It has been a month since the RCB team released Cyclops 2.0, its flagship open source framework for cloud billing and service providers. The release itself was very successful, as it attracted many new users and generated a substantial growth in the number of Github views and unique visitors.
Last week we carried out our first developers on-boarding session over Google Hangouts, focusing on how to write your own collector for RCB Cyclops. In this blog post we will go over a hypothetical use case of PaaS (Pigeon as a Service), which as you will see is very similar to OpenStack Events collection we already support. The idea is to show how easy it is to implement both discrete rating, as well as event processing (where pigeon receives events similar to OpenStack).
Once you have installed, configured and deployed all components of the RCB Cyclops, the next logical step is to develop and plug your usage collector into the Cyclops framework (more about the architecture over here).

For simplicity’s sake we will be only looking into two high level event types, and that is when pigeon is recruited and then later retired. In the picture below you can see the parallel between this hypothetical use case and OpenStack events, where the RCB Cyclops framework allows you to bill your users based on various levels of granularity.
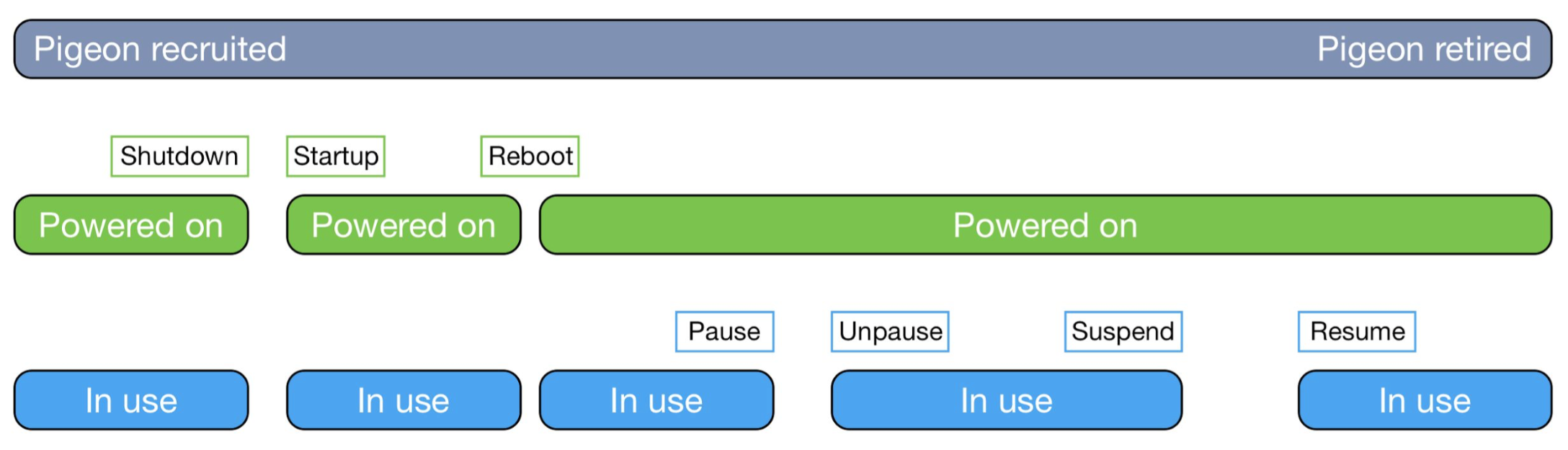
Imagine now that our business model relies on pigeon uptime, but not only that, we additionally also charge for every single recruitment. Let’s pretend that our pigeon usage collection service is outputting two distinct events in JSON message format, sending it to the incoming queue of the RCB Cyclops framework (read more here).
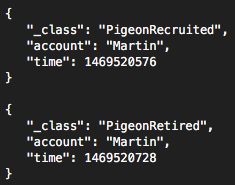
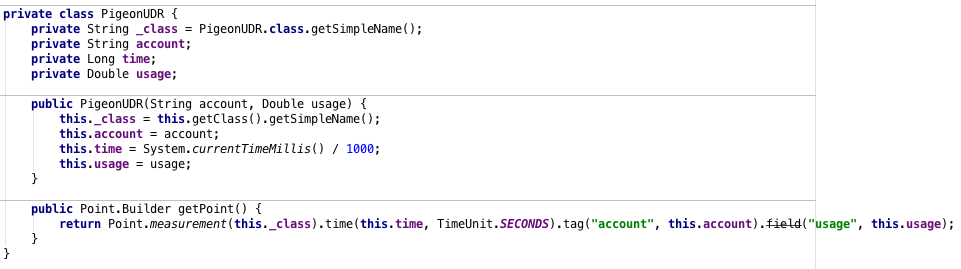
Now that we know how individual event messages are represented (in JSON message format) we can start mapping it inside of the individual micro services. Even though the RCB Cyclops framework works automatically with defaults (meaning that you don’t really need to specify anything), we still prefer to explicitly specify what is the semantic of our data. In order to do so we will start with UDR micro service and register two new DataMapping classes in core/udr/src/main/java/ch/icclab/cyclops/consume/data/model folder.
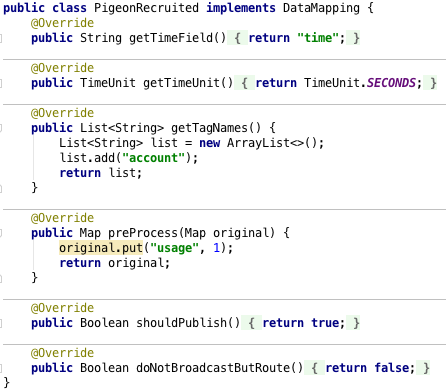
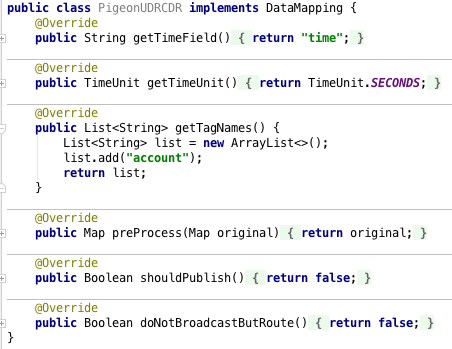
By implementing the DataMapping interface we tell the underlying micro service how to process incoming messages, that are received either from RabbitMQ or over RESTful POST request. Repeating it one more time, if we don’t implement this interface, the message will be still processed and stored into InfluxDB time series database, but the semantics of the data will not be understood. In the case of pigeon being recruited we will map JSON _class field by creating a new Java class with the exact same name. Internally this is also used between individual micro services for automatic object recognition.
This data mapping interface is present in all micro services (UDR, CDR and Billing) and is documented in detail here. In our case we will create two Java classes with names PigeonRecruited and PigeonRetired, where in both we will implement DataMapping interface. Because we consider first event type to be a billable event on its own, we will assign an usage value to it during the preprocessing stage, as can be seen in the picture below. We will also specify that this message should be automatically broadcasted in a stream processing manner to the next micro service for further processing. When PigeonRetired message is received, we only care about storing it, as we will be manually generating UDR records later.

Once we have data mappings done, we can proceed with implementation of UDR generation command, which is again delivered to the micro service either via RabbitMQ or RESTful POST request. We first need to register this command by placing it in /core/udr/src/main/java/ch/icclab/cyclops/consume/command/model/ folder and extending the Command class. The exact implementation of your commands will differ as it’s domain specific, but in our case of UDR generation for pigeon uptime it’s very straightforward. We just need to iterate over individual events and calculate the uptime between pigeon recruitment and retirement events.

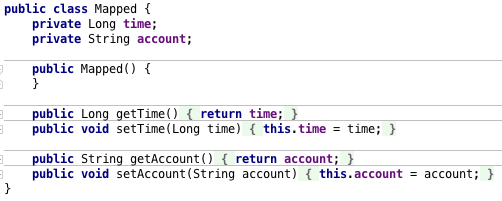
Every single micro service allows you to query underlying InfluxDB time series database, as well as map the result of the query to POJO class. You can use this in your advantage as can be seen in the following two pictures and store calculated UDRs back into database, alongside broadcasting it to the next micro service.
Then the command that would need to be sent into commands queue of UDR micro service would look like this:
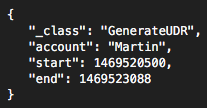
Now that UDR micro service understands semantics of pigeon being recruited (assignment of usage value of 1), pigeon being retired (just persist into database), as well as GenerateUDR command that creates PigeonUDR records and broadcasts them further, we can follow up with Static Rating micro service and specify rates for these two billable items (recruitments and UDR records).
The only thing we need to do now is to specify these class names as key/value pairs in the configuration file of Static Rating micro service, as follows:
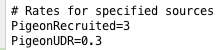
This micro service will automatically rate individual records and push them to the next micro service for further processing and persisting. One thing worth mentioning is that anyone can develop a rating function, which doesn’t necessarily have to be implemented in Java, as the communication is done over AMQP protocol (in our case RabbitMQ).
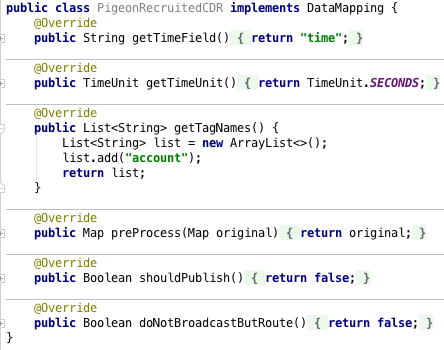
The next step is to extend CDR micro service in order to semantically understand incoming records and store them into InfluxDB time series database. If we omit these mappings, records will be still persisted, but time-stamped with server’s time and without providing any tags (which is useful for later Group By queries).
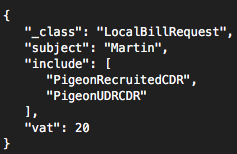
You may ask what is the remaining step? A bill generation of course, and good news is that you don’t have to implement a single line of code in Billing micro service, as account settlement process is so generic we did it for you. When you want to generate a bill for someone, just send a command message to Billing micro service (either over RabbitMQ or RESTful POST request), as can be seen in the picture below. It even supports SLA violations, coupons, discounts and VAT rates (read more here)
And that’s it, now you know how to write your own usage collector and how to integrate it with the overall Rating-Charging-Billing workflow inside of the Cyclops framework. It is also very easy to access all UDR and CDR records, as well as to check out generated bills, as everything is accessible over RESTful APIs (read more here).
If you missed our developers onboarding session last week don’t worry, we will be covering similar use cases (next time more advanced federated billing), so stay tuned and follow us on Twitter via @rcb_cyclops
If you have any questions or suggestions for us, please write to us on icclab-rcb-cyclops@dornbirn.zhaw.ch