In the context of the Cloud-Native Applications (CNA) Initiative at SPLab, we kicked off a few months ago a seed project with the aim of getting practical experience of the most common problems and pitfalls of re-architecting a legacy web application for the cloud. Here, we report on our experiences with a specific focus on the thorny problem of realizing a scalable, distributed database backend for such an application.
Cloud-native applications
The main characteristics of a cloud-native application is that it has to be resilient and elastic, and this has to be true for all the (micro)services and components that make up the application.
After choosing the Zurmo CRM application and making the Web server tier stateless, we concentrated on decomposing the application into containers, allowed multiple instances of Memcached to run concurrently, added a “dockerized” ELK stack for monitoring, and finally our own configurable auto-scaling engine (Dynamite).
We chose to use CoreOS as basic VM image and fleet as container / health-management component (for more details see Martin’s presentation on Migrating an Application into the Cloud with Docker and CoreOS). Fleet is basically a distributed systemd + etcd. After using it for some time we can definitely confirm what CoreOS states about fleet on github: it is very low level and other tools (e.g., Kubernetes) are more appropriate for managing application-level containers.
Our experiences with the CoreOS + fleet stack were not always positive and we encountered some known bugs that made the system more unstable than we expected (e.g., failing to correctly pull containers concurrently from Docker hub). Also, it is sometimes pretty hard to find out why a container is not scheduled for execution in fleet. A more verbose output of commands and logging would be much more helpful to developers approaching fleet for the first time.
Our work on Zurmo decomposition dealt first with components that could be easily made stateless and/or replicated. Then we concentrated on stateful components which in our case are:
- ElasticSearch: storing all the monitoring data coming from the system, and
- MySQL database: coming with the Zurmo application.
In this post we talk about the latter. In order to make the DB of the application resilient we had to move from a single MySQL container to a MySQL cluster with replication. This implies also that we needed to load-balance the requests to DB cluster nodes.
MySQL Galera
MySQL Galera provides an implementation of a multi-master cluster which, in a cloud environment, is typically a good choice since it’s easier to setup (and automate) replication across instances and it doesn’t require routing write requests to a specific node.
Our implementation forked from the excellent work of Patrick Galbraith (CaptTofu) on setting up MySQL Galera with Percona XtraDB Cluster on Kubernetes (his github repo here). We extended it with automated discovery and initialization of the cluster, plus HAproxy load balancing configuration. The whole source code is online in Github.
Discovery
When the Galera cluster node containers are started, they need to find out about each others’ IP addreses to connect and form a cluster. Since in cloud-native applications all VMs and containers are quite volatile, a discovery mechanism is needed to find out which components/services are running and on which endpoints.
CaptTofu’s solution on Kubernetes was for a time using the kubectl client to query the Kubernetes API to find out which containers (actually which ‘pods’ in Kubernetes lingo) were running. In light of a possible Kubernetes-native inter-pod discovery mechanism, that solution was put aside and the cluster initialization was achieved manually, using kubectl to start the Galera cluster pods one by one.
Our CNA architecture design uses etcd as a distributed registry of the components that are available in the system at a given point in time. Each Galera cluster node is defined in fleet by using 3 different unit templates:
- zurmo_galera_cluster@.service
- zurmo_galera_cluster_discovery@.service
- zurmo_log_courier_galera_cluster@.service
The first one is running the actual docker container with MySQL Galera, the second registers the container’s IP (actually the container’s host IP) and listening port under ‘/components/galera’ in etcd, and the third one is used to send logs to our ELK monitoring stack.
Initialization
It turns out that Galera cluster is pretty fickle and uninformative when bootstrapping, especially when you are trying to automate the whole thing. We had several tries and failures at setting up the cluster with the nodes finding each other, going through some initial consensus handshaking, and then breaking apart either into isolated nodes or simply shutting down. All this with no relevant logging of what the actual problem was: a quick search on Google will give you a taste of just how many people fail in setting up the cluster because of unclear documentation / error messages. A good intro to bootstrapping a Galera cluster is the one from Severalnines.
Bottom line, what worked for us was completely splitting the bootstrap phase for the Primary Component (PC) of the cluster and the rest of the nodes and wait to create and initialize the actual database tables until the cluster had reached size 3. If we tried to create the database before the cluster was stabilized the other nodes would fail to join and we could not figure out why.
The PC container starts with the –wsrep-new-cluster argument and an (initially) empty list of other cluster nodes. It registers itself in etcd. Meanwhile the other cluster nodes come up, discover each other and join the cluster initialized by the PC.
Once this happens, the PC creates the Zurmo database from a dump file. Replication to the other nodes starts immediately.
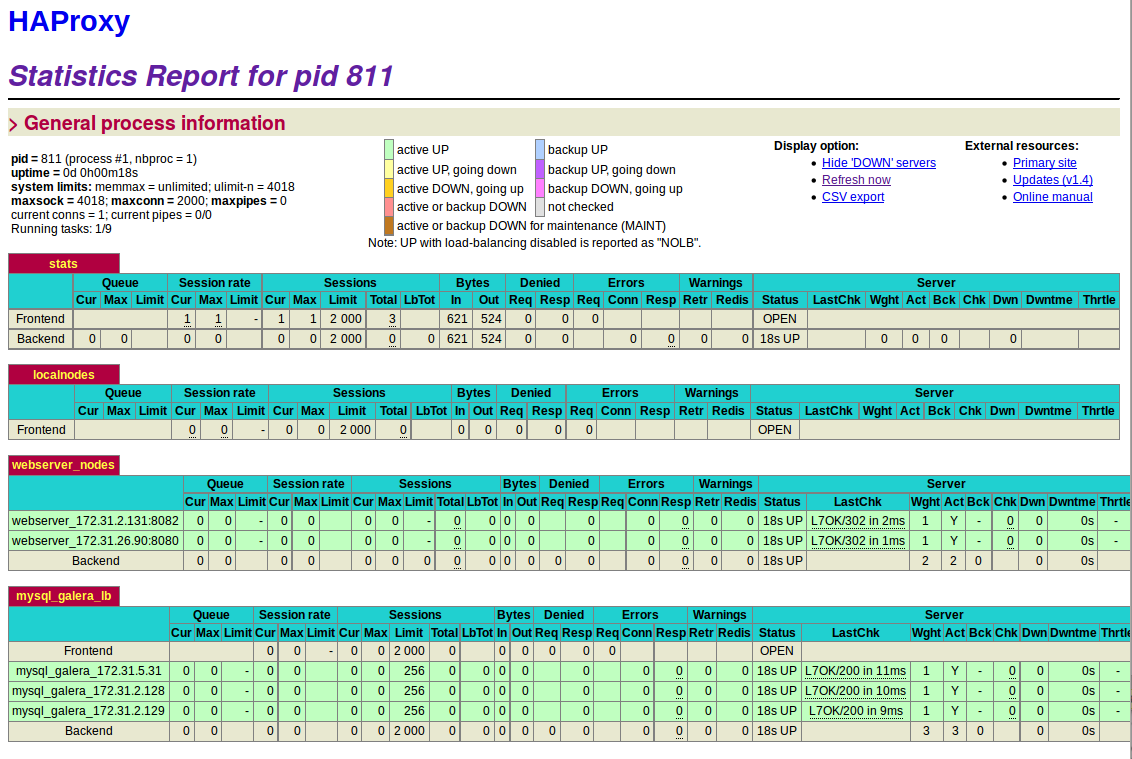
HAProxy for Galera cluster
Having (at least) 3 instances of the database containers, we need to reconfigure the Web application components (Apache in our case) to use them. Some database access libraries support client-side load balancing, but with PHP this doesn’t work, so we needed to configure HAProxy (zurmo_haproxy on the code) to act as a load balancer also for DB queries.
Our HAproxy container uses confd to check the ‘/components/galera’ key in etcd and reconfigure itself according to the number of available Galera nodes.
However, simply forwarding SQL traffic to nodes is not enough, since cluster nodes are stateful components that can be in different states (e.g., not initialized, not sync’ed). In order for HAProxy to be able to check externally the status of a Galera node, the container has a little xinetd script in ‘/usr/bin/clustercheck’ that returns an HTTP 200 response to HAProxy only if the node is in a valid state. This is very important to avoid sending traffic to nodes that are not ready, generating exceptions that can possibly be visible to the end user of the application.
Replication
Replication of the database and all its changes starts immediately in bulk when a new node joins the cluster. At the beginning, the primary node becomes a ‘donor’ for one of the other nodes. Any subsequent node joining (or re-joining) the cluster triggers a new bulk synchronization. It is interesting to notice that the ‘clustercheck’ script returns a 500 response both when a node is not yet initialized as well as for the whole time a node is acting as a donor.
Since in this prototype implementation we did not care about persistence, our Galera nodes are not using a persistent volume. This means that once a container fails / is restarted on a different host the synchronization of the whole database has to take place. The net result is that when we artificially induced failures in all our applications’ containers to assess reliability we noticed that for each Galera node we killed, another node became temporarily unavailable because it became a ‘donor’.
This effect would be of course minimized by using persistent volumes, but thus would require application and infrastructure-specific logic for automatically mapping persistent volumes to containers in health-management and auto-scaling scenarios.
Future work
We are currently finalizing the experiments on assessing non-functional properties (resilience, scalability, performance) of our implementation on AWS and Openstack. We will publish the results as scientific reports first and then here in the blog.
After this, we will concentrate on a Kubernetes implementation which has already been started in parallel.
Great article and implementation tof!
Any updates regarding the kubernetes implementation?
It would be great to have a look on it 🙂
Thanks in advance!
Thank you Luis! I’m glad you liked it 🙂
We are wrapping up the CoreOS/Fleet implementation doing some non-functional testing at the moment and writing a paper with the experimental evaluation.
In December we’ll restart with the implementation work for Kubernetes. We’ll put out new blog posts about it as soon as we’re done.
If you want to fiddle with it yourself in the meanwhile, my idea for the moment was still to use etcd for discovery of the Galera nodes, but maybe the new Kubernetes 1.1 already has some internal mechanism for pod discovery…
Hi
I was wondering whether there’s been any update on it.
There is some work / proof of concept already in this area e.g. see .
I am about to embark in this CoreOS/Kubernetes/Galera setup, and I much about it around, apart from the link above.
Although I am expecting the “Galera on Kubernetes” part of things to be the same regardless of whether Kubernetes runs on top of CoreOS or not. But I might be naive in this expectation.
Comments appreciated.
I was wondering whether I can just setup Kubernetes
Hi Adriano,
your comment seems a bit mingled. I didn’t have time to invest in the porting to Kubernetes of Zurmo, but just yesterday I published a post about “headless services” in Kubernetes (https://blog.zhaw.ch/icclab/challenges-with-running-ros-on-kubernetes/). In my opinion they could be used as a way to implement the “discovery” part that we were doing with etcd in our implementation.