Why is service quality important?
A cloud can be seen as a service which is provided by a cloud provider and consumed by an end user. The cloud provider has the goal to maximize profit by providing cloud services to end users. Usually there are no fixed prices for using cloud services: users have to pay a variable price that depends on the consumption of cloud services. Service quality is a constraint to the cloud provider’s optimization goal of profit-maximization. The cloud provider should deliver cloud services with sufficiently good performance, capacity, security and availability and maximize his profit. Since quality costs more, a low quality cloud service is preferable to a high quality service, because it costs less. So why should profit-oriented cloud providers bother at all with quality?
A new view of service quality
In the new view, we see service quality not as a restriction to profit maximization. Cloud service quality is an enabler of further service consumption and therefore a force that increases profit of cloud providers. If we think of cloud computing as a low quality service with low degrees of availability (many outages), running slowly and in an insecure environment, one can easily see that cloud consumers will stop using the cloud service as soon as there are alternatives to it. But there is another argument in favour of using clouds with a high degree of quality of service (QoS): if cloud service consumption is performing well, it can be used more often and by more users at once. Therefore an operator of a quality cloud service can handle more user requests and at lower costs than a non-quality-oriented cloud provider.
What is quality in the cloud?
Quality can have different meanings: for us it must be measured in terms of availability, performance, capacity and security. For each of these four terms we have to define metrics that measure quality. The following metrics are used in service management practice:
- Availability: Availability can be calculated only indirectly by measuring the downtime, because outages are directly observable while normal operation of a system is not. When an outage occurs, the downtime is reported as the time difference between discovery of an outage and restoration of the service. Availability is then the ratio of total operating time minus downtime to the total operating time. Availability of a system can be tested by using the Dependability Modeling Framework, i. e. a series of simulated random outages which tell system operators how stable their system is.
- Performance: Performance is usually the tested by measurement of the time it takes to perform a set of sample queries in a computer program. Such a time measurement is called a benchmark test. Performance of a cloud service can be measured by running multiple standard user queries and then measure their execution time.
- Capacity: By capacity we mean storage which is free for service consumption. Capacity on disks can be measured directly by checking how much storage is used and how much storage is free. If we want to know how much working memory must be available, the whole measurement becomes a little bit more complicated: we must measure memory consumption during certain operations. Usually this can be done by profiling the system: like in benchmarking we run a set of sample queries and measure how much memory is consumed. Then we calculate the memory which is necessary to operate the cloud service.
- Security: Security is the most abstract quality indicator, because it can not be measured directly. A common practice is to create a vector of potential security threats and estimate the probability that a threat will lead to an attack and estimate the potential damage in case of an attack. Threats can be measured as the product of the attack probability and the potential of a damage. The goal should be to mitigate the biggest risks with a given budget. A risk is mitigated when there are countermeasures against identified security threats (risk avoidance), minimization measures for potential damages (damage minimization), transfer of security risks to other organizations (e. g. insurances) and (authorized) risk acceptance. Because nobody can know all potential threats in advance there is always an unknown rest risk which cannot be avoided. Security management of a cloud service is good, when the security threat vector is regularly updated and the worst risks are mitigated.
The given metrics are a good starting point for modelling service quality. In optimization there are two types of models: descriptive models and optimization models.
A descriptive model of service quality in the cloud
Descriptive models describe how a process is performed and are used to explore how the process works. Usually descriptive models answer “What If?”-questions. They consist in an input of variables, a function that transforms the input in output and a set of (unchangeable) parameters that influence the transformation function. A descriptive model of cloud service quality would describe how a particular configuration of service components (service assets like hardware, software etc. and management of the service assets) delivers a particular set of output in terms of service quality metrics. If we can e. g. increase availability of the cloud service by using a recovery tool like Pacemaker, a descriptive model is able to tell us how the quality of the cloud service changes.
Sets are all possible resources we can use in our model to produce an outcome. In OpenStack we use hardware, software and labour. Parameters are attributes of the set entities which are not variable: e. g. labour cost, price of hardware assets etc. All other attributes are called variables: The goal of the modeler is to change these variables and see what comes out. The outcomes are called consequences.
A descriptive model of the OpenStack service could be described as follows:
- Sets:
- Technology used in the OpenStack environment
- Hardware (e. g. physical servers, CPU, RAM, harddisks and storage, network devices, cables, routers)
- Operating system (e. g. Ubuntu, openSUSE)
- Services used in OpenStack (e. g. Keystone, Glance, Quantum, Nova, Cinder, Horizon, Heat, Ceilometer)
- HA Tools (e. g. Pacemaker, Keepalive, HAProxy)
- Monitoring tools (e. g.
- Benchmark tools
- Profiling tools
- Security Tools (e. g. ClamAV)
- Management of the OpenStack environment
- Interval of availability tests.
- Interval of performance benchmark tests.
- Interval of profiling and capacity tests.
- Interval of security tests.
- Interval of Risk Management assessments (reconsideration of threat vector).
- Technology used in the OpenStack environment
- Parameters:
- Budget to run the OpenStack technology and service management actions
- Hardware costs
- Energy costs
- Software costs (you don’t have to pay licence fees in the Open Source world, but you still have maintenance costs)
- Labor cost to handle tests
- Labor costs to install technologies
- Labor costs to maintain technologies
- Price of technology installation, maintenance and service management actions
- Price of tangible assets (hardware) and intangible assets (software, energy consumption)
- Salaries, wages
- Quality improvement by operation of particular technology or by performing service management actions
- Price of tangible assets (hardware) and intangible assets (software, energy consumption)
- Salaries, wages
- Budget to run the OpenStack technology and service management actions
- Variables:
- Quantities of a particular technology which should be installed and maintained:
- Hardware (e. g. quantitity of physical servers, CPU-speed, RAM-size, harddisks and storage size, number of network devices, speed of cables, routers)
- Operating system of each node (e. g. Ubuntu, openSUSE)
- OpenStack services per node(e. g. Keystone, Glance, Quantum, Nova, Cinder, Horizon, Heat, Ceilometer)
- HA Tools per node (e. g. Pacemaker, Keepalive, HAProxy)
- Monitoring tools (e. g.
- Benchmark tools
- Profiling tools
- Security Tools (e. g. ClamAV)
- Quantities of a particular technology which should be installed and maintained:
- Consequences:
- Costs for installation and maintenance of the OpenStack environment:
- Infrastructure costs
- Labour costs
- Quality of the OpenStack service in terms of:
- Availability
- Performance
- Capacity
- Security
- Costs for installation and maintenance of the OpenStack environment:
In the following picture we show a generic descriptive model for optimization of quality of an IT service:
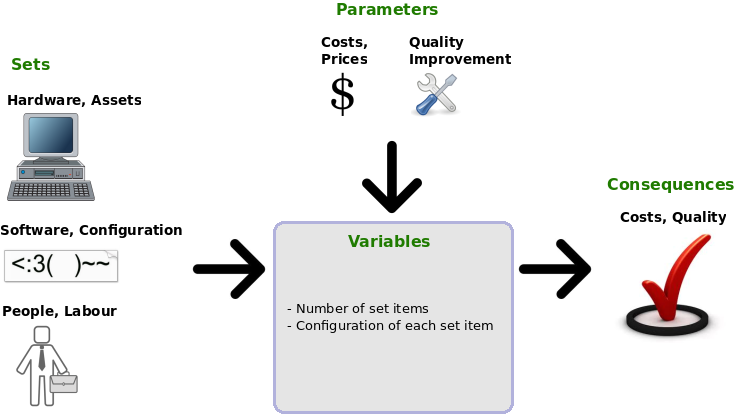
Such a descriptive model is good to exploit the quality improvements delivered by different system architectures and service management operations. The input variables form a vector of systems and operations: Hardware, network architecture, operating systems, OpenStack services, HA tools, benchmark tools, profiling monitors, security software and service operations performed by system administrators. One can experiment with different systems and operations and then check the outcomes. The outcomes are the costs (as a product of prices and systems) and the service quality. The service quality is then measured by our metrics we have defined.
Even if the descriptive model is quite useful, it is very hard to actually optimize service quality. Therefore the descriptive model has to be extended to an optimization model.
An optimization model of service quality in the cloud
Optimization models enhance descriptive models by adding constraints to the inputs of the descriptive model and by defining an objective function. Optimization models answer “What’s Best?”-questions. They consist in an input of variables, a function that transforms the input in output and a set of (unchangeable) parameters that influence the transformation function. Additionally they contain constraints that restrict the number of possible inputs and an objective function which tells the model user what output should be achieved.
An optimization model of the OpenStack service could be described as follows:
- Sets:
- Technology used in the OpenStack environment
- Hardware (e. g. physical servers, CPU, RAM, harddisks and storage, network devices, cables, routers)
- Operating system (e. g. Ubuntu, openSUSE)
- Services used in OpenStack (e. g. Keystone, Glance, Quantum, Nova, Cinder, Horizon, Heat, Ceilometer)
- HA Tools (e. g. Pacemaker, Keepalive, HAProxy)
- Monitoring tools (e. g.
- Benchmark tools
- Profiling tools
- Security Tools (e. g. ClamAV)
- Management of the OpenStack environment
- Interval of availability tests.
- Interval of performance benchmark tests.
- Interval of profiling and capacity tests.
- Interval of security tests.
- Interval of Risk Management assessments (reconsideration of threat vector).
- Technology used in the OpenStack environment
- Parameters:
- Budget to run the OpenStack technology and service management actions
- Hardware costs
- Energy costs
- Software costs (you don’t have to pay licence fees in the Open Source world, but you still have maintenance costs)
- Labor cost to handle tests
- Labor costs to install technologies
- Labor costs to maintain technologies
- Price of technology installation, maintenance and service management actions
- Price of tangible assets (hardware) and intangible assets (software, energy consumption)
- Salaries, wages
- Quality improvement by operation of particular technology or by performing service management actions
- Price of tangible assets (hardware) and intangible assets (software, energy consumption)
- Salaries, wages
- Budget to run the OpenStack technology and service management actions
- Variables:
- Quantities of a particular technology which should be installed and maintained:
- Hardware (e. g. quantitity of physical servers, CPU-speed, RAM-size, harddisks and storage size, number of network devices, speed of cables, routers)
- Operating system of each node (e. g. Ubuntu, openSUSE)
- OpenStack services per node(e. g. Keystone, Glance, Quantum, Nova, Cinder, Horizon, Heat, Ceilometer)
- HA Tools per node (e. g. Pacemaker, Keepalive, HAProxy)
- Monitoring tools (e. g.
- Benchmark tools
- Profiling tools
- Security Tools (e. g. ClamAV)
- Quantities of a particular technology which should be installed and maintained:
- Constraints:
- Budget limitation for installation and maintenance of the OpenStack environment:
- Infrastructure costs
- Labour costs
- Technological constraints:
- Incompatible technologies
- Limited knowledge of system administrators
- Objective Function:
- Maximization of service quality in terms of:
- Availability
- Performance
- Capacity
- Security
- Maximization of service quality in terms of:
- Budget limitation for installation and maintenance of the OpenStack environment:
The following picture shows a generic optimization model for an IT service:
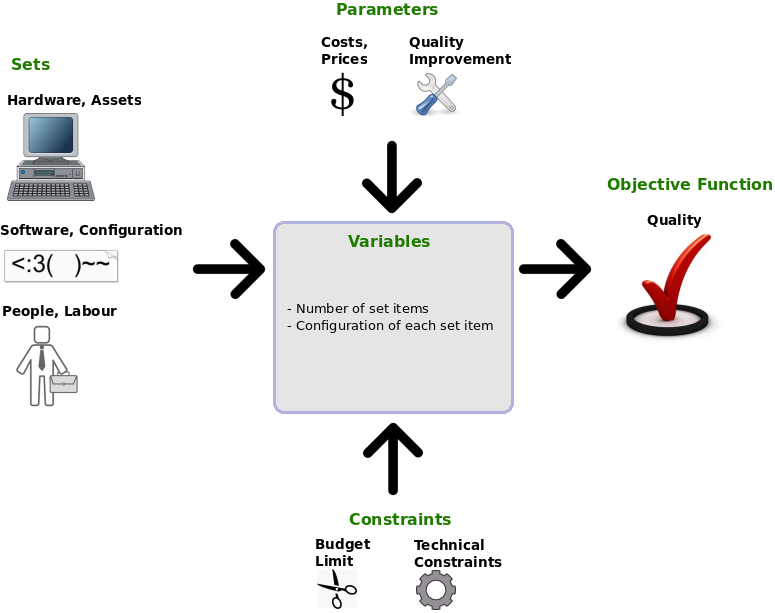
With such an optimization model at hand we are able to optimize service quality of an OpenStack environment. What we need are clearly defined values for the sets, parameters, constraints and objective functions. We must be able to create a formal notation for all model elements.
What further investigations are required?
The formal model can be created if we get to know all information required to assign concrete values to all model elements. This infomration is:
- List of all set items (OpenStack system environment plus regular maintenance operations): First we must know all possible values for the systems and operations used in our OpenStack environment. We must know which hardware, OS and software we can use to operate OpenStack and which actions (maintenance) must be performed regularly in order to keep OpenStack up and running.
- List of all parameters (costs of OpenStack system environment elements, labour cost for maintenance operations and quality improvement per set item): In a second step we must obtain all prices for our set items. This means we must know how much it costs to install a particular hardware, OS or software and we must know how much the maintance operations cost in terms of salaries. Additionally we must know the quality improvement which is delivered per set item: this can be done by testing the environment with and without the item (additional system or service operation) and using our quality metrics.
- List of constraints (budget limit and technical constraints): In a third step we must get to know the constraints, i. e. budget limits and technical constraints. A technical constraint can be a restriction like that you can use only one profiling tool.
- Required outcomes (targeted quality metric value maximization): Once we know the sets, parameters and constraints, we must define how quality is measured in a function. Again we can use our quality metrics for that.
- Computation of optimal variable values (which items should be bought): Once we know all model elements, we can compute the optimal variables. Since we will not get a strict mathematical formula for the target function and since we may also work with incomplete information, it is obvious that we should use a metaheuristic (like e. g. evolutionary algorithms) to find a way on how to optimize service quality.
We have seen that creating a model for service quality optimization in the cloud requires a lot of investigation. Some details about it will be revealed in further articles.