What is FaaS?
Cloud computing has become an essential paradigm of a majority of modern applications. The service model which represents cloud ecosystems is known as Everything-as-a-Service, or XaaS, with IaaS, PaaS and SaaS being among the most well-known representatives. All of them use similar client-server communication patterns (i.e. remote APIs for programmable infrastructure, platforms and applications) and they are similar in requiring the developer to understand the service functionality and characteristics.
FaaS is a refined cloud computing model to process requests through cloud functions, primarily intended to be integrated with applications and platforms. This microservice approach allows the developer to write code without paying attention to the runtime environment configuration and without thinking of resources, even though server-side resources are still used and hence ‘serverless’ is merely a fuzzy marketing term around the same concepts. With FaaS, DevOps may become just Dev at some point, lowering the entrance barrier to cloud computing for new developers considerably. FaaS being billed per function invocation, while other services force customers to pay for the environment running time whether needed or not, allows to prevent unnecessary expenses. This is especially handy when thinking of prototyping and development scenarios where a service is left unused for multiple days before returning to the associated project again.
Service Tooling initiative
The Service Prototyping Lab at ZHAW drives a research initiative dedicated to providing the right tooling for faster and better service development, called Service Tooling initiative. Within this initiative, we estimate that FaaS has a successful future in the cloud computing area, and therefore spend some effort on evaluating, abstracting and improving FaaS methods and tools. As a convenient and developer-centric way in deploying code in the cloud it offers a wide field for research and investigation. Our first target partially covered by this blog post is to perform an analysis of the existing FaaS service providers, design and implement the automated integration of application code into FaaS. In this post, we cover the experimental analysis of one FaaS provider.
FaaS providers
Several cloud providers have opened services recently, many of which are still in their explicit or implicit (i.e. we kind of found out) beta testing phase. Disclaimer: We are recipients of several academic and research grants by the listed providers which enable us to execute experiments and we aim to get feedback or baskets full of hard research questions by doing so.
AWS Lambda is the first product of it’s kind which had about 1.5 year head start on everyone else. It can be used as event-driven compute service or as compute service to run the code in response to HTTP request. Deployed code can be associated with specific AWS resources (e.g. a particular Amazon S3 bucket, Amazon DynamoDB table, Amazon Kinesis stream, or Amazon SNS notification)
IBM OpenWhisk is an open source experimental FaaS service announced in February this year. It provides a programming model to upload event handlers to a cloud service, and register the handlers to respond to various events or direct invocations from web/mobile apps or other endpoints.
Google Cloud Function is another service started in February 2016 and still in alpha. Functions can be triggered by any Google service that supports cloud pub/sub (Google emphasizes logging and email), cloud storage, arbitrary web hooks or direct triggers.
Microsoft Azure Functions supports six Azure integrations, plus timers and arbitrary applications via webhooks or HTTP triggers, and on-premises via the service bus.
Webtask.io supports scheduled tasks in addition to events, but as a stand-alone tool – those events arrive via webhooks and HTTP endpoints. Webtask.io is built atop CoreOS, Docker, etcd and fleet, with bunyan and Kafka for logging.
Hook.io is an open-source hosting platform for webhooks and microservices. The Hook can be executed by sending HTTP requests to this URL.
More stacks exist as open source or research prototypes without a permanent testbed to run our code under test in. We expect to set up private instances of Effe, OpenLambda and similar stacks in the near future.
Some provider shine with a lack of documentation about limitations of their services, presumably due to the beta status of the offering. For example one can find runtime environment limits only for AWS Lambda and IBM OpenWhisk implementations.
|
Provider |
Languages |
Availability |
|
AWS Lambda |
Node.js, Java, Python |
Service |
|
Google Cloud Functions |
Node.js |
Service |
|
Azure Functions |
Node.js, C# |
Service |
|
IBM OpenWhisk |
Node.js, Swift, Binary(Docker) |
Service + OSS |
|
Webtask.io |
Node.js |
Service + OSS |
|
Hook.io |
Node.js, ECMAScript, CoffeeScript |
Service + OSS |
Fig. 1. The table with FaaS implementations, supported languages and availability
Performance statistics
The purpose of the first test is to investigate performance characteristics of commercial FaaS services, using AWS Lambda as starting point. This particular service was chosen because it supports Java and because it is the very first service of its kind with a wider commercial significance. We also started designing a decomposer and code translator from Java to AWS Lambda Java functions which is still in the early stage and will be queued up the next blog-post. Therefore, all functions in this first test are hand-crafted. The idea of the test is to run a parallel algorithm of matrix multiplication using concurrently executed instances of one Lambda function. For this test we run 100 instances due to default safe limits of concurrent executions. For every particular matrix size we have made 20 tests and calculated an average value. For comparing we have run the same test locally but using one computation node (2.7GHz Intel Core i7-4800MQ). There are two different variants of such a test:
- With data generated inside the function (Fig. 2, orange (local) and blue (Lambda) lines).
- With data transferred through the network. Data sends to Lambda as JSON (PoJo). A matrix of size (respective dimension length) more than 1000 could not be run due to lack of resources (heap, GC, HTTP timeout). And even for a (1000,1000)-dimensioned matrix it takes around 82 seconds to transfer information and receive the response while the calculation time of each instance is around 272 milliseconds.
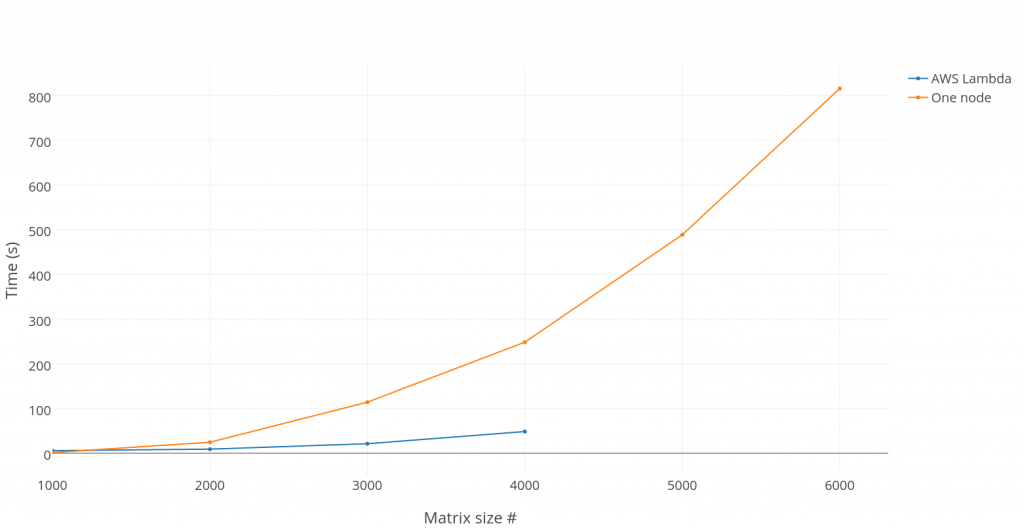
Paying attention that we compare calculations of 100 remote instances and only one local node we can conclude that the computing power of one Lambda function instance is less than expected but on the strong side the service is quickly auto-scaling. The values of the performance in the plot include the calculation, request and response time. That is why for small matrix sizes, one-node calculation is faster than 100 concurrent remote function instances, but when the matrix size increases and the pure calculation takes much more time than the input/output data transaction the total time difference becomes essential. As the test shows, if one multiplies a matrix of size greater than 4000, an exception is raised.
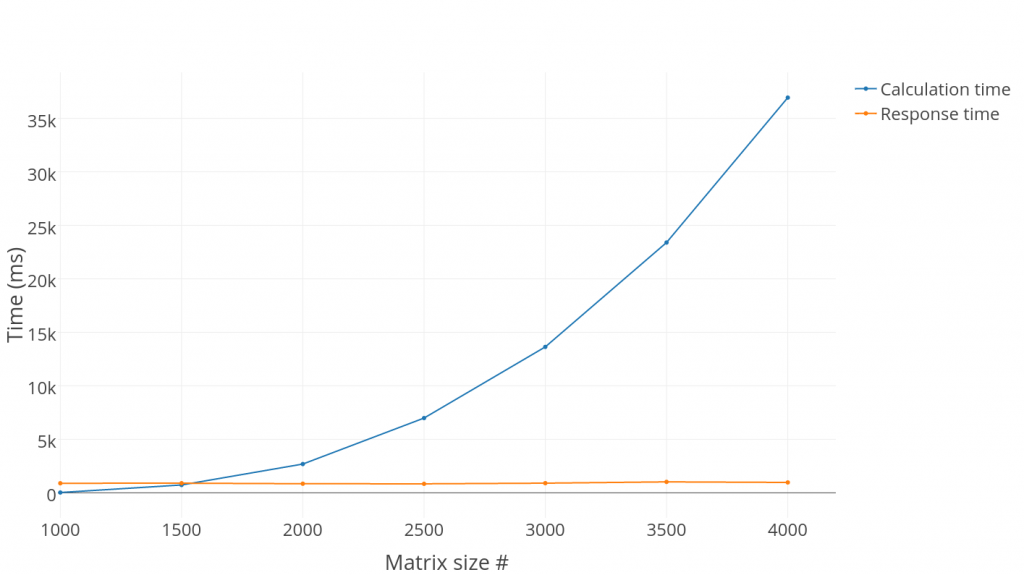
The plot shown in Fig. 3 displays the average calculation time without any transaction expenses and the average request-response time (response time in the further) of each instance. The average values were derived from 20 iterations per test for each particular matrix size which returns average values of 100 instances. Starting with matrix sizes of 1000, the response time is much higher than the calculation time, but after increasing the matrix size to 2000, the major part of function invocation time is calculation time. An interesting observation is that the response time is stable through the whole graph and it is independent of function load (although individual invocation runs may have high variances in timing, but we are going to cover this later).
The Lambda services allows to control code execution performance for every function. Developers and SaaS providers can explicitly chose memory sizes in the range from 128 MB to 1536 MB and the CPU power changes implicitly based on these memory settings. For all previous tests we used the 1536 MB plan. But in Fig. 4 below one can see some performance comparison between the lowest and highest memory setting plan. Of note is that highly efficient fine-grained microservices which would only require a few kilobytes or megabytes of memory would always be affected by overprovisioning.
|
Matrix size # |
Calculation time (ms) |
Response time (ms) |
||
|
128 MB |
1536 MB |
128 MB |
1536 MB |
|
|
500 |
22 |
4 |
788 |
725 |
|
1000 |
2026 |
26 |
889 |
882 |
|
1500 |
16310 |
731 |
920 |
898 |
Fig. 4. Calculation and response time of 128 MB and 1536 MB memory settings
The table in Fig. 4 includes the results of the same matrix multiplication test, but with different performance settings for each matrix size. The calculation time on the lowest configurations is much higher. And the maximum matrix size we could use to run the test was 1500, as for bigger matrices we started to receive exceptions. For the highest performance configurations the matrix size limit reached 4000. The response time is stable for both configurations (but again, with the caveat as mentioned above).
During the tests we noticed that the first invocations usually have a longer response time so we decided to check these results with comparable long delay time between tests (Fig. 5). To obtain these results, we used the same test as for the plot in Fig. 3 with matrix size 2000 and put different delay between queued single tests (Fig. 6).
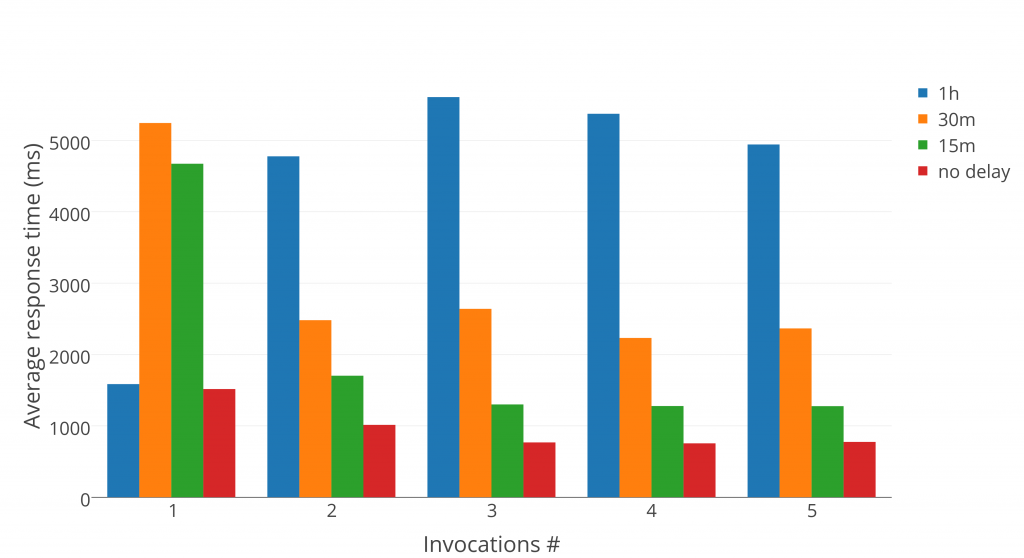
The very first invocation cannot show the real values because it is unknown when the last function call has been. But the response times of all further invocations have a stable dependency of delay between tests. The response time of just created functions is close to the response time of a test delayed by one hour.
Architecture and Code
Fig. 6 shows the architecture of our experiments, with a client-side runner and many tests which are run locally as well as remotely through the Lambda API. The code including some basic instructions and our obtained results (as reference baseline) is made available in the faas-experiments Git repository. We acknowledge that the contained JAR files are currently quite big and intend to reduce their size and thus the size of this repository in the near future.
