Previously, we analyzed the performance of virtual machine (VM) live migration in different scenarios under Openstack Icehouse. Until now, all our experiments were performed on essentially unloaded servers – clearly, this means that the results are not so widely applicable. Here, we analyze how the addition of load to the physical hosts and the network impacts the behaviour of both block live migration (BLM) and live migration (LM). (Note that the main difference is that BLM migrates the VM disk via the network while LM uses shared storage between source and destination hosts and the disk is not migrated at all).
We loaded the systems with:
- Server CPU load – stressing the physical hosts in terms of CPU usage. This was done by deploying additional loaded VMs at both hosts. We used top / htop tools to monitor the increased CPU load
- Server network load – by adding additional network traffic at network interface which was used for migration. We generated high amount of ICMP packets using the ping tool and we used iftop and nload tools for network traffic monitoring.
All the loads were generated explicitly by systems which were external to the instance which was the subject of the migration. To achieve consistency with the results obtained in ourearlier work we focused on a VM with following specifications for all tests: 8 VCPU, 16GB RAM, 5GB disk.
Impact of system CPU load
In our case both computing nodes had 24 VCPU cores (2 x 6 core Intel Xeon E5-2640 with hyper-threading technology). For the full system specification see our previous blogpost.
We added an artificial load to the both physical hosts which resulted in a processor load of 66% – 16 VCPU 100% loaded (out of 24). The LM time increased modestly from 15 s to 18.3 s ( >20%) and from 22.5 s to 25.1 s (>11%) in case of BLM.
It is worth noting that during the migration period itself, we observed a 50%-80% load on one of the CPU cores.
Impact of system network traffic
All our servers run on a 1GbE network – we obtained throughputs of 930 Mbit/s from one server to another without any particular tuning effort.
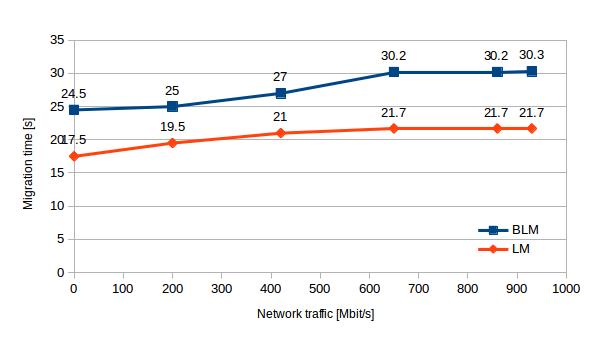
Here we present results which show how migration time varies with increasing network traffic. For both LM and BLM we observed a 24% increase of migration time as we increased from no load to heavy load. The mean LM time increased from 17.5 s to 21.7, while BLM time increased from 24.5 s to 30.3 s. On average, with increasing network traffic, the LM was 36% faster than BLM.
We observed that even though we generated artificial traffic consuming all the capacity of the interface used for migration, migration traffic was prioritized resulting in a decrease in the amount of artificial traffic that was carried on the interface.
| Network traffic [Mbit/s] | 0 | 200 | 420 | 650 | 860 | 930 |
| BLM | 24.5 | 25.0 | 27.0 | 30.2 | 30.2 | 30.3 |
| LM | 17.5 | 19.5 | 21.0 | 21.7 | 21.7 | 21.7 |
Table 1 – BLM and LM performance with increasing network traffic
In earlier work, we saw that VM memory load has a significant impact on migration performance; hence, we performed experiments in which we varied the amount of VM memory load to determine how network traffic impacts migration performance.
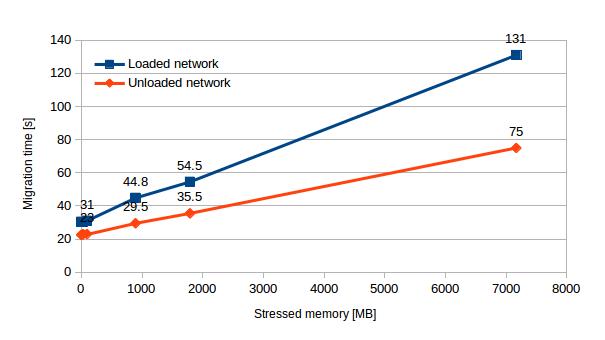
BLM didn’t exhibit any problems and we successfully migrated VMs up to more than 7GB of stressed memory. In all tests BLM performed worse in the presence of network traffic than in the unloaded case. This difference between both network scenarios is 35% in case of unloaded instances and 75% in case of highly loaded instances. See Chart 2 to have a better idea of thelinear increase of migration duration in both network traffic scenarios using BLM.
| Stressed memory [MB] | 0 | 16 | 32 | 96 | 896 | 1792 | 7168 |
| Loaded network | 30.3 | 30.3 | 30.2 | 31 | 44.8 | 54.5 | 131.0 |
| Unloaded network | 22.5 | 22.5 | 23.0 | 23.0 | 29.5 | 35.5 | 75.0 |
Table 2 – BLM performance in loaded and unloaded network
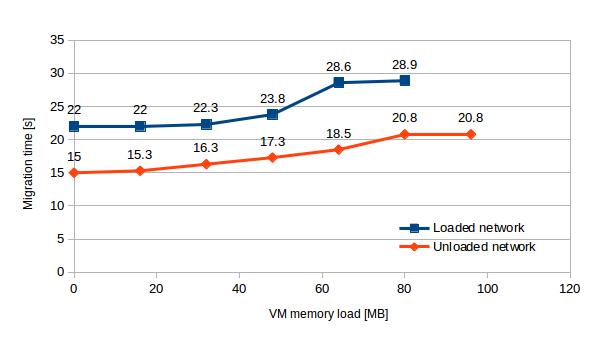
Regarding LM, in a previous blog post we found that migrating VMs with more than 96MB of stressed memory failed. The addition of network traffic pushed this limit even lower – to 80MB. In the tests, when LM was successful, heavy network load increased the migration time on average by 43%.
| Stressed memory [MB] | 0 | 16 | 32 | 48 | 64 | 80 | 96 |
| Loaded network | 22.0 | 22.0 | 22.3 | 23.8 | 28.6 | 28.9 | – |
| Unloaded network | 15.0 | 15.3 | 16.3 | 17.3 | 18.5 | 20.8 | 20.8 |
Table 3 – LM performance in loaded and unloaded network
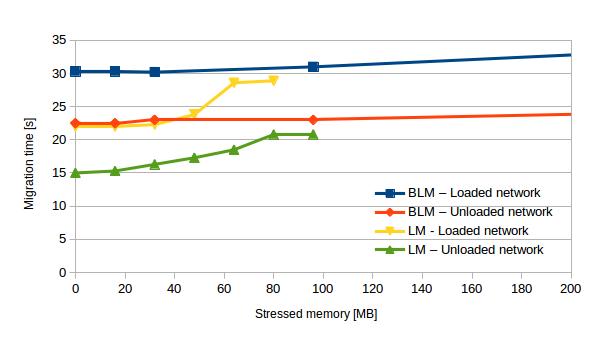
For an overview and comparison between performance of BLM and LM with and without network traffic see chart 4. We noted that the presence of network load causes the difference between LM and BLM migration time to decrease a little more quickly: this can be seen in Chart 4 where the blue and yellow lines converge more quickly than the red and green lines.
Summary
We explored the behavior of live migration in a more realistic setting than that of our previous work and we came to the following conclusions:
- Openstack live migration process is relatively undemanding in terms of server CPU load – it uses 50% – 80% of one CPU core during the migration. We observed a modest 20% increase of migration time on loaded servers (66% of all VCPU cores) in comparison with completely unloaded servers.
- Despite increasing network traffic up to the full capacity of the interfaces, migration duration increased by only about 24%. We also noticed that traffic generated by the migration suppressed the other network traffic, which could affect other system services.
- For our specific instance, the closer we get to realistic use cases, the smaller the gap between LM and BLM and migration times differ by only a few seconds. We note that LM is increasingly limited in terms of the amount of memory intensive activity that it can accommodate as the scenario becomes more realistic but we have not experienced any problems using BLM even with high memory loads.
Based on our observations, there is no problem migrating loaded instances between the loaded hosts and network using the BLM in Openstack. Even though LM was faster, it proved unreliable even for quite modest VM memory activity. In our work so far we recommend using BLM for migrating computing instances which do not require large capacity at acost of higher downtime as described in previous post. Note that due to limitations of our testbed we used instances with only 5GB of disk space – as disk space is handled differently using BLM (transferred via network) and LM (shared storage) this could mean that results would be different for larger disk space. It is likely that that increasing an instance’s disk capacity would result in significant poorer performance for BLM when compared with LM, especially in loaded networks.
Next up, we would like to explore other migration mechanisms with closer focus on post-copy approach.
we examined the execution of virtual machine (VM) live movement in various situations under OpenStack Icehouse.