In the first part of the Distributed File Systems Series we gave an introduction to Ceph. Today we will explore another file system: GlusterFS.
GlusterFS is a clustered network filesystem that uses FUSE and that allows to aggregate different storage devices, bricks in GlusterFS terminology, into a single storage pool. The storage in each brick is formatted using a local file system, e.g. XFS or ext4, and then exposed to GlusterFS for storing data. The user space approach gives GlusterFS flexible release cycles and easiness of use without taking tolls on the performance of the file system.
Two of the main concepts of GlusterFS are volumes and translators.
A volume is a collection of one or more bricks. There are three different type of volumes in GlusterFS that differentiate in how the volume stores the data in the bricks:
- Distribute Volume. In this type of volume all the data is distributed throughout all the bricks. The data distribution is based on an algorithm that takes into account the size available in each brick. This is the default volume type.
- Replicate Volume. In a replicate volume the data is duplicated, hence replicate, over every brick in the volume. The number of bricks must be a multiple of the replica count.
- Stripe Volume. In a stripe volume the data is striped into units of a given size among the bricks. The default unit size is 128KB and the number of bricks should be a multiple of the stripe count.
A translator is a GlusterFS component that has a very specific function; some of the main functionalities of GlusterFS are implemented as translators, e.g. I/O scheduling, striping and replication, load balancing, failover of volumes and disk caching. A translator connects to one or more volumes, perform it specific function and offers a volume connection; therefore translators can be hooked together to provide a file system tailored to certain needs. The whole set of translators linked together is called a graph.
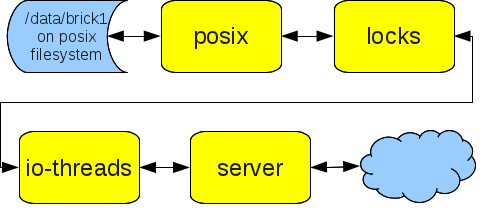
GlusterFS offers a fairly long list of translators for different needs:
- Storage Translators. These translators define the behaviour of the back-end storage for GlusterFS. A storage translator is typically the first translator in a chain.
- POSIX: tells GlusterFS to use a normal POSIX file system as the backend, e.g. ext4.
- BDB: tells GlusterFS to use the Berkeley DB as the backend storage mechanism. This translators uses key-value pairs to store data and POSIX directories to store directories.
- Clustering Translators. These translators are used to allow GlusterFS to use multiple servers to create a cluster. These translators are used to define the basic behaviour of GlusterFS.
- Unify: with this translator all the subvolumes from the storage servers will appear as a single volume. An important feature of this translator is that a given file can exist on only one of the subvolumes in the cluster. The translator uses a scheduler to determine where a file resides, e.g. Adaptive Least Usage, Round Robin, random.
- Distribute: this translator aggregate storage from several storage servers.
- Replicate: this scheduler replicates files and directories across the subvolumes. If there are two subvolumes then a copy of each file will be on each subvolume.
- Stripe: with this translator the content of a file is distributed across subvolumes.
- Performance Translators. These translator are used to improve he performance of GlusterFS.
- Read ahead: this translator pre-fetches data before it’s required, usually data that appears next in the file.
- Write behind: this allows the write operation to return even if the operation has not completed.
- Booster: using this translator applications are allowed to skip using FUSE and access the GlusterFS directly.
More translators can be written according to specific requirements.
For the next part of the Distributed File Systems Series we will be looking at XtreemFS.