We continue our recent work regarding an analysis of the performance of live migration in Openstack Icehouse. Our previous results focused on block live migration in Openstack, without shared storage configured between computing nodes. In this post we focus on the performance of live migration in the system with a shared file system configured, compare it with block live migration and try to determine scenarios more suitable for each approach. [Note that in the above, when live migration implies shared storage based live migration; block live migration is explicit as in the Openstack literature on this topic].
[Also note that all VMs in following experiments use 5GB of disk space]
All system configuration and testing aspects (except amended flavors) remain the same as in previous block live migration tests (see here for more details). The only infrastructure change in our small 3 node configuration is the shared file system setup. We used an NFS server running on the controller node to provide its ../nova/instances folder as a mount point for the compute nodes.
Unloaded case
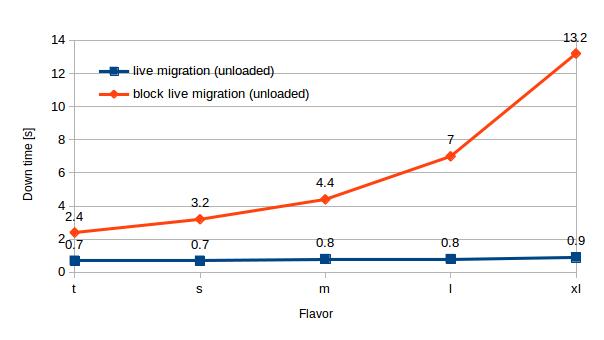
Let’s start with the time taken by live migrations of unloaded VMs. In chart 1 we see a small increase of migration time with larger VM flavors, which is not so surprising. More interestingly the down time stays almost constant (< 1 s) and doesn’t grow with the migration time unlike the case of block live migration.
| t | s | m | l | xl | |
| Migration time (unloaded) | 4.9 | 5.6 | 7.0 | 9.6 | 15.3 |
| Down time (unloaded) | 0.7 | 0.7 | 0.8 | 0.8 | 0.9 |
Table 1 – Live migration duration & down time
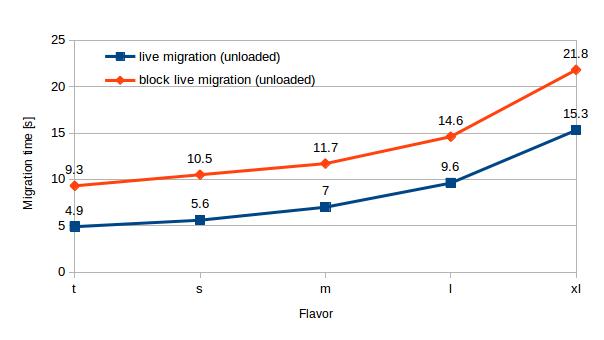
In all cases with shared storage, live migration of unloaded VMs exhibits significantly lower migration time and downtime than block live migration. More precisely, the NFS live migration time is on average only 60% of the block live migration time (see chart 2). VM down time is on average 17% of the down time using block migration (see chart 3) and is less than 1 s in our experiments.
| t | s | m | l | xl | |
| Live migration (unloaded) | 4.9 | 5.6 | 7.0 | 9.6 | 15.3 |
| Block live migration (unloaded) | 9.3 | 10.5 | 11.7 | 14.6 | 21.8 |
Table 2 – Migration time (unloaded) – live migration vs. block live migration
| t | s | m | l | xl | |
| Live migration (unloaded) | 0.7 | 0.7 | 0.8 | 0.8 | 0.9 |
| Block live migration (unloaded) | 2.4 | 3.2 | 4.4 | 7.0 | 21.5 |
Table 3 – Down time (unloaded) – live migration vs. block live migration
In the unloaded VM scenario, the amount of data transferred over the network increases with the VM size, however even these values are significantly smaller than in the block live migration case: Network traffic is 11 – 30% lower in the storage based migration case, than the block migration case.
| t | s | m | l | xl | |
| Live migration (unloaded) | 175 | 190 | 288 | 315 | 480 |
| Block live migration (unloaded) | 239 | 271 | 324 | 404 | 669 |

Loaded case
Behaviour of live migration for loaded machines was a little more complex.
Using the block live migration we successfully migrated VMs across all flavors even when they were quite heavily loaded – in our tests, we focused on memory load (as described here) and we achieved successful migration even when they were approximately 75% loaded. However, shared storage based live migration was more sensitive to memory load. In fact, we couldn’t migrate even a tiny flavor VM with a relatively small memory load – 100 MB of stressed memory (out of total 512 MB). Migration was initiated but didn’t end until the load was terminated. Consequently, we can’t present results which are directly comparable to the block live migration for this loaded case.
To have a better understanding why we face this problem of non deterministic migration time we need to dive a bit deeper into the migration mechanism. In our configuration of Openstack with QEMU/KVM and libvirt, the live migration uses pre-copy memory approach. This consists of following steps:
- Copy source VM memory to destination. This operation takes some time while VM is still running (and some memory pages are changing) at the source.
- Repeat step 1 (copy changed memory pages) until amount of dirty memory is small enough and can be transferred in very short VM downtime
- Stop VM at source and copy the rest of dirty memory
- Start VM at destination
The problem arises at the point 2: if the VM memory is dirtied faster than it can be transferred to destination then this step will never terminate.. Therefore, whether a migration is a success or failure depends on the available network capacity and the current VM memory load.
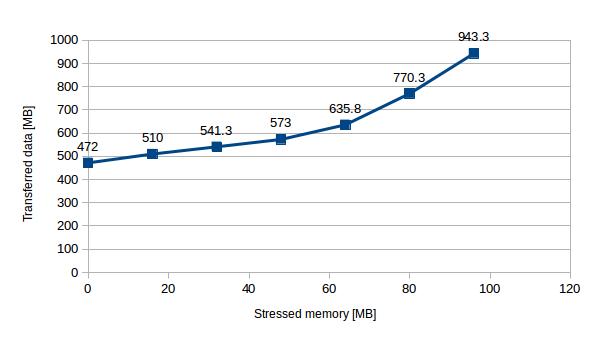
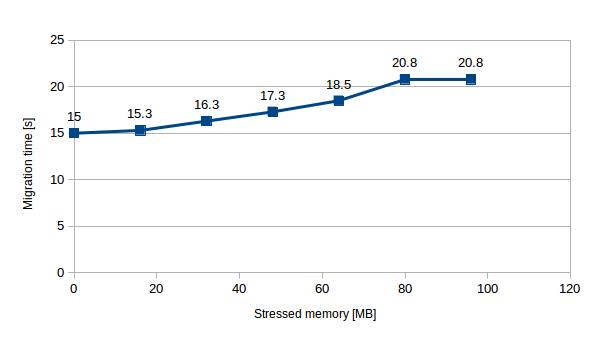
To explore this further, we considered VMs with different memory load and examined how it affects migration time and the amount of transferred data. Up to a stress level of 96 MB all migrations were successful with relatively small constant downtime (<1 s) and short migration duration (mostly < 20 s). However, beyond this point the VM got stuck in a migration state and doesn’t stop migrating (until it is either killed or the memory load reduced). The real measured throughput in our network was approximately 110 MB/s, that’s why we could migrate VM with lower memory load than this value and we failed with VMs, where the stress rate of memory exceeded this threshold.
| Stressed memory [MB] | 0 | 16 | 32 | 48 | 64 | 80 | 96 |
| Migration time [s] | 15.0 | 15.3 | 16.3 | 17.3 | 18.5 | 20.8 | 20.8 |
Table 5 – Migration time with different levels of stress
| Stressed memory [MB] | 0 | 16 | 32 | 48 | 64 | 80 | 96 |
| Data transferred [MB] | 472 | 510 | 541 | 573 | 635 | 770 | 943 |
Table 6 – Data transfer with different levels of stress
Take aways
Openstack live migration is fast technique how to transfer running VM from one host to another with a small downtime. But since its duration is non deterministic and there is no guarantee that migration process finishes successfully, care must be taken when employing this approach and your particular network configuration and load as well as the VM activity must be considered.
Key take aways from our experiments are:
- Live migration can be faster and the downtime lower than in case of block live migration but it can be unreliable in the case that the VM has memory intense activity. In our experiments, downtime was low (<1s) and migration time took seconds to some few 10’s of seconds.
- Block live migration exhibited better reliability but longer migration times and VM downtimes (up to some 100’s of seconds in both cases);
- In both cases, a significant network load can be imposed on the system – this needs to be borne in mind and indeed the results presented above do not take into account typical network activity within a cluster: when this is taken into account live migration is likely to be even less reliable.
Live migration is a useful tool in operating and optimizing your cloud infrastructure; however, it is inherently complex and must be used with care.
In future work, we will consider further scenarios where we test live migration, which are closer to real world conditions. We are also investigating the use of post-copy migration and how it may perform.
how to know the downtime? in log or use the tool?
Hello, we pinged the VM from external machine and simply calculated lost packets * interval. It’s more a simulation of how long is the machine unavailable for external guests during the LM.
Hello, I’m a student who study Openstack.
My result of downtime is 2.5s~3.0s…. but your result is 0.7s~0.9s in Table1.
I want to reduce downtime less than 1.0s…………
What can i do for improving this result????? please help me….. please……..
(I’m sorry that I can’t speak English well)
Hello,
unfortunately Openstack doesn’t provide any option to set up desired maximum downtime for the live migration. You can try to set up maximum downtime for the domain you want to migrate using libvirt “virsh qemu-monitor-command –hmp [domain_id] ‘migrate_set_downtime [t]'”, where [t] is maximum desired downtime in seconds and [domain_id] your domain id.
Using out-of-the-box qemu/libvirt/openstack live migration solution you might face and issue with live migration non-deterministic convergency if you set the downtime too small / vm memory change rate too high.
Please also note that higher “downtime” using the ping can be also caused by slower network adaption after the migration. (Since VM is placed somewhere else, this change needs to be noted by the network infrastructure). That means that although the VM is already up and running on the destination it can still appear unavailable for machines running somewhere else.
Hope it helped.
Cheers!
Thank for your kind answer T.T
If i have any question, could i ask you about live migration again??
Thank you very much!
I am trying to resize a VM instance(change flavor) on one of the nodes, which is upon OpenStack KVM Hypervisor.
I need to resize the instance without rebooting it. I did not find any commands which would resize the instance without rebooting. Libvirt API does increase the size of VM till its maximum memory in the flavor, but it doesnt change the flavor to higher one.
Can any one help me in changing the flavor name dynamically without rebooting the instance ?
Thanks !
Hi,
As you showed, step 2 in pre-copy procedure:
Repeat step 1 (copy changed memory pages) until amount of dirty memory is small enough and can be transferred in very short VM downtime
I wonder how much the “small enough memory” and the “very short VM downtime” are. Are those pre-defined by OpenStack, or could we configure them (I assume the answer is no, according to your previous comments)
I could also see that the downtime results in your experiments are very small (<1s), which means the memory dirtying rate is small and constant, I assume. Could you tell me what tools did you use to stress memory?
Thank you
Hello Victor,
libvirt enables to set up maximal tolerable downtime (virsh migrate-setmaxdowntime domain downtime_in_ms). As this option is not available in Horizon (nor Nova CLI) it targets the default value – 1 second. Then based on your network throughput the migration algorithm can estimate how much data can be transferred within this time unit and once the remaining amount of memory to be transferred is less than that value, the handover (downtime) happens.
We used stress tool (http://linux.die.net/man/1/stress). Currently I would recommend using stress-ng (http://kernel.ubuntu.com/~cking/stress-ng/) as it provides more fine grinded setting options.
I think you listed the wrong data for the block migration time from your previous article.
Hello, I just double checked and it seems to be correct. Could you please elaborate further on which data points bothers you? Thank you.
Hi ICCLAB team, I really like your work and will like to know more about your results. How did you measure the downtime of the VMs unloaded ? Can you please explain your method. Thanks
Armstrong
Hi,
I wonder if you mind explaining how you measure live migration duration. I’m conducting some straightforward experiment on an small Openstack deployment on three node regarding performance interference of VMs & I wanna take into observation this metric too. Would you please tell me how I can measure live migration duration, any simple method or tools?
Thank you in advance.
Hi!
I am a student who is studying openstack.I am using openstack of the version m.
what I know is the M version has only the pre copy,if I want to use post copy,what should I do?
please help me…my teacher is strict with mine….
Thanks!
hi
how to measure downtime and migration time while vm migrate ??
which software uses for this paper plot to show migration time and downtime?