Up to now, we have published several blog posts focusing on the live migration performance in our experimental Openstack deployment – performance analysis of post-copy live migration in Openstack and an analysis of the performance of live migration in Openstack. While we analyzed the live migration behaviour using different live migration algorithms (read our previous blog posts regarding pre-copy and post-copy (hybrid) live migration performance) we observed that both live migration algorithms can easily saturate our 1Gb/s infrastructure and that is not fast enough, not for us! Fortunately, our friends Robayet Nasim and Prof. Andreas Kassler from Karlstad University, Sweden also like their live migrations as fast and reliable as possible, so they kindly offered their 10 Gb/s infrastructure for further performance analysis. Since this topic is very much in line with the objectives of the COST ACROSS action which both we (ICCLab!) and Karlstad are participants of, this analysis was carried out under a 2-week short term scientific mission (STSM) within this action.
This blog post presents a short wrap-up of the results obtained focusing on the evaluation of post-copy live migration in OpenStack using 10Gb/s interfaces and comparing them with the performance of the 1Gb/s setup. The full STSM report can be found here.
STSM Overview
The STSM took place in Karlstad University in Sweden from 18.4.2015 to 2.5.2015 under supervision of Prof. Andreas Kassler. It was funded via the COST ACROSS (IC 1304) action. The main goal of the STSM was to evaluate state of the art virtual machine (VM) live migration approaches using the testbed available in Karlstad which has 10 Gb/s network infrastructure. As a part of this STSM we also scheduled a short visit to the Distributed Systems lab led by Prof. Erik Elmroth at Umea University in Sweden as its researchers currently are one of the top contributors working on advanced virtual machine live migration techniques and they are also affiliated with the COST ACROSS action.
Live migration basics
First of all a short introduction to the theory of live migration. Virtual machine (VM) live migration is a process of transferring a running VM from one hypervisor to another. Desirably, this process should be fast, convergent, and without any service interruptions. Currently, using the QEMU hypervisor you will probably deal with the built in pre-copy live migration algorithm that has a serious non-convergence risk which manifests when migrating VM with memory intensive loads. With a little more effort you can set up your environment to use post-copy (hybrid) live migration instead. As the post-copy algorithm fetches missing VM’s RAM pages after the VM on the destination is activated there is ensured convergence for the price of fragmentation of the VM’s memory between the source and destination while migrating. The hybrid approach combines both solutions described to ensure convergence and reduce the fault sensitive post-copy phase.
Setting up the environment and test framework
That’s the theory – now to the practice!. After my arrival and very nice welcoming in surprisingly sunny sweden we spent few days setting up the testbed.
We used two physical machines Dell PowerEdge M610 (Intel Xeon E5520 @ 2,7GHz, 24GB RAM) as a modules of a Blade server providing 10Gb/s network interfaces through its backplane. We installed Openstack Juno with QEMU / libvirt with the post-copy support. One server was configured purely as a compute node running nova and nova-network services. The second one was configured as both a compute node and the controller node providing also all the other management services.
Evaluating the live migration performance we focused on measuring:
- Migration duration (total migration time) (log records’ timestamps)
- Duration of VM unavailability (VM downtime) (ping VM from external source)
- Amount of data transferred through the migration interface (stress tool)
Results
Using the iperf tool we measure the real throughput of 10-Gb/s interface in configuration using full 10 Gb/s and also limiting this interface to 1-Gb/s. In 10-Gb/s mode we achieve throughput 7.5 Gb/s between both physical machines. For 1 Gb/s configuration the same actual throughput is 990 Mb/s.
Fig. 1 shows very limited possibilities of using standard pre-copy algorithm for live migration of virtual machines with a memory intensive applications. Using 1 Gb/s configuration, the pre-copy algorithm was able to migrate only essentially unloaded or lightly loaded (< 32 MB of stressed memory) virtual machines. Higher amounts of stressed memory leads to non convergence. Using the 10 Gb/s configuration the threshold of the amount of stressed memory that is still pre-copy ‘migratable’ increases up to approximately 400MB and thus extends possibilities of using the standard pre-copy algorithm for more use cases. Beyond this value the pre-copy approach fails also using the 10 Gb/s network. In all cases when LM converges the downtime was less than 400 ms. More precisely, using the pre-copy the downtime varied from 300ms to to 400ms.
![Fig 1. Pre-copy live migration - Migration time [s]](http://blog.zhaw.ch/icclab/files/2015/08/image.png)
Fig 1. Pre-copy live migration – Migration time [s]
The hybrid algorithm converges regardless of the amount of memory stressed and the network throughput. Fig. 2 and Tab.1 shows linear increase of migration time with increasing amount of stressed memory in the both network configurations. In all the cases using 10 Gb/s leads to lower migration times. Migrating essentially unloaded VM, the total migration time reduced from 11,9 s (σ = 0,4 s) to 8,3 s (σ = 0,4 s) in favor of the 10Gb/s infrastructure. As the load (and the amount of transferred data) increases the difference between both setups becomes more significant. For example, stressing 8 GB of VM’s memory, the live migration took 151,8 s (σ = 0,4 s) on the 1 Gb/s infrastructure and 40,5 (σ = 4,3 s) s on the 10 Gb/s infrastructure.
| Stress [MB] | 0 | 1024 | 2048 | 3072 | 4096 | 5120 | 6144 | 7168 | 8192 |
| 10 Gb/s | 8,3 | 11,6 | 14,9 | 18,6 | 22,1 | 26,1 | 29,9 | 34,5 | 40,5 |
| 1 Gb/s | 11,9 | 28,9 | 47,0 | 64,4 | 81,3 | 96,3 | 116,4 | 133,4 | 151,8 |
[Tab. 1 – Hybrid live migration – Migration time [s]]
![Fig 2. - Hybrid live migration - Migration time [s]](http://blog.zhaw.ch/icclab/files/2015/08/image-1.png)
Fig 2. – Hybrid live migration – Migration time [s]
The downtime using the hybrid approach appears to be very stable and in the most of the cases lower than 500 ms (see Tab. 2 and Fig. 3). The downtime varies from 200 ms to 600 ms as the amount of stressed memory increases. Interestingly, we also do not observe any significant differences between 1 Gb/s and 10 Gb/s configurations.
| Stress [MB] | 0 | 1024 | 2048 | 3072 | 4096 | 5120 | 6144 | 7168 | 8192 |
| 10 Gb/s | 0,2 | 0,2 | 0,2 | 0,2 | 0,4 | 0,4 | 0,3 | 0,4 | 0,5 |
| 1 Gb/s | 0,3 | 0,3 | 0,3 | 0,3 | 0,3 | 0,4 | 0,4 | 0,6 | 0,6 |
[Tab 2. – Hybrid live migration – Downtime [s]]
![Fig 3. - Hybrid live migration - Downtime [s]](http://blog.zhaw.ch/icclab/files/2015/08/image-2.png)
Fig 3. – Hybrid live migration – Downtime [s]
Predictably, the amount of the memory transferred over the network increases with increasing stressed amount of memory. More precisely, as we can see in Fig. 4 the hybrid live migration of loaded VM transfers approximately twice as much as the memory stressed. That confirms the ability of the stress tool to simulate the worst case where all the memory pages transferred in the pre-copy phase are dirtied and therefore these need to be transferred again in the post-copy phase.
![Fig.4 - Hybrid live migration - Transferred data [MB]](http://blog.zhaw.ch/icclab/files/2015/08/image-3.png)
Fig.4 – Hybrid live migration – Transferred data [MB]
Charts in Fig. 5 shows the migration traffic behaviour in the direction from the source to the destination host. In both scenarios a VM with 2GB of the stressed memory was migrated using the hybrid algorithm that transferred approximately 4,7GB over the network. While migrating using the 1 Gb/s configuration the migration traffic sufficiently utilizes the link up to the iperf baseline, using the 10 Gb/s setting the utilization reaches maximal throughput baseline only in its peaks that brings a room for further analysis.
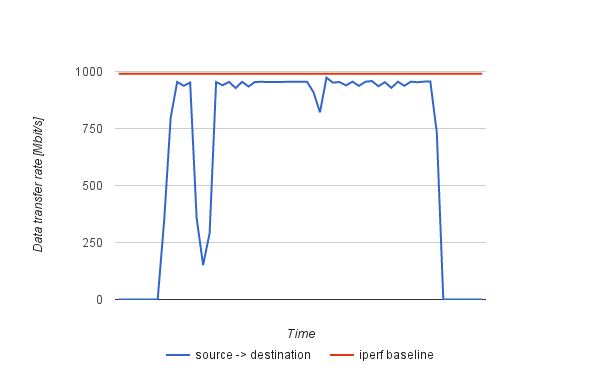
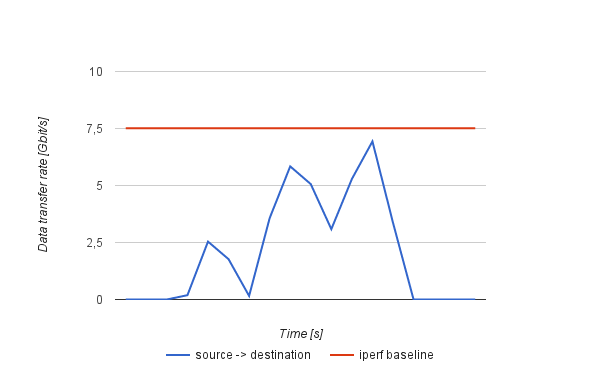
Fig. 5 – Hybrid live migration – Network utilization (1 Gb/s and 10 Gb/s)
Conclusion
The hybrid live migration algorithm has proven to be a reliable tool for managing resources in the data centers regardless of VM load. This work presents the benefits of using 10 Gb/s network infrastructure especially in terms of shorter migration duration that has been up to 3,7 times shorter than using the 1 Gb/s infrastructure. Using the hybrid approach on 10 Gb/s infrastructure, the live migration has become a question of tens seconds for the VMs with very intensive memory loads, that took minutes to migrate on the 1Gb/s infrastructure. The change of the network infrastructure has not affected the downtime that has shown as a stable and lower than 500 ms with a very little insignificant variation.
Faster infrastructure also slightly extends possibilities of using standard pre-copy algorithm for more use cases and statistically decreases risk of its non convergence.
More interestingly, it has been shown that relatively large amounts of data (gigabytes of memory) need to migrated in order to fully utilize the 10 Gb/s link.
As a follow up to this STSM, we are planning to write a joint paper covering this topic more in the detail. Stay tuned!
Acknowledgements
I would like to thank to all who participated to make this STSM happened. Especially to Prof. Andreas Kassler and Robayet Nasim from Karlstad University for their boundless hospitality and helpful supervision. Next, I would like to thank to Luis Bolivar and other people from Umea University for inviting and hosting me while discussing a future possible collaboration. Big thanks also goes to Prof. Thomas Bohnert and Sean Murphy from the home institute ZHAW for providing me the possibility to meet and work with these people in Sweden. Thanks to COST ACROSS for making this possible.
Hi , I am working on developing a hybrid algorithm for live VM migration, and I am using Openstack as my platform. I have configured a three-node environment (one controller and two compute nodes) for this purpose, and I’m using neutron instead of the nova-network.
By default, as you mentioned, the nova live-migrate uses pre-copy algorithm. What made me read this post was the hope of finding a method of inserting my algorithm into the nova live-migrate framework, so that I may be able to implement my algorithm practically and carry out comparative studies.
Please help me regarding modifying the default set algorithm for live migration in Openstack. If any additional packages or plug-ins are to be installed for this purpose, please mention them.
Thanks