As we have recently been granted Google Cloud Research Credits for the investigation of Serverless Data Integration, we continue our exploration of open and public data. This HOWTO-style blog post presents the application domain of financial analytics and explains how to run a cloud function to achieve elastically scalable analytics. Although there are no research results to report yet, it raises a couple of interesting challenges that we or other computer scientists should work on in the future.
Financial analytics is a field full of acronyms not dissimilar to ICT. It is concerned with insights into foreign exchange currency rates (FX), the LBMA-determined precious metal rates, and various other investment instruments, but also personal finance. The analytics part includes pattern and trends analysis, forecasts and predictions, and recommendations on decisions to take. Although there is a distinct lack of a high-quality, up-to-date data source for this kind of analytics, many APIs and websites exist to get access to some of the information with no or just a few hurdles.
From a data (stream) integration perspective, we would like to explore the possibility to run queries via FaaS. The FaaS execution model allows for short-running but massively parallelisable services, making it a suitable model for time-bounded queries. Our ingredients are therefore:
- A cloud function implementation along with configuration.
- A dataset with historic exchange records.
- A FaaS runtime where to execute everything.
To make the application design more interesting, we build a hybrid CLI/FaaS application. Typically, CLIs cannot be run in FaaS and vice-versa. A hybrid design simply has two entry points, the obligatory main function that reads command-line parameters (CLI) and another function that reads trigger-dependent parameters (FaaS). For simplicity, we choose an HTTP GET trigger, although POST or entirely different triggers would be possible as well.
Following our always pragmatic applied research approach of deploying the application whereever we can run it for free, we deploy it into Google Cloud Functions which comes with straightforward HTTP trigger support. In order to avoid having to deal with a database, we supply a ZIP file that contains the code and data as follows:
- A Python file
main.py(other languages are possible) with the main code, the cloud function, and a class definition with methods for the business logic, including input/output in JSON format (again, other formats are possible). - A
requirements.txtfile so that the Pandas library is installed. Pandas is not supported by the default environment of GCF, but can be trivially installed by specifying it that way. - A folder with data files containing the FX rates per day. Scanning them takes a bit, but is likely still of lower latency than connecting to a database, so for simplicity we keep it that way.
- Eventually, a ZIP file in which the main script file is located on the topmost level; moving it into subfolders will not work.
The subsequent deployment is shown in the following screen. For our purposes, the minimum memory allocation of 128 MB ought to be enough for everyone.
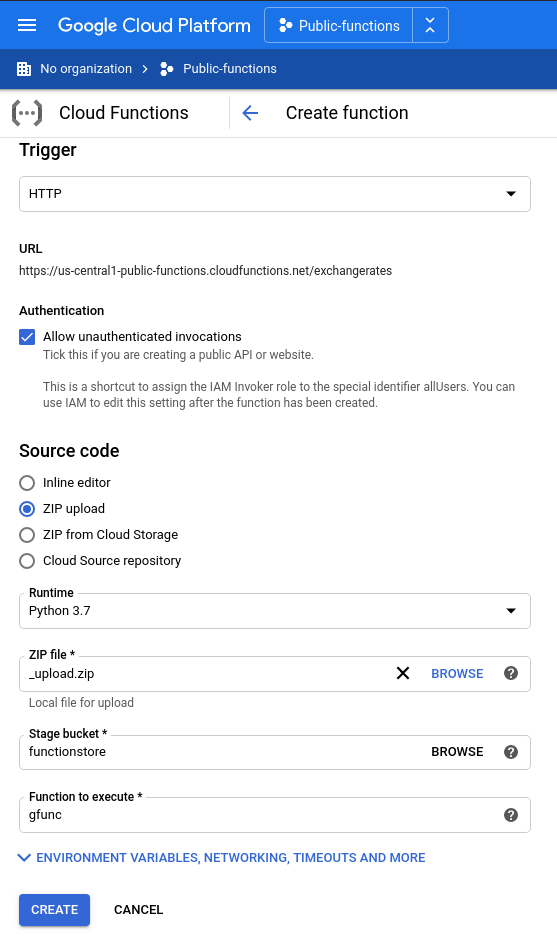
Invoking the function leads to the desired results. We first query the supported range of dates, and then query by how much currencies have become cheaper or more expensive relative to the venerable CHF.
curl https://us-central1-public-functions.cloudfunctions.net/exchangerates?dates
{"start": "2020-04-09", "end": "2020-04-21"}
$ curl https://us-central1-public-functions.cloudfunctions.net/exchangerates?fromdate=2020-04-14
{"AED": 0.89, "AUD": -0.75, ..., "USD": 0.49, "ZAR": 0.0}The hybrid CLI/cloud function implementation is available from our functions collection which has received occasional new functions in the past and will continue to do so in the next months.
As we strive towards rapid (and still high-quality) prototyping of cloud-native applications, we observe some needlessly effort-intensive steps and moreover a potential of improvement in general as follows:
- Smarter detection of where the main function is. A recursive scanning into archives is quite trivial, especially when combined with an interactive deployment wizard that simply asks when no deterministic choice can be made. Otherwise, a redeployment of the entire function is necessary which together with the time of being puzzled and finding the mistake takes much longer in comparison.
- Convincing rate limiting and per-host request threshold support. For rapid scenarios, nobody likes fiddling with credentials. Yet opening APIs to the world requires careful regular examination of the utilisation level of the function. For PaaS, we have proposed workarounds, although for FaaS, these would be less trivial to implement and would double the cost due to function request forwarding. With rate limiting, one would simply make the API public and sleep well, knowing that in alignment with the serverless mindset/philosophy, just like memory leaks or hanging processes the problem will eventually fix itself.
- More fine-grained, and possibly autotuned, memory allocation. We have also investigated this issue in the past. We understand that this problem divides into two sub-problems: More fine-grained limits at the FaaS level, and dynamic reconfiguration at the container level.
- Related to the above, a configurable level of isolation. Full container isolation is great for production, but the deployment and initial execution steps are relatively slow, or at least slow enough to see the spinning wheel as a user of the FaaS system. A flexible FaaS system would offer different instance types depending on the needs of the users, which includes rapid prototypers, researchers, students and others without a need for full isolation in all situations.
With this work, it has become clear that FaaS is simple, although not yet simple enough, and that the Seychelles Rupee has lost around 12% of value in recent days compared to the CHF which warrants further investigation on why that would be the case. We leave this investigation to the luminaries in economics and continue to focus on making serverless, cloud and continuum computing better and more usable for all industrial sectors.