In the European services and cloud computing research community, the International Conference on Cloud Computing and Services Science (CLOSER) has been a meeting point for academics and applied researchers for almost a decade. This year, CLOSER 2018 took place in Santa Cruz at the Portuguese island of Madeira. As for any commercially organised conference series, there are certain expectations for how well the conference is run, and there is a lot to learn for us to drive community-organised conferences and to sense the participation in cloud conferences in general. On the technical side, we presented an international collaboration work at this conference, and we dived into the respective works of others. This blog post reports about our interpretation of both the organisational and technical aspects of CLOSER 2018.

According to the opening session remarks and the booklet containing the programme and the abstracts of all papers and talks, CLOSER 2018 had received 94 submissions from 33 countries from which 21 full papers were accepted along with 28 short papers and 10 posters. In addition, 4 keynotes set the spirit throughout the conference. The attendance of the opening did initially not quite match these numbers but the culprit was the stormy weather and within several hours, as all delayed flights arrived, the participant crowd grew quickly, including also industry representatives without a paper. CLOSER was run in parallel with IoTBDS which allowed for interdisciplinary discussions during breaks on topics such as big data and IoT/cloud integration.
The opening ceremony was followed by a panel, moderated by DCU’s Markus Helfert, and staffed with Michael Papazoglou (Tilburg), Tobias Hoellwarth (EuroCloud), and Claus Pahl (Bolzano). Each panelist presented views on general cloud computing topics under the general theme of Cloud and Service Computing in the 2020s which offered a nice perspective for research beyond the current European Horizon 2020 calls. The first presentation advocated for smartness in the sense of unobstructed service visibility, optimised use of resources, coordinated responses and modular solutions among other characteristics of future complex (cloud, hybrid cloud-physical, cyber-physical) applications. The presentation also presented requirements for smart data defined as normalised, conflict-free and homogenised data which is first contextualised and later orchestrated. The second presentation countered with a pessimistic view, stating that the technologic progress is too fast for the society at large because the political and legal frameworks as well as education cannot keep up anymore. 99.999% of the people would not understand any of the technical conference talks, while at the same time, specialists are needed in the light of a dry market for know-how especially in Europe which presents a massive problem, and a fundamental and unavoidable flume into future technical debt. Still, SMEs can use cloud-driven opportunities to challenge big companies through a clever use of the resource potential, but often they will not do it. The last presentation motivated to look forward beyond current cloud, edge/fog and things frameworks such as FIWARE. According to the presenter, until the year 2020 we can expected 26 billion connected devices with 1.6 ZB of collected data. An architecture sketch across five layers (sensors/actuators, monitoring/control, ops support, business support and enterprise systems) was proposed.
The discussion first clarified that research in cloud computing often falls flat of practical impact less because of direction issues but more due to unsuitable timing. On the academic side, more awareness of actual problems needs to be fostered, while on the industry side, CIOs and other decision-makers must be freed from project overload to be gain time for interaction with researchers. New business models such as one-stop-shop service integrators with full incident handling responsibility across complex compositions need to be embraced. And on the education side, while specialised deep lectures are important, interdisciplinary thinking needs to improve so that engineering students and business students can talk to each other and carry this ability over into their professional careers. An interesting remark mentioned the “ISO stickers are enough” syndrome while in reality cloud providers need to address uncertainties from users, including application providers, to make the ubiquitous cloud a reality.

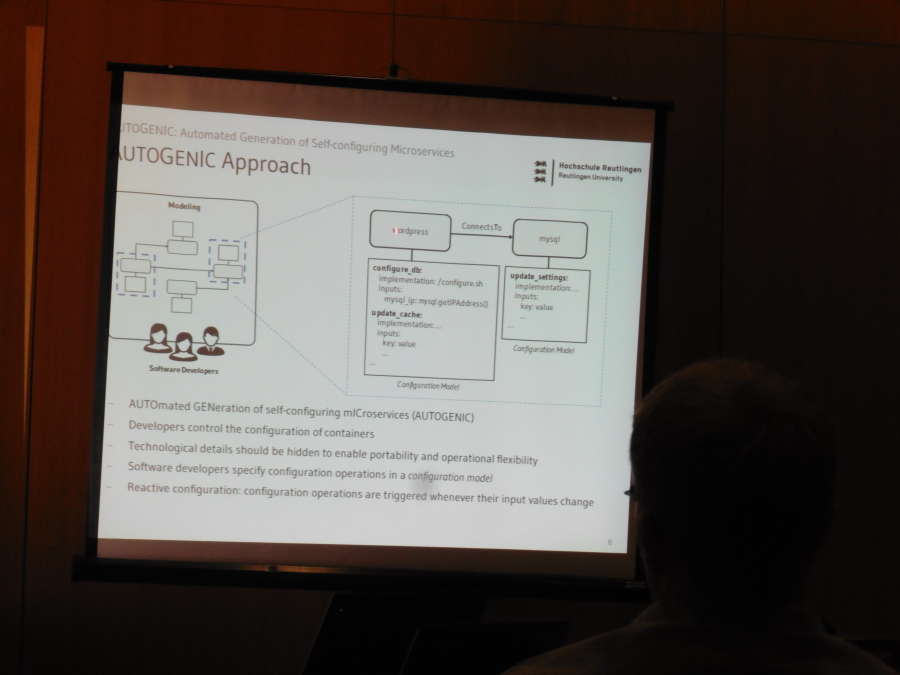
After the panel, the first technical session started in two rooms in parallel. In one of the rooms, the session had presentations on testing, automated creation of management artefacts for container compositions, and trusted distributed processing of genetics data. Testing was analysed specifically for user acceptance testing for multi-tenant cloud applications using the iCardapio application on Heroku as test case. Several typical web faults were detected but cloud-specific fault types would require more work. The paper on automated generation of self-configuring microservices is highly relevant to our ongoing research on cloud-native applications in which we have for a longer time focused on self-management capabilities of the constituent microservices and of the application as a whole. Templates and hooks were proposed to make compositions more manageable and TOSCA was used to evaluate the work. The discussion touched on mechanisms to reduce image sizes and on the semantic equivalence to the assisted semi-automated code and template generation for operating system packages. In the third talk, trusted processing through intermediaries was proposed for outsourced data processing scenarios involving potentially fragmented and encrypted data. The paper approach had some remarkable similarities to our previous work on stealth databases in the cloud.
The first day keynote followed, linking disconnect between technology and people to social unrest and socio-economic revolution. The analogies given included the 19th century revolt against manufacturing of textile works, and the signs of a repeat were found in the current political world climate which focuses on daily ramblings instead of preparing for the massive technological shift which requires profound changes in education and valuation of technical work. Science for its part must become more understandable and policymaking needs to be temporally aligned with progress as the speaker already mentioned in the panel discussion. For instance, cloud providers and consumers need to be more rigidly expressing their requirements and guarantees. SMAC, or social media/mobile, analytics and cloud, is the keyword to express most of the force behind the overall shift which is already happening.
The second session focused on fog and edge computing scenarios. According to one presenter, fog computing is required to support the IoT momentum due to the shortcomings of traditionally centralised cloud architectures. However, the terminology around fog computing including also foglets has not yet settled. A holistic analysis including previous decentralised approaches such as user-controlled personal and hybrid clouds still remains to be seen as well. According to another presenter, latency experiments in edge computing scenarios become more widespread. But the experiments need to be carefully designed and, as one participant noted, the presented paper simulated using random latencies instead of a more sophisticated approach using real cloud data center traces.
In the third session, cloud-native applications and microservices were in the focus. Our joint work with Itaipu Technology Park about a first systematic approach to cloud-natify SaaS applications was consequently placed into this session. Two discussion points arose after the talk. First, as we outlined weaknesses in Docker’s resilience, Kubernetes obviously offers a lot more health checks, metrics and self-awareness. Yet, our take is that if Kubernetes runs containers through Dockers, then any reduced resilience of the platform propagates up the stack and into the application itself. Second, there was a clarification question about whether the Docker weakness is for real, which we affirmed with code and data.
Other talks in the same session included another (DMS-related) application migration case study, an analysis of the advantages and disadvantages of microservices through a systematic mapping study and a nice timeline, and an approach for remote debugging of applications in the cloud on a variable tracing level.

On the second day, among the more interesting and thought-provoking talks was a benchmark of Tensorflow provisioned through OpenStack on bare metal versus virtual machines with Kubernetes running Tensorflow in containers. The differences in resource utilisation, saturation and bottlenecks were highlighted, and obviously overall the technical perspective favours bare metal whereas the cost perspective, which was not considered in the paper due to looking at a private cloud deployment, would favour virtual machines. Interesting technical details such as the double network abstraction (Flannel and hypervisor) were discussed and the emerging OpenStack project Kuryr was mentioned as potential improvement. The author maintains the view that providers should indeed optimise the VM provisioning, although a different perspective is that bare metal will never completely vanish due to many advantages despite the cost. Therefore, cloud providers could offer provisioning options where the same service (Tensorflow, Hadoop, Kafka, …) would be offered on bare metal, in a VM, or in a container composition, with differentiated pricing and technical characteristics for each. This model would contrast current tightly-coupled PaaS offerings and would justify additional research on the economic side and on potential use cases.
The second day keynote focused on “New Cloud” offerings around edge computing, serverless computing, distributed cloud computing, while mostly excluding fog computing ideas due to them not being concretely enough defined yet. A major take-away was that while in current centralised clouds there are four major players, the stage is still empty for assembling the next big four on the edge. From a user perspective, new cloud offerings could become intriguing considering the current maze to go through before being able to decide on a simple virtual machine setup, let alone a more sophisticated combination of services. Deterministic predictability of performance and other technical characteristics is thus still on the waiting list of many paying cloud customers.

The third day had more interesting talks starting with optimising the cost-performance ratio with mixing differently sized and prized virtual machines and on PacificClouds, a multi-cloud framework for microservices which comes with its own custom definition of what a microservice actually is. Related, University of Padova researchers presented a state-of-the-art review of current microservice technologies, focusing on dynamic orchestration. Another cloud migration talk was given on the subject of seat reservations in trains, a production system with around 300000 requests per day. The concept divided the overall system into four layers: application, compute (e.g. EC2), encapsulation (e.g. Docker images, Weavenet overlay networking) and deployment (e.g. Kubernetes). Interestingly, while migrating the application over the period of around two years, the technologies have changed quite a bit and another modernisation effort could start right away with container-native hosting, bypassing the need of VMs. This topic was also reflected in the discussion following another talk on multi-level autoscaling, e.g. pod-level, cluster-level, VM-level.
The third and last day keynote delivered a broad overview about smart manufacturing in the context of the 4th industrial revolution based on the use of cyber-physical systems. It picked up a definition of smart products which are aware, intelligent, connected and responsive, and motivated the definition of cloud-centric manufacturing in which tools are shared resources and are offered as a service. Digital twins can assist in transforming plants into this direction. An interesting data point was given from a car manufacturer who processes 13 billion data samples per day, way up from a single billion which was considered big around five years ago.
Overall, the conference participation at CLOSER 2018 was well worth the time investment. It was also enjoyable due to properly chaired sessions and a convenient floor and schedule layout. Due to parallel sessions, not all tasks could be enjoyed by a single attendee, but the proceedings are going to be soon available in the SCITEPRESS and ACM digital libraries, albeit without flexible author rights as is now possible for ACM publications. As an update channel on recent achievements and a meeting place for researchers, the conference has fulfilled the expectations. And for cloud technology enthusiasts, the conference location, Santa Cruz, shall become forever known as the historic place which had Kubernetes logos on the sidewalk long before Kubernetes was even invented.
