As part of our weekly Cyclops release, RCB team releases a significant feature this week – we announce the Prediction Microservice integration in Cyclops. With this integration, Cyclops will provide simple forecasting of usage and will predict future values. The service could be used as for customers to predict their own cost and as to cloud provider to predict revenues.
Newly created prediction microservice has machine-learning capability and has been designed to predict values based on historical data. It is also capable of generic factual forecasting by encapsulating mllib as a prediction engine. The prediction microservice queries both UDR and RC services which are parts of Cyclops project to get the Usage Data Record and Charge Data Record of a user, respectively for user perspective. For an admin, the data records of a recourse will indicate the entire overall consumption and not just individual user’s consumption. To predict the values of resources, mllib is used to provide multiple algorithms support along with machine-learning capability.

The prediction engine is deployed over Apache Spark engine which contains a scalable machine learning library(mllib). As a package for engine development spark.ml is used to provide high-level APIs built on top of DataFrames. DataFrame is a collection of data organized into named columns, and is distributed by Apache Spark.
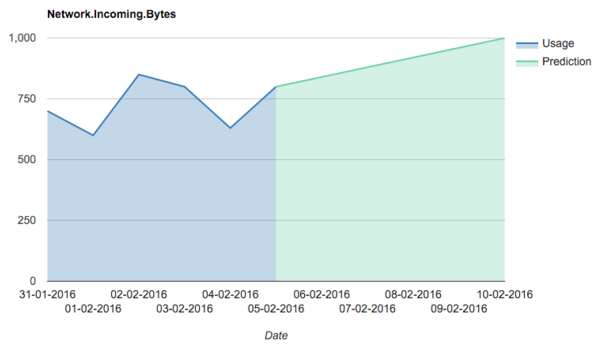
As endpoint parameters, “days before” and “days to” should be defined. When a request for the prediction is made by a dashboard through an API to the prediction service, the service collects all necessary user’s data records for the requested “days before” number. An anchor current timeline point is used. The service looks back for the selected number of days to add a degree of customizability for the users. As a prototype, a Linear regression model is selected. Linear regression is a simple algorithm already implemented in mllib but first of all it has to be created, as shown below.
As soon as linear regression is defined, the data record can be transformed into a valid spark data and can be used as training data for the predicting model. All future predictions will be forecasted due to this dependency.
At this point the Regression model is ready to transform data. For the same reasons mentioned above “days to” is needed to get a list of time points from current timestamp to define the number of days for which the values should be predicted and are called features. ![]()
The trained model is fitted with these features and as an output it returns data with new predicted values based on the past training data. The model returns predicted values for defined features as a response back.
Currently, only linear regression has been implemented for the microservice but this implementation doesn’t include seasonality, for that we need exponential smoothing methods such as Random Forest. Random Forest can discover more complex dependencies, but will take more time as compared to what Linear Regression would. If variables have a linear dependency, similar results will appear for both algorithms. Due to the usage complexity of Random Forest (especially, with wrong regularization parameters) as compared with that of regression’s, there are no reasons to use it if variables have a linear dependency. But, if the dependency is different from linear, linear regression could prove to be of little use. To make the decision of choosing an algorithm, it is necessary to define the dependencies and select what model would fit better and as a resultant get more accurate predictions.
The RCB team will be adding more features to the prediction microservice over the next couple of weeks, so stay tuned!