Service scheduling and task placement within large-scale clusters is receiving a lot of interest in the cloud community at present. Moreover, service scheduling is one of the keystones of our recently kicked off ACeN project and we finally got a chance to experiment with the technology that is currently a frontrunner in this area – Apache Mesos. As Mesos provides much more control of service placement than current available built-in IaaS schedulers it elegantly addresses many problems in data centers such as task data locality, efficient resource utilization or efficient load variation accommodation. This blogpost describes Mesos architecture, its basic workflow and explains why we think it’s a big deal also in the cloud context.
Mesos is a fault-tolerant, scalable platform for isolated sharing cluster resources such as RAM or CPU between multiple diverse computing frameworks – applications running on top of it. More intuitively you can consider Mesos as a thin layer between your application and your cluster. This middleware enables you to schedule and maintain your services within the cluster more easily and efficiently.
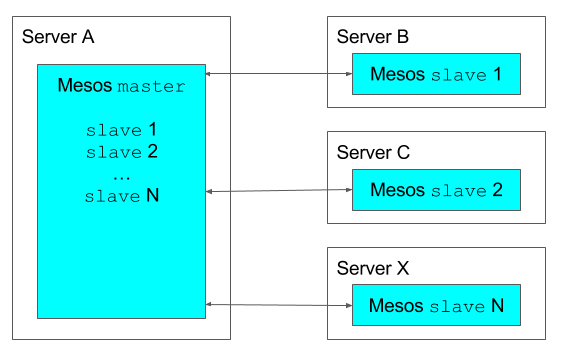
[Figure 1 – Basic Mesos architecture]
Figure 1 shows the two main Mesos components – the Mesos master process which can manage from 1 up to 10ks (!) Mesos slave daemons. Each slave daemon actively reports its available resources to the master’s allocation module so the master keeps track of the resources available within the whole cluster. Collected resources are offered by the master to the registered Mesos frameworks which can schedule task(s) if the offered resource matches the task requirements or wait for the next resource offer if the current one does not meet requirements. Frameworks respond to the master with the task description and the offer that matches its requirements. As all the offers contain its origin slave information, master instructs the executor to launch the task on the selected slave.
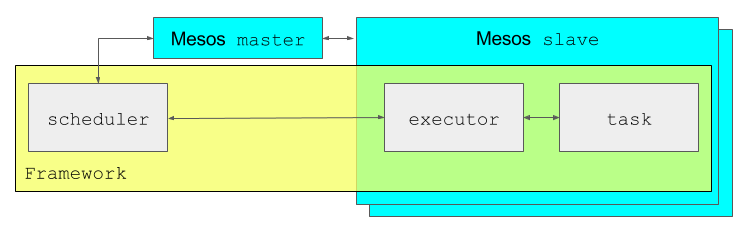
[Figure 2 – Mesos framework architecture]
Mesos, by default, tries to achieve fairness in amount of resources that are being offered to all registered frameworks. Frameworks, then, do have the control of whether (or not) to use the particular offer for running the task. More importantly, this logic allows frameworks to control the actual task placement within the cluster and hence helps to reduce applications’ data locality issues. Figure 2 shows this two-level resource offer workflow more illustratively.
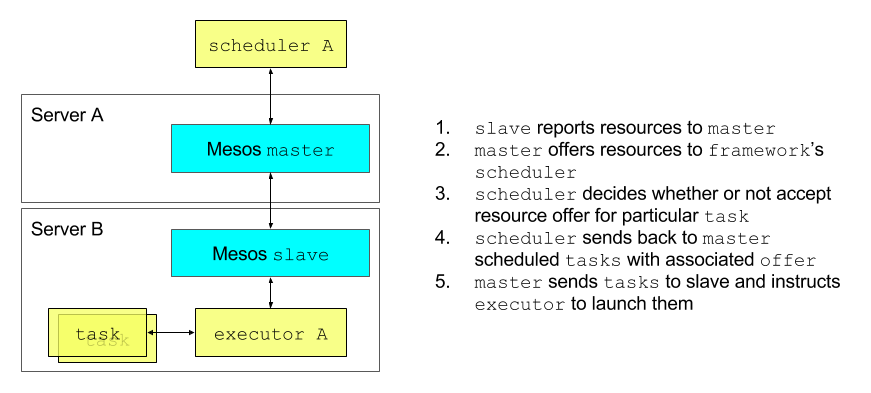
[Figure 3 – Resource offer workflow]
So now it is clear how tasks can be scheduled and launched but we have not fully addressed the “fault-tolerant” aspects of Mesos. As the Mesos master process is the key component, its termination causes mesos inoperability – slaves have no master to report their resources to, there is no master redistributing resources further, etc. unless there is another Mesos master process ready to take over. Fault tolerant mesos clusters operate with several Mesos master processes distributed over the cluster. All the master processes are connected to the zookeeper service responsible for quorum-based election process that ensures there is always only one leading master at time. Re-election takes place if and when the current leading process terminates and hence mesos operability stays uninterrupted.
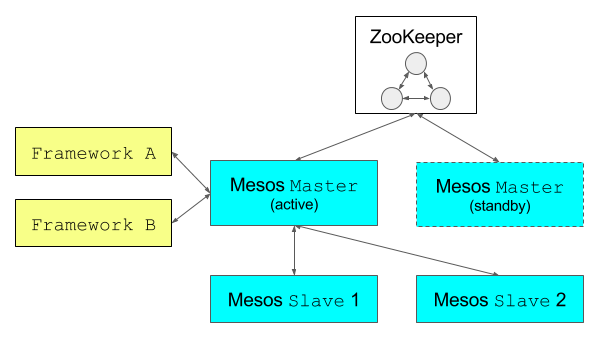
[Figure 4 – Fault tolerant Mesos architecture running frameworks]
There are many projects and frameworks built on top of Mesos (e.g. Spark, Hadoop, Marathon, …) that are designed for various types of tasks. Given smaller use cases it may be preferable to consider developing your own framework as it provides you more control and possible performance gains.
Mesos is currently experiencing a lot of success in the industry sector that drives its development forward many new capabilities are being added. One interesting direction of Mesos development is towards extending its functionality to provide primitives for internal storage handling. Another area receiving interest, is around providing a unified framework scheduler HTTP API that enables simple job submission to the framework. We’re very excited to investigate these new features further and share our impressions with you in one of our next blog posts.