With this post we are going to start a new series on Distributed File Systems. We are going to start with an introduction to a file system that is enjoying a good amount of success: Ceph.
Ceph is a distributed parallel fault-tolerant file system that can offer object, block, and file storage from a single cluster. Ceph’s objective is to provide an open source storage platform with no Single-Point-of-Failure, highly available and highly scalable.
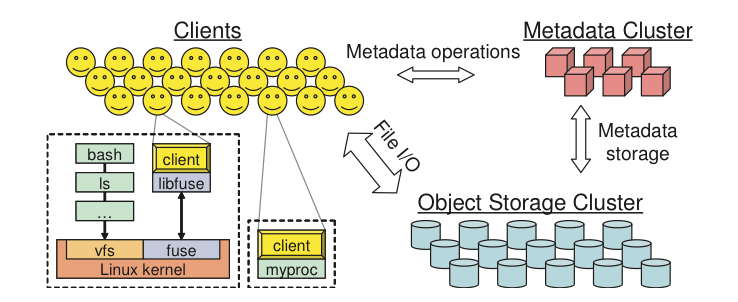
A Ceph Cluster has three main components:
- OSDs. A Ceph Object Storage Devices (OSD) are the core of a Ceph cluster and are in charge of storing data, handling data replication and recovery, and data rebalancing. A Ceph Cluster requires at least two OSDs. OSDs also check other OSDs for a heartbeat and provide this information to Ceph Monitors.
- Monitors: A Ceph Monitor keeps the state of the Ceph Cluster using maps, e.g.. monitors map, OSDs map and the CRUSH map. Ceph also maintains a history, also called an epoch, of each state change in the Ceph Cluster components.
- MDSs: A Ceph MetaData Server (MDS) stores metadata for the Ceph FileSystem client. Thanks to Ceph MDSs, POSIX file system users are able to execute basic commands such as ls and find without overloading the OSDs. Ceph MDSs can provide both metadata high-availability, i.e. multiple MDS instances, at least one in standby – and scalability, i.e. multiple MDS instances, all active and managing different directory subtrees.
{kind=link}
One of the key feature of Ceph is the way data is managed. Ceph clients and OSDs compute data locations using a pseudo random algorithm called Controlled Replication Under Scalable Hashing (CRUSH). The CRUSH algorithm distributes the work amongst clients and OSDs, which free them from depending on a central lookup table to retrieve location information and allow for a high degree of scaling. CRUSH also uses intelligent data replication to guarantee resiliency.
Ceph allows clients to access data through different interfaces:
- Object Storage: The RADOS Gateway (RGW), the Ceph Object Storage component, provides RESTful APIs compatible with Amazon S3 and OpenStack Swift. It sits on top of the Ceph Storage Cluster and has its own user database, authentication, and access control. The RADOS Gateway makes use of a unified namespace, this means that you can write data using one API, e.g. Amazon S3-compatible API, and read them with another API, e.g. OpenStack Swift-compatible API. Ceph Object Storage doesn’t make use fo the Ceph MetaData Servers.
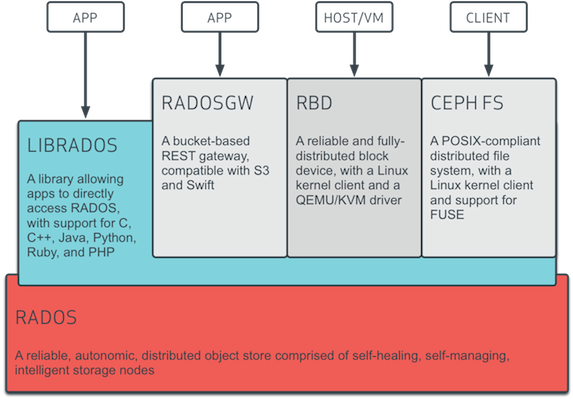
- Block Devices: The RADOS Block Devices (RBD), the Ceph Block Device component, provides resizable, thin-provisioned block devices. The block devices are striped across multiple OSDs in the Ceph cluster for high performance. The Ceph Block Device component also provides image snapshotting and snapshots layering, i.e. cloning of images. Ceph RBD supports QEMU/KVM hypervisors and can easily be integrated with OpenStack and CloudStack (or any other cloud stack that uses libvirt).
- Filesystem: CephFS, the Ceph Filesystem component, provides a POSIX-compliant filesystem layered on top of the Ceph Storage Cluster, meaning that files get mapped to objects in the Ceph cluster. Ceph clients can mount the Ceph Filesystem either as a Kernel object or as a Filesystem in User Space (FUSE). CephFS separates the metadata from the data, storing the metadata in the MDSs, and storing the file data in one or more OSDs in the Ceph cluster. Thanks to this separation the Ceph Filesystem can provide high performances without stressing the Ceph Storage Cluster.
Our next topic in the Distributed File Systems Series will be and introduction to GlusterFS.
2 Kommentare