Previously we described how to set up post-copy live migration in OpenStack Icehouse (and it should not be a problem to set it up in the same way in Juno). Naturally, we were curious to see how it performs. In this blog post we focus on performance analysis of post-copy live migration in Openstack Icehouse using QEMU / KVM with libvirt.
Generally, when we consider virtual machine live migration the most important performance characteristics are migration time, VM down time and the amount of data transferred via network. The reliability and predictability of the migration process are also important and they are also discussed here. Regarding the migration time, we measure the duration of the live migration using time stamps recorded in nova-compute logs (/var/log/nova/nova-compute.log) on source and destination hosts. We used the iftop tool for measuring amount of transferred data and the ping tool to determine the VM downtime; we pinged the VM public interface every 100ms (ping -i 0.1 <vm.float.ing.ip>) from a machine outside the network and track the packets lost during the migration to make the calculation.
All experiments were done on our mid-range 3-node experimental OpenStack Icehouse deployment (1x controller and 2x compute) using wp3-postcopy branch of QEMU 2.1.5. and wp3-postcopy branch of Libvirt 1.2.11. All nodes are the same IBM x3550 m4 servers using 24 VCPUs, 192 GB RAM, 2.7 TB storage and 1Gb/s ethernet interfaces. Note that live migration performance strongly depends on your hardware system setup (especially network throughput) and even though the results in in your environment may differ, this blog post should give you a sneak peak to the state-of-the-art live migration mechanism.
The main advantage of post-copy live migration is that it is guaranteed to terminate (unlike pre-copy which can result in a neverending migration in some cases). However, it is inherently less robust and any network interruption can cause VM failure. For these reasons Libvirt introduces a hybrid approach to live migration which is actually a combination of more traditional pre-copy migration followed by a phase of post-copy migration. In the ideal case the combination of pre-copy and post-copy guarantees finite migration convergence while minimizing the duration of the network-failure sensitive post-copy phase. The current implementation performs one iteration of pre-copy and then switches to the post-copy mode. That means that VMs with low memory change rate are safely migrated during the pre-copy phase and there is almost no need to perform the post-copy phase which focuses on changes to memory which occur during the migration process. If you are interested in knowing a bit more about the difference between standard pre-copy and post-copy live migration mechanisms you can read our earlier blog post.
It should be noted we observed that the migration process was very reliable in all experiments (unlike some of the earlier we performed using older versions of QEMU and Libvirt).
Hybrid live migration of unloaded instances
First of all we focused on basic live migration of freshly spawned VMs running a cloud image of Ubuntu 14.04 within different standard OpenStack flavors (from “small” to “extra large” – see table 1).
| Flavor | s | m | l | xl |
| VCPU (#) | 1 | 2 | 4 | 8 |
| RAM (GB) | 2 | 4 | 8 | 16 |
Table 1 – Parameters of the Openstack Flavors used
On average we were able to migrate small flavored instances in approximately 5.5 seconds (385 MB transferred), medium in 7.2 s (435 MB), large in 8.7 s (530 MB) and x-large in 11.3 s (680 MB). We can clearly see that not the all available RAM in the VM is transferred but just the part of the memory that has already been allocated. The downtime in all cases was less than 0.3 seconds.
| Flavor | s | m | l | xl |
| Migration time [s] | 5.4 | 7 | 8.7 | 11.3 |
| Downtime [s] | 0.2 | 0.2 | 0.2 | 0.3 |
| Transferred data [MB] | 385 | 435 | 530 | 681 |
Table 2 – Unloaded VM hybrid live migration performance
Hybrid live migration of “stressed” instances
In our earlier experiments with pre-copy live migration we observed cases of unsuccessful live migration due to a high rate of change of RAM in a VM. (Remember, pre-copy live migration fails if the VM’s RAM change rate is higher than source-to-destination network throughput). In these experiments, we used the stress tool to simulate intensive memory load. This tool runs a given number of threads that are periodically allocating and freeing a specified amount of memory. Our earlier experiments with stress of an x-large VM and pre-copy migration showed problems migrating instances with more than 100MB of stressed memory. We wanted to see how the new live migration approach worked in the same context to objectively compare with our previous work.
Unlike the pre-copy approach, the hybrid approach has an upper bound on the amount of data that will be transferred between source and destination: all used memory will be transferred during the pre-copy phase and all memory changed will be transferred at most once (unlike pre-copy) during the post-copy phase. Thus, in the worst case, the maximum amount of migrated data is given by 2 x RAM size and maximum migration time is 2 x RAM size / network throughput.
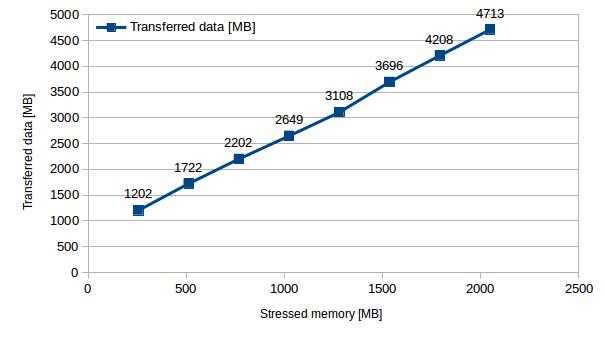
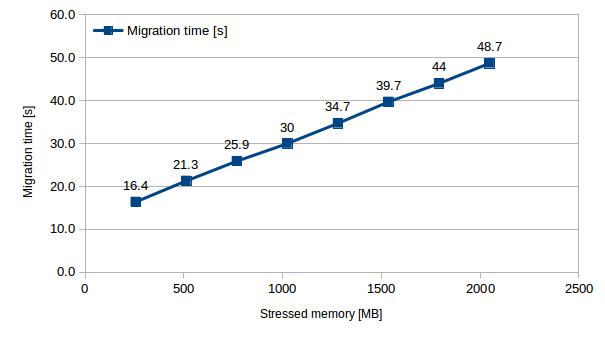
Increasing the amount of stressed memory in increments of of 256MB results in a clear linear increase of transferred data (2 x stressed memory + resources allocated by the system) and migration time (transferred data / network throughput).
| Stressed memory [MB] | 256 | 512 | 768 | 1024 | 1280 | 1536 | 1792 | 2048 |
| Migration time [s] | 16.4 | 21.3 | 25.9 | 30.0 | 34.7 | 39.7 | 44.0 | 48.7 |
| Transferred data [MB] | 1202 | 1722 | 2202 | 2649 | 3108 | 3696 | 4208 | 4713 |
Table 3 – Migration time and data transfer with increasing stressed memory (step of 256MB)
Once we were satisfied that live migration was reliable for smaller amounts of stressed memory, we increased the increment to 1024MB / thread and stressed up to 8 x 1024MB of the VM’s RAM and again observed the same linear increase of these variables.
| Stressed memory [MB] | 1024 | 2048 | 3072 | 4096 | 5120 | 6144 | 7168 | 8192 |
| Migration time [s] | 30.7 | 49.5 | 69.0 | 86.1 | 101.4 | 120.1 | 138.0 | 157.2 |
| Transferred data [MB] | 2725 | 4773 | 6728 | 8760 | 10500 | 12550 | 14600 | 16125 |
[Table 4 – Migration time and data transfer with increasing stressed memory (step of 1024MB)]
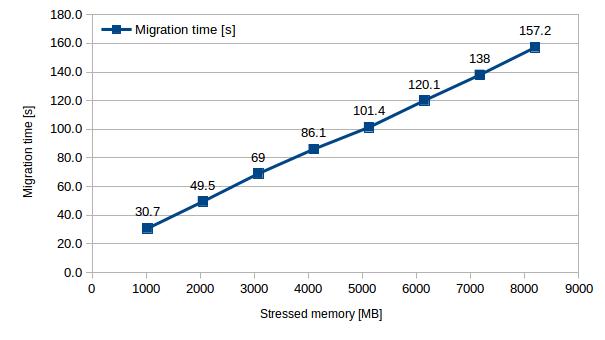
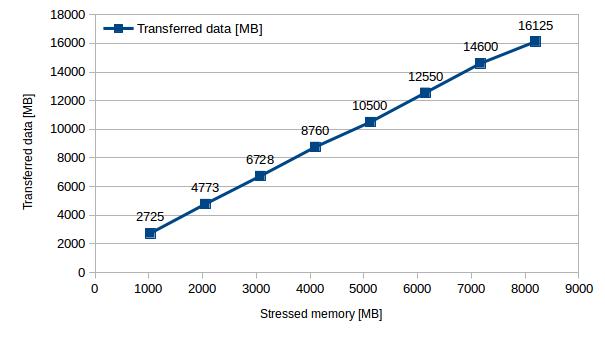
As can be seen from the data transfers in figure 6, using the stress tool we could see that all stressed memory was transferred twice – once during pre-copy and once during post copy – resulting in a total data transfer of very close to twice the amount of stressed memory.
We have observed several interesting observation regarding the downtime:
- There was no downtime during the pre-copy phase – the VM responds to ping requests and appears available.
- There was a small downtime (< 0.3 s) switching from pre-copy to post copy (activating VM on destination host and deactivating on source host)
- There was a quite unpredictable ping response rate in the post-copy phase. No matter how much memory was stressed sometimes no packet was lost during the post-copy phase, but sometimes we lost a significant amount of packets – in some cases it was as many as hundreds resulting in an outage of tens seconds. (We are still investigating this issue, but we think it must relate to networking and in particular ARP table configuration within the switches which are not updated to reflect the new location of the IP address)
Generally speaking the VM downtimes varied based on the duration of post-copy phase but in most of the cases we observed unresponsiveness to ping in terms of a few seconds.
Take aways
Hybrid live migration brings a significant improvement to the virtual machine live migration world even though it’s still a very new feature. So far the hybrid live migration seems to be a robust mechanism and big step towards more fluid host load management.
The key takeaways from our work are:
- In our 1 Gb/s network, migration of unloaded VMs took just a few seconds and even relatively heavily loaded VMs were migrated in terms of tens of seconds. Using 10Gb/s interfaces networks we believe we could live migrate most VMs reliably in under 10s in our basic environment.
- The finite convergence of post-copy provides predictable behavior and possibility to estimate the longest possible migration duration based on VM description and network capabilities.
- Downtimes of unloaded or moderately-loaded VMs varied in terms of seconds. In some cases we observed higher unresponsiveness of the VM during the post-copy phase.
Next, we will try to understand in a little more detail the reasons for varying downtime noted above, also we will explore additional live migration parameter settings to determine how they affect the performance and then focus on how it can be used for advanced load management in experimental systems.
Hi guys,
Thanks for your interesting post and a big thanks for sharing it with the others. I have two questions in this regard:
1- How did you differenciate betwee the down time in n pre-copy phase and the sowntime in postcopy phase? Did you usea specific tool or manipulate source code?
2- which tool did you use to stress the memory?
Thanks
Hello Sam,
1) We analysed the network traffic on the host and the destination host while migrating, from which you can clearly see the change of network behaviour when the phases swap as in the postcopy phase the traffic from the destination to the source increases significantly because of memory pages fetching.
2) We used stress tool (http://linux.die.net/man/1/stress). Currently I would recommend using stress-ng (http://kernel.ubuntu.com/~cking/stress-ng/) as it provides more fine grinded setting options.