[This post was originally published on the GEYSER blog. ICCLab is a partner in GEYSER and is responsible for developing workload migration mechanisms and other activities.]
Scheduling workload in the cloud is an important capability which can be used to realize energy savings and it is the focus of some of our activities within the GEYSER project. The most prominent open source cloud stack – Openstack – provides little support for more flexible scheduling of workload, particularly pertaining to delay-tolerant work. The existing Openstack scheduler, within the nova component, launches every request in a sequential fashion – first-come-first-served – and consequently does not offer the required flexibility. Of course there is more intelligence in the scheduler such that certain hosts can be given higher priority with weightings, or filters can be used to prevent work from operating on other hosts, but it does not give the freedom to choose the time a VM/workload should be started. So, we developed a basic µservice which enables work to be scheduled for specific future points in time – the system is well integrated with the Openstack dashboard and we describe it here.
Currently, the system supports scheduling of work (in the form of VMs) at some specific time in the future: a user can indicate that they want a specific VM – including the image type, the flavour type, etc – to be started at a specific time. The request is retained in a queue until this time and then the Openstack APIs will be used to start the work. The work can be scheduled either directly via the Openstack Horizon dashboard (with our extensions) or using the service interface to the µservice. The system also supports removal of work from the queue if required.
The implementation comprises of three basic components – the API, the scheduling logic and a database to store information relating to the queued work. The basic architecture is illustrated below. Note that as the implementation involved modifications to the Horizon dashboard, there is not a clear separation between the cloud stack and the new functionality; however, in principal, there is no reason why this capability could not be applied to another cloud stack.
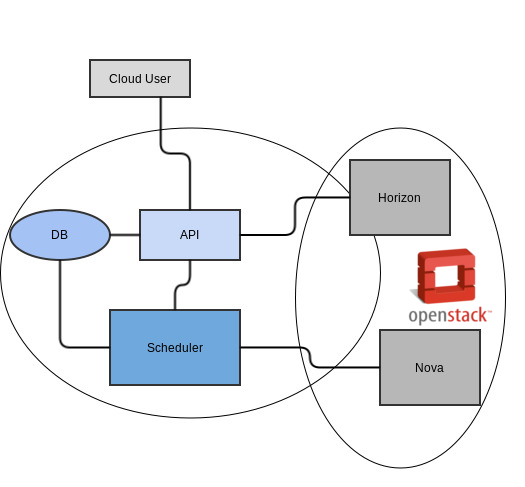
- API: Receive requests from horizon dashboard and cloud users, the request then is redirected to Scheduler and persisted into the DB. The current api calls supported are shown below.
GET /scheduler List Delay Tolerant Workloads
List Name, Description, Image Name, Status and Deadline.
POST /scheduler Create Delay Tolerant Workload
Creates a delay tolerant workload.
GET /scheduler/{id} Get Delay Tolerant Workload Details
List details of a specific delay tolerant workload.
PUT /scheduler/{id} Update Delay Tolerant Workload Details
Update attributes of the specific delay tolerant workload.
DELETE /scheduler/{id} Remove Delay Tolerant Workload Details
Removes a specific delay tolerant workload.
- Scheduler: Core feature of the µservice, queue requests according to user input – the queue is updated in every request sorting itself in an ascendent fashion.
- DB: Persists data in case system breaks, data is retrieved from scheduler and horizon.
Extending the horizon dashboard was relatively straightforward and there are many good quality sources available explaining how to do so (see here, here or here.) In general, we found that it did not require so many modifications to horizon, although there are some subtleties around the assumed directory structure and the code. Although the system is implemented in Django, it is not necessary to understand it in detail to make changes. Finally, for developing enhancements such as this, it is useful to add a second dashboard to your existing cloud infrastructure – this can work entirely independently from the main/production dashboard.
The system was implemented in python and the code will be published online soon.
The video below shows a demo of our µservice running in an experimental Openstack deployment.
Defaulttext aus wp-youtube-lyte.php
This initial variant has somewhat limited capabilities. new functionalities are in the pipe to provide better support for Openstack services (Neutron, Cinder and other projects) as well as greater intelligence to the µservice. Ultimately, this will be combined with server energy consumption information to determine the scheduling that can result in the greatest energy efficiency bearing in mind the deadline provided by the user.