently operate the function without any authentication. Despite choosing OpenWhisk for the hosted instance, of course the function execution itself works with Snafu and can be further tested with it. The addition of a web page renderer would be a possible future engineering work.
As no state will accumulate over a larger time, we currently operate the function without any authentication. Despite choosing OpenWhisk for the hosted instance, of course the function execution itself works with Snafu and can be further tested with it. The addition of a web page renderer would be a possible future engineering work.
 We are glad to have built a solution which accommodates our educational needs and furthermore strengthens the direct transfer of research results into education. One open question remains: Which other university runs serverless in production?
We are glad to have built a solution which accommodates our educational needs and furthermore strengthens the direct transfer of research results into education. One open question remains: Which other university runs serverless in production?