Cyclops, ICCLab’s Rating-Charging-Billing solution for Cloud providers, capable of collecting usage records from both OpenStack and CloudStack, has been working with time series data from the very beginning. Our choice for database technology that is highly optimised to handle such data was InfluxDB written in GO.
Time series data is generally a sequence of data points – in our case either Usage Data Records or Charge Data Records. These datasets often have hundreds of millions of rows, including timestamps and large quantities of immutable fields. Entries do not typically change after they are added to the database, where new entries are being appended rather than operated on.
Persistence is a challenge for this kind of data, as datasets may quickly grow larger than the server’s capacity. Distributed computing overcomes this by letting sections of the dataset live on separate data nodes, perhaps even replicating them across multiple nodes.
Even though InfluxDB is currently under active development and expecting a major 1.0 release this summer, it already supports clustering, HA deployments and data replication. As can be seen in the picture below, retention policies are in place for phasing out old data automatically as it becomes less relevant.

Continuous queries are optimal for regularly downsampling data, as well as pre-computing expensive queries in real-time. InfluxDB automatically and periodically runs the query and stores the result in a measurement for future use.

During the development of RCB Cyclops it was paramount to design and optimise our database schema in order to achieve better than out-of-the-box performance – which was possible by combining InfluxData’s design guidelines, as well as understanding our data records. InfluxDB lets you specify fields and tags, both being key/value pairs where the difference is that tags are automatically indexed.
Because fields are not being indexed at all, on every query where InfluxDB is asked to find a specified field, it needs to sequentially scan every value of the field column. This behaviour is generally not preferred as it can increase response times significantly, especially on larger data sets. Of course workloads like this can be parallelised by the use of seek and limit operations on the client side. It is however more beneficial to rearrange the database schema and simply specify those fields as tags, getting constant access.
However, there is a huge caveat – a series cardinality being a major factor that affects RAM requirements. Based on the most recent InfluxDB hardware sizing guidelines, you will need around 2-4 GB of RAM for a low load with less than 100,000 unique series. Imagine that your database consists of one measurement that has only two tags, but those values are highly dynamic, both in the thousands. This would result in the need for more than 32 GB, because InfluxDB would try to construct an inverted index in memory, which would always be growing with the cardinality.
A rule of thumb would be to persist highly dynamic values as fields and only use tags for GROUP BY clauses and InfluxQL functions, carefully designing your application around it. That kind of data would otherwise mean a new series every time something is added and a large increase in the inverted index stored in memory. It is therefore necessary to think about the most common queries that will get executed, and optimise the schema accordingly. On the other hand, tag keys and values are stored only once and always as strings, where field values and timestamps are stored per-point. This however doesn’t affect the memory footprint, only the storage requirements.
The most recent InfluxDB 0.12 also offers new features for query management, in the style of “fail fast” approach. Administrators can now use these functions and specify hard limits in order to guarantee a certain level of throughput, effectively enforcing clients to retry in case of timeouts, instead of completely hogging the system.
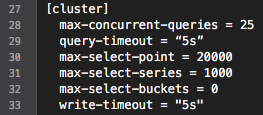
In order to effectively utilise InfluxDB’s underlying shard spaces (based on configured retention policy) the most performant write queries are those containing points with increasing timestamps. Also, sending single points is much more expensive than sending batches of 100-5000 points each.
As far as we now know, InfluxDB’s future releases intend to support time zones and geospatial functions, allowing for more responsive queries. Don’t forget to follow us on Twitter @rcb_cyclops to stay up to date on the latest RCB Cyclops development and use of time series databases in the cloud computing domain.
Very interesting read. Does this still hold true today, or do you think the rules have changed a bit (Currently using influx 1.6)