After several months of development, last week was finally the first beta release of the distributed computing orchestration framework DISCO.
What is DISCO anyway?
Have you ever needed a computing cluster for Big Data to be ready in a matter of seconds, with a huge amount of computers at its disposal? If so, then DISCO is for you! DISCO (for DIStributed COmputing) is an abstraction layer for OpenStack‘s orchestration part, Heat (or any other framework which can deploy a Heat orchestration template). Based on the orchestration framework Hurtle developed at our lab, it supervises the whole lifecycle of a distributed computing cluster, from designing to disposal.
How does DISCO work?
As already mentioned, DISCO is a middleman between OpenStack and the end user. It not only takes the troublesome work of designing a whole (virtual) computing cluster but it also deploys a distributed computing architecture of choice onto that cluster – automatically.
What is DISCO’s architecture?
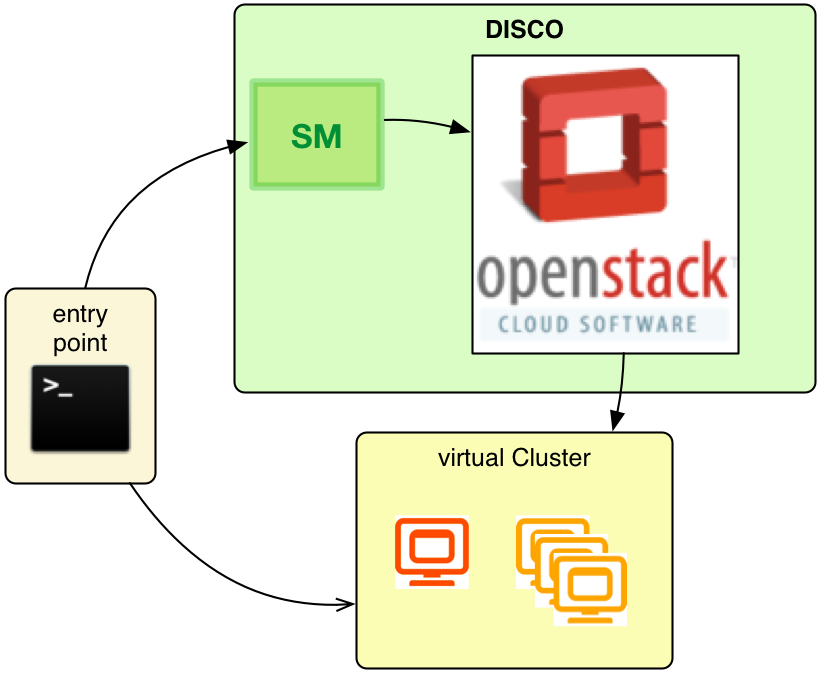
In its current version, the only possibility of accessing DISCO is by command line over its HTTP interface. Hurtle users will already know the term Service Manager (SM) which is the exposed endpoint of DISCO. While Hurtle deploys so-called Service Orchestrators (SO) to OpenShift, DISCO skips this step and accesses OpenStack directly. Before deployment, the end user can specify the properties of this cluster over parameters included in the HTTP request. These properties are as various as the end user’s needs.
- number of masters (if specifiable by the framework)
- number of slaves
- (virtual) network topology
- access restrictions
- and most importantly, the distributed computing framework(s) installed
As soon as all decisions have been taken by the end user, control is passed to DISCO. Upon receiving the request, it connects to OpenStack’s Heat and sends a template for a distributed computing cluster. How that works? See below!
…the cluster
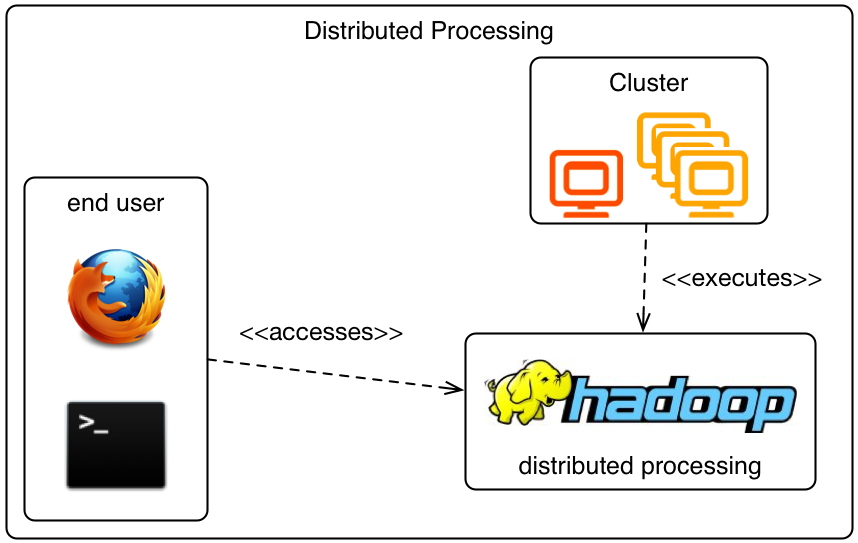
As soon as the cluster is fully deployed, it can be used as any regular cluster of connected computers. In its current implementation, Hadoop is the only framework which can be deployed. Still, as the most widely used Big Data processing framework, it will meet many requirements.
Of course, you still have to write your own distributed computing application for Hadoop – but your cluster is now ready to process it! You can even access the web interface of the built-in distributed filesystem HDFS as well as that of YARN, the resource manager of Hadoop.
And another, very appealing feature of DISCO is its flexibility. Have you realised that the specified amount of slaves won’t deliver any result in a reasonable time? Then, you can just re-create the cluster with more slaves! Or would you prefer having Spark instead of Hadoop? Maybe with HDFS as well? No problem, just stay tuned as this will be released in the next version!
And the best for all system administrators: as soon as the processing job has finished, you can just dispose of the whole cluster again in no time! There is no need for cleaning up any residue because there is none!
But no framework is complete, so let’s have a look at the next developments on DISCO.
Future
The DISCO project will put its focus on three main pillars for the foreseeable future.
Versatility
Other distributed processing frameworks are to be included to provide the end user with a greater range of choices when it comes to deciding in which way the data is to be processed effectively. This will also include niche products tailored to specific distributed computing needs.
User-friendliness
A major update to DISCO will be the release of a web interface which will take the necessity of issuing complicated HTTP requests. All the communication will be automated and the end user will only have to fill in a form with the requirements. In a more advanced version, not even the distributed processing framework will have to be given: based on a questionnaire and an algorithm, DISCO will find out on its own what the best-suited frameworks are which it will suggest to the user.
Configurability
Most distributed computing frameworks are highly configurable. Not only the given parameters will have to be mapped to the individual configuration for achieving highest data throughput, but also entirely new settings will have to be specified. Memory management, ratio, disk space – a huge amount of factors come into play. These will have to be configured for getting the best performance out of the system. Here again, power users would like to have full access to the configuration files at byte level while for the less experienced users, a comfortable interface will be provided taking over the whole work.
Could we spark your interest in using DISCO? If you would like to start immediately, go to our GitHub page and clone the repository. With the appended Readme, you should have no problems setting up your first DISCO deployment! Give it a try!