For reliable, user-controlled and trustworthy file storage in the cloud, free software prototypes like NubiSave have become great tools to investigate and lift the barrier towards acceptable migration paths. For structured data storage and processing, several approaches to database-as-a-service (DBaaS) have been proposed by researchers and developers but a clear recommendation of how to best manage rows or records of data in the cloud from a practicality angle is still absent. Partially, the question about how to do this is due to the different pricing structures and availability guarantees by the providers which are not trivial to compare. Often, running the database system as set of replicated or sharded containers being part of the application appears to be a valid alternative to the binding of existing commercial DBaaS, if done correctly. After all, cloud providers would offer the same technical guarantees for any of their services. An analysis of which configuration works better and is less expensive would thus be needed.
On a more abstract level, this leads into a conflict which we’re going to see a lot more in the future: Should we build DIY solutions on top of IaaS, or should be buy into whatever is offered by the PaaS? This question cannot be answered for all services at once. But right now, it is especially pressuring for data processing applications, and in particular for many applications using a plain database management system.
CNDBbench to the rescue. This cloud-native database benchmark application, while still under development, offers a systematic way of checking how to manage data from your cloud application which ideally is already built in a cloud-native way.
The figure below shows the basic working modes of CNDBbench. It builds (using docker build) benchmark containers specific to database interfaces (SQL, JSON) and deploys them in different combinations locally and in the cloud. Either readily provided database services or benchmark-controlled instances (single or clustered) are used. The containers can again be hosted either in the provider’s own container engine-as-a-service, or (due to still many issues with this variant) inside a kubernetes instance on a plain old virtual machine.
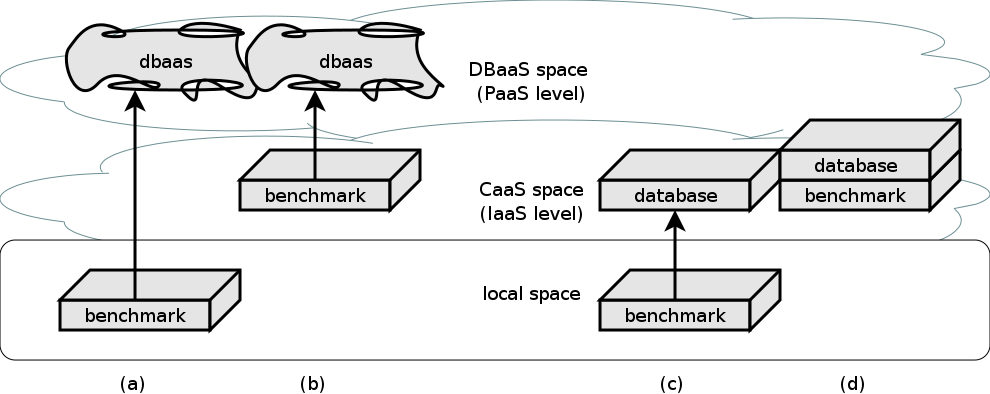
Currently, CNDBbench supports five relational, document-oriented and hybrid database systems: MySQL, PostgreSQL, MongoDB, CouchDB and Crate. Furthermore, it supports the equivalent DBaaS interfaces like Aurora. To follow a single-source dataset approach, a conversion from the source format into the destination format (as tuples or nested structures) is performed.
Hence, CNDBbench uses docker-compose to build the composite benchmarking suite, consisting of (1) the specific benchmark container, (2) a read-only reference dataset container, (3) a writeable results container, and (4) optionally the database system container(s). Each check is repeated a number of times to eliminate sporadic outliers. The results are written as portable CSV files which are then plotted into diagrams with gnuplot. Knowledge gained from the graphs includes the absolute times to perform database operations, the relative stability (inverse deviation) of measurements, and the uninterrupted behaviour of the overall system in the presence of (provoked) faults.
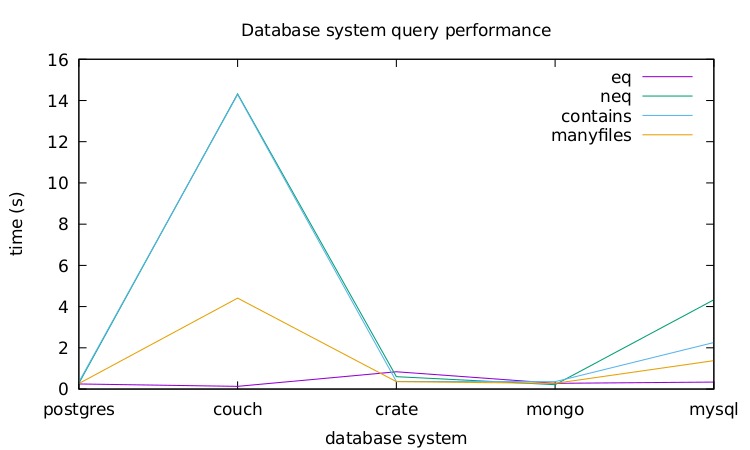
The following figure offers a first glimpse at measurements produced by CNDBbench. Four queries are run which execute in comparable times with most systems but diverge a lot with CouchDB.
You can fetch the code to CNDBbench from its Git repository as with all other software created in the Service Prototyping Lab. A scientific paper about the system is being written and will be submitted to a matching conference soon.