In our previous work we presented the performance of live migration in Openstack Icehouse using various types of VM flavors, its memory load and also examined how it performs in network and CPU loaded environment (see our previous posts –performance of live migration, performance of block live migration, performance of both under varying cpu and network load). One factor which was not considered in our earlier work is the impact of VM ephemeral disk size on the performance of the live migration. That is the focus of this post.
In the following experiments, then,we simply increased disk usage by consuming more of the disk capacity and observed how it affects both block live migration (BLM – disk migrated via the network) and live migration (LM – using a shared file system between computing nodes).
As described in earlier posts, our Openstack setup uses 1 controller and 2 compute nodes connected with 1G Ethernet LAN network.
Our first observation was that VM disk capacity itself (as defined by the flavor) doesn’t significantly affect live migration performance. Rather, what impacts the performance is the amount of data (somehow) allocated on the filesystem. Unallocated disk space is not migrated at all, but once the VM makes any filesystem allocation of any bytes of its disk, these bytes will be migrated irrespective of whether the original file still exists or not. Clearly, this means that freshly spawned VMs with different disk capacities will migrate in the almost same time, because they allocate approximately the same amount of data on the filesystem – e.g. freshly installed Ubuntu Server 14.04 LTS uses approximately 800 MB of disk space. Since we haven’t generated any additional data except the OS in any of our previous tests with 5 GB ephemeral disks, those results can be generalized for freshly spawned VMs with larger disks as well.
The following paragraphs describe performance of LM, BLM and their comparison with increasing disk usage. Migration time values were obtained from nova-all.log file. Downtime is the time period during that migrated VM doesn’t reply to ping echo requests. Transferred data is amount of data transferred via network from source to destination host (measured by iftop).
Block Live Migration
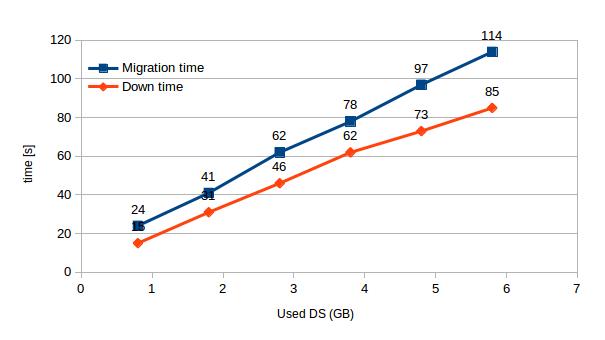
In the case of BLM both the migration time and downtime increase linearly with disk usage. The downtime is over 70% of the migration time in most of the cases. We observed that on average each 1 GB of used disk space results in an increase in migration time of 18 s.
| Used DS [GB] | 0.8 | 1.8 | 2.8 | 3.8 | 4.8 | 5.8 |
| Migration time | 24 | 41 | 62 | 78 | 97 | 114 |
| Down time | 15 | 31 | 46 | 62 | 73 | 85 |
[Table 1 – BLM migration & down time with increasing disk usage]
Live Migration
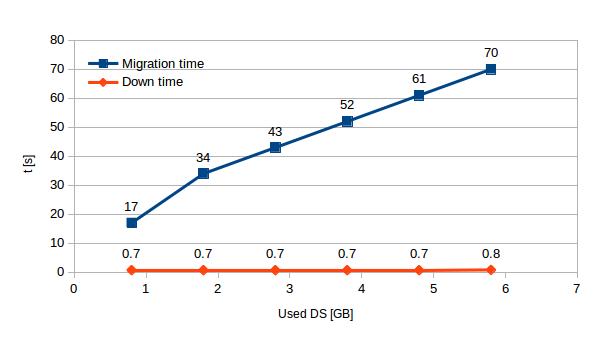
In the case of LM the migration time also increases linearly with disk usage. The down time, in contrast with BLM, stays permanently less than 1 s in every single testing scenario. In our case the LM duration increases on average by 9 s per 1 GB of used disk space.
| Used DS [GB] | 0.8 | 1.8 | 2.8 | 3.8 | 4.8 | 5.8 |
| Migration time | 17 | 34 | 43 | 52 | 61 | 70 |
| Down time | 0.7 | 0.7 | 0.7 | 0.7 | 0.7 | 0.8 |
[Table 2 – LM migration & down time with increasing disk usage]
Comparison of LM & BLM
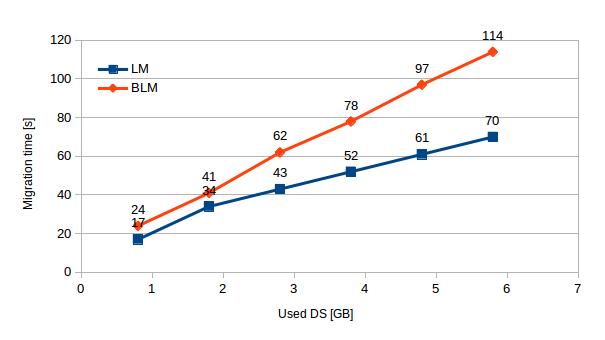
In all tests LM is faster than BLM. This difference increases from 41% (0.8GB used disk space) to 62% (5.8GB used disk space). According to chart 3 this performance gap will grow even more with increasing disk usage. A VM with no additional files was migrated using BLM in 24 s and in 17 s using LM. With 5GB of additional files the same machines were migrated in 144 s (BLM) and 70 s (LM).
| Used DS [GB] | 0.8 | 1.8 | 2.8 | 3.8 | 4.8 | 5.8 |
| LM | 17 | 34 | 43 | 52 | 61 | 70 |
| BLM | 24 | 41 | 62 | 78 | 97 | 114 |
[Table 3 – Comparison of migration times of BLM and LM with increasing disk usage]
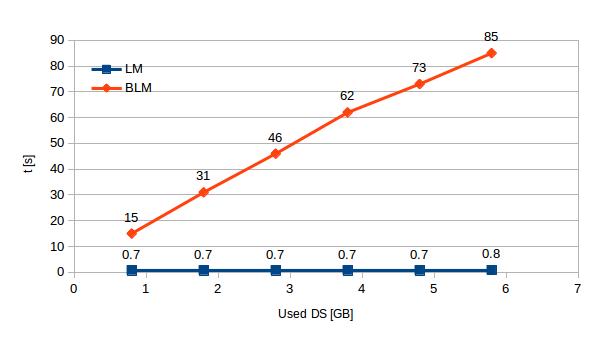
We’ve already seen that LM downtime does not increase no matter what the VM / environment load. Now we also see, that not even the different disk usage affects this value, which stays below 1 s. In case of BLM the down time increases from 15 s (0.8 GB of used disk space) to 85 s (5.8 GB of used disk space).
| Used DS [GB] | 0.8 | 1.8 | 2.8 | 3.8 | 4.8 | 5.8 |
| LM | 0.7 | 0.7 | 0.7 | 0.7 | 0.7 | 0.8 |
| BLM | 15 | 31 | 46 | 62 | 73 | 85 |
[Table 4 – Comparison of down times of BLM and LM with increasing disk usage]
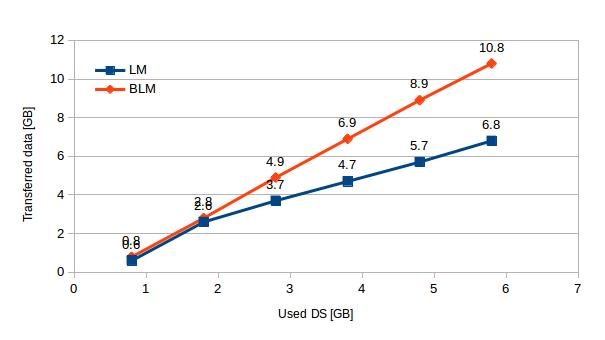
Not surprisingly the amount of transferred data grows with higher disk usage. More interesting is the fact that BLM transfers in average 1GB of data with each consumed 1GB, while BLM transfers twice as much data per one used GB – 2 GB transferred / 1GB consumed (it’s obvious that considerable amount of these data is duplicated). See chart 5 to compare amount of data transferred via the network with different disk usage.
| Used DS [GB] | 0.8 | 1.8 | 2.8 | 3.8 | 4.8 | 5.8 |
| LM | 0.6 | 2.6 | 3.7 | 4.7 | 5.7 | 6.8 |
| BLM | 0.8 | 2.8 | 4.9 | 6.9 | 8.9 | 10.8 |
[Table 5 – Comparison of network transfers of BLM and LM with increasing disk usage]
Take aways
- BLM takes approximately 18 s and transfers 2GB of data via the network per 1 GB of used disk space while LM takes 9 s and transfers 1GB per 1 GB. Note that migration time strongly correlates with amount of transferred data, thus it also depends on network bandwidth.
- LM’s downtime doesn’t increase with VM used disk space and stays < 1 s. BLM’s downtime increases linearly by 14 s per 1 GB of used disk space.
In previous posts we presented certain limitations of LM concerning migration of memory stressed VMs. In contrast, LM dominates for migration of memory unstressed VMs with high disk usage – it provides significantly lower migration time, almost no downtime and less network traffic than BLM.
Hi,
When you use stress tool, how you use that? I mean you always keep dirtying the memory with “–vm-keep” command or just just use “stress –vm 2 –vm-bytes 1G” ? As if stress keep the memory then its almost stuck at the migrating task.
Thanks for your comment.
Hi, this post focuses on how the ephemeral disk usage (in terms of statically allocated disc space) affects the live migration. This time we haven’t used stress tool for RAM memory allocation.
But to answer your question – We haven’t noticed much difference between using –vm-keep parameter, since only difference is, that stress with vm-keep paramaterer allocates memory only once and then re-dirties the same allocated memory over and over while stress without vm keep allocates and unallocates memory before it write into it. However, as you can see in previous post we were able to successfully live migrate VMs with approximetelly up to 100MB stressed memory. I don’t wonder your migration stucks since you are trying to migrate VM with 2x1GB dirtied memory.
BR.
Hi,
Thanks for the clarification. But I am using this stress command for block live migration. According to your blog, for block live migration we can dirty memory until 75%. But this is not the case for me. I cannot allocate even 25% memory for stress in block live migration.
May be this is the wrong question for this post. But I am really curious to know how you achieve block live migration with 75% dirty memory.
Thank you for this article, however, I don’t understand why in live migration (where storage is supposed to be shared) there is disk transfert over the network?