In a former article we spoke about testing High Availability in OpenStack with the Chaos Monkey. While the Chaos Monkey is a great tool to test what happens if some system components fail, it does not reveal anything about the general strengths and weaknesses of different system architectures. In order to determine if an architecture with 2 redundant controller nodes and 2 compute nodes offers a higher availability level than an architecture with 3 compute nodes and only 1 controller node, a framework for testing different architectures is required. The “Dependability Modeling Framework” seems to be a great opportunity to evaluate different system architectures on their ability to achieve availability levels required by end users.
Overcome biased design decisions
The Dependability Modeling Framework is a hierarchical modeling framework for dependability evaluation of system architectures. Its purpose is to model different alternative architectural solutions for one IT system and then calculate the dependability characteristics of each different IT system realization. The calculated dependability values can help IT architects to rate system architectures before they are implemented and to choose the “best” approach from different possible alternatives. Design decisions which are based on Dependability Modeling Framework have the potential to be more reflective and less biased than purely intuitive design decisions, since no particular architectural design is preferred to others. The fit of a particular solution is tested versus previously defined criteria before any decision is taken.
Build models on different levels
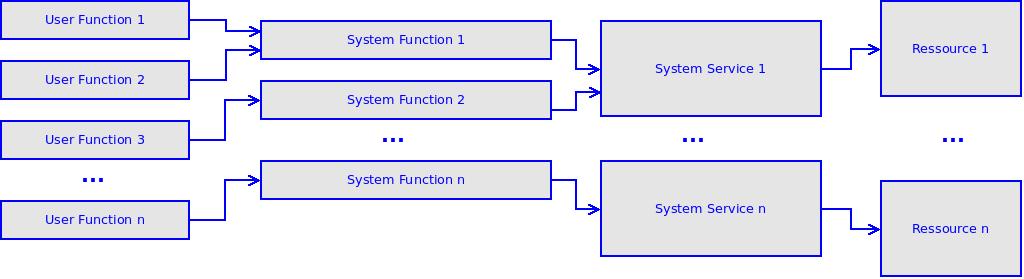
The Dependability Model makes the impact of resource outages calculable. One could easily see that a Chaos Monkey test can verify such dependability graphs, since the Chaos Monkey effectively tests outage of system resources by randomly unplugging devices. The less obvious part of the Dependability Modelling Framework is the calculation of resource outage probabilities. The probability of an outage could only be obtained by regularly measuring unavailability of resources over a long time frame. Since there is no such data available, one must estimate the probabilities and use this estimation as a parameter to calculate the dependability characteristics of resources so far. A sensitivity analysis can reveal if the proposed architecture offers a reliable and highly available solution.
Dependability Modeling on OpenStack HA Environment
Dependability Modeling could also be performed on the OpenStack HA Environment we use at ICCLab. It is obvious that we High Availability could be realized in many different ways: we could use e. g. a distributed DRBD device to store all data used in OpenStack and synchronize the DRBD device with Pacemaker. Another possible solution is to build Ceph clusters and again use Pacemaker as synchronization tool. An alternative to Pacemaker is keepalived which also offers synchronization and control mechanisms for Load Balancing and High Availability. And of course one could also think of using HAProxy for Load Balancing instead of Ceph or DRBD.
In short: different architectures can be modelled. How this is done will be subject of a further blog post.
2 Kommentare