With the increased adoption of serverless computing, so is the need to optimise cloud functions, to make use of resources as efficiently as possible, and to lower the overall costs in the end. At the Service Prototyping Lab at Zurich University of Applied Sciences, we investigate how cloud application and platform providers can achieve a fairer billing model which comes closer to actual utility computing where you pay only for what you really use. We demonstrate our recent findings with AWS Lambda function pricing.
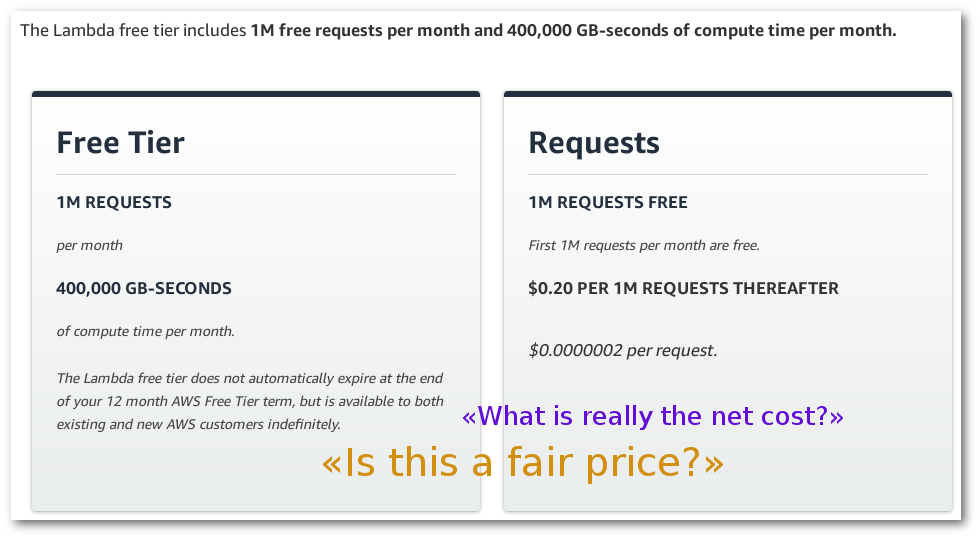
Most Faas providers charge based on allocated memory, elapsed time and number of requests. So an accurate measurement of these would be a great start to calculate the costs and find ways to minimise it.
Because one of the most widely used FaaS providers is AWS Lambda, it makes sense to use its pricing as a starting point. It also makes sense to check what would happen if the function stats do not exactly fit into one of the designated price points. How much of a difference would it make cost wise?
AWS Lambda charges by GB-s and by number of requests. The minimum amount of memory to allocate to a function is 128MB (with 64MB increments from there), and the minimum time is 100ms. Meaning that for a function that runs on, say 50MB and takes 105ms, it would cost the same as a function using 128MB and 200ms.
To showcase how much time and memory is being allocated -and paid- but not used (wasted), a few prototype scripts were developed. In essence, they check the difference between the real AWS Lambda cost and the net cost should the price be charged by smaller time and memory granularities.

How it works:
At the same time the container is started, a bash script that monitors the container is also started. Around every 30ms the current memory consumption is stored in a .csv, along with a timestamp. When the container finishes, the values of maximum memory consumption and elapsed time are calculated, based on the stored memory values along the way, and the start and finish times provided by docker inspect.
Then, another script is run to calculate the monetary cost, in this case, of AWS Lambda functions. A file with reference costs is used to get the right prices and free compute time and requests for each memory tier. A net cost is also calculated, that is, the price AWS would charge if the exact measured time and memory were used, instead of rounding up to the nearest 64MB tier and 100ms interval. From these two values, some interesting percentages can be derived: How much does the cost increase because of memory waste, and how much because of time waste. The time and memory waste are also displayed.
Finally a plot can be made from the generated .csv with yet another script, showing the actual usage of memory over time of the function, and the memory and time costs incurred according to AWS Lambda.
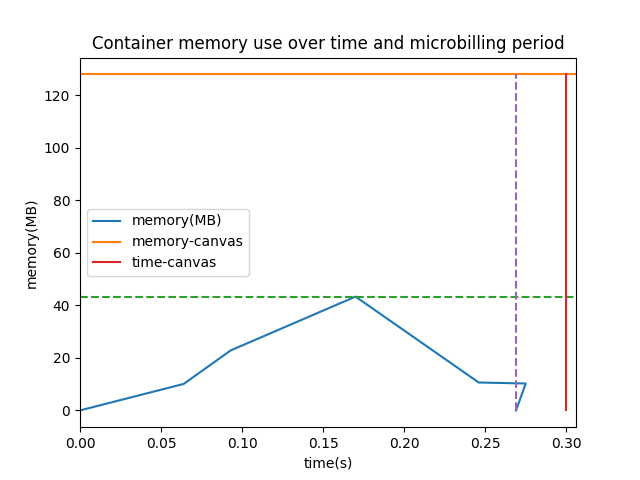
The example used is resize by fyle, resizing a 1 MB image to 50% of its original size. As the figure clearly shows, more than half of the price corresponds to virtual (microbilling) and actual (memory allocation) overhead. Both would be avoidable with more advanced function execution models. More information about the example can be found in the tool’s readme file.