So you have a new shiny OpenStack installation! Within that installation you may have differing classes of hardware and so you wish to be able to organise those classes.
To organise your OpenStack deployment there are two concepts currently available: Availability Zones (AZs) and Cells. These allow you categorise your resources within an OpenStack deployment and organise those resources as you see fit. These is a very useful feature in order to offer different types of the same service. For example you might want to offer a compute service that runs on SSDs or plain spinning disks.
In this article we’ll describe OpenStack Availability Zones (AZs) and OpenStack Cells. We’ll also show how each differ.
AZs are already available in Essex and Folsom releases. AZs allow you organise groups of hosts by tag (think folksonomy), however each compute node only can have one tag – the name of the availability zone their part of.
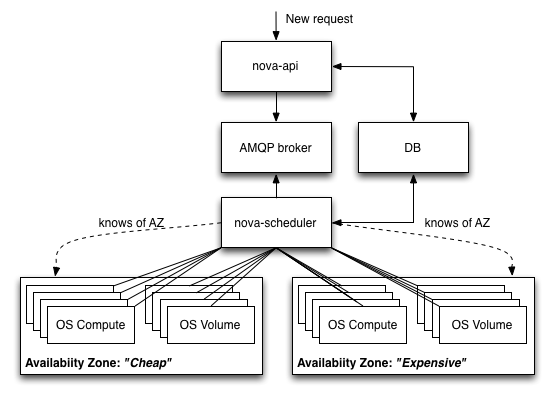
In this blog post is was said that “The good thing with availability zones is that you can manage and isolate different entities in your infrastructure.” However, there is little in terms of isolation given with AZs as all instances, without significant customisation, are still sharing the same infrastructure and OpenStack services. AZs allow you organise both compute and volume services and to enable the AZ feature you simply only have to declare node_availability_zone = $YOUR_AZ_NAME in the /etc/nova/nova.conf file (or configuration file fragment e.g. nova-compute.conf). This should be done on a per-node basis (so using parameterised puppet classes is useful here ;-). To list your nodes along with their assigned AZ, simply execute nova-manage service list. To allocate an instance upon a specific AZ you need to add –availability-zone $TARGET_AZ to the nova boot command. Currently, AZs are not exposed in the Horizon dashboard.
An alternative to AZs are OpenStack Cells. Cells separate much of the OpenStack services that are not separated by default when using AZs. These are only available in the current development edition of OpenStack and are targeted at the Grizzly release. Cells allow you organise groups of hosts as a directed graph (think ontology) or in other words, a tree. This is shown below (source).
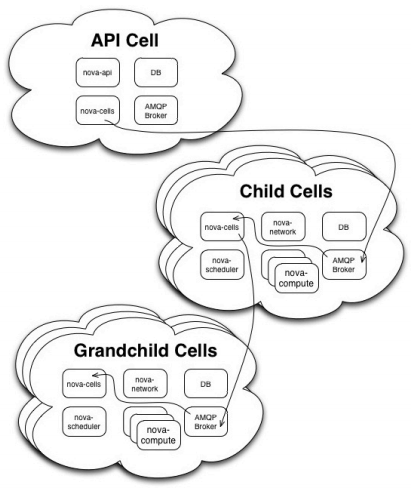
For each cell there is a separate message bus and database. The head of the tree has the OpenStack API service running. All child nodes within the cell tree are known to the OpenStack scheduler service and depending on what cell is selected, the scheduler will route a new instance request to that cell. In this way you can think of the request processing as IP packet routing. This certainly makes for more flexible organisation of larger OpenStack deployments, however perhaps add some amount of delay to provisioning: only benchmarking will tell. For further details on its configuration and setup see the Cell OpenStack wiki article. This is also a good overview presentation of Cells by one of the key developers. Cells are pretty cool and possibly lend themselves well to providing management capabilities where a provider has inter-connected data centres.
The great thing with both of these approaches is that it allows you to offer differentiated services to your customers. Could they be used together, most likely! We’ll certainly be experimenting with these features on our ICCLab OpenStack cluster.
1 Kommentar