For software development to succeed in Switzerland, that is to justify the relatively high development cost, it is essential to offer unique advantages in terms of timeliness and quality assurance. At Zurich University of Applied Sciences, we are proud to have contributed a number of tools for quality assessment and linting especially for cloudware – among others, the first Docker Compose checker, the first multi-Dockerfile linter, and the first advanced Helm and SAM consistency scans.
As we also teach Python programming to first-year engineering students, we consider it important to encourage the frequent use of linting tools. This blog post introduces such a service, naturally doubling as informal case study on how to deliver SaaS linting functionality without much effort through serverless technologies.
Linting is popular with the relatively straightforward syntax of Python, and a variety of tools and preferences exist. Many tools combine others, although that does not always work. Flake8, for instance, wraps around PyFlakes, pycodestyle, and a McCabe metrics calculation script. PyLama, on the other hand, is supposed to also run PyLint but on a default Ubuntu Python 3.7 installation it does not, and some other tools are only considered when adding command line options. None of the tools are installed by default on either vanilla Python desks or on data-science-oriented Anaconda/Spyder workplaces. All of this presents a barrier, especially for people just diving into the world of programming for the first time and still fighting with the differences between keywords, functions and data types.
Thus, we anticipate a simple and convenient web-based Superflake-as-a-Service offering that would integrate the existing linters, in particular Flake8 and PyLint, into a merged view with coloured inline warnings. Load site through bookmark, paste your Python code and get advice on how to improve it – that simple.
FaaSification
The application functionality is indeed simple and does not require any state – good prerequisites for being served and elastically scaled in serverless terms. There are three main ways to engineer a serverless application:
- Manually crafting and composing cloud functions.
- Using generic FaaSification tools to chunk monolithic legacy code into interconnected cloud functions.
- Creation of a web application and transformation into a fat function or container, for which specific FaaSification tools and manual methods exist.
For this Superflake service, we chose the third approach and built a Flask-based application to boot with. (Flask is a web framework for Python; see our previous posts on using Flask in cloud-native environments.) Although the service invokes linters as external tools and could thus be created in any language, choosing Python is still a good choice for wide tool support and for potentially integrating syntax/AST-level checks in-process in the future. To increase usefulness, beside offering the service on localhost or on any server we deploy it to it also includes a CLI invocation mode, but that one is not of concern in this post.
We investigated two paths from a self-hosted web service to an always-on managed cloud service: Derivation of a Flask-wrapping cloud function with Zappa, that implies hosting the function on AWS Lambda along with API Gateway; and packaging the Flask application into a Docker container and serving it through OpenWhisk/IBM Cloud Functions or Google Cloud Run. We chose the latter, for pragmatic/pecuniar reasons. (Disclaimer: This material is based upon work supported by Google Cloud, with GCP Research Credits for Serverless Data Integration. It is also based on a free (for us) AWS Educate account for serverless and cloud-native application development.)
To cut a long story short – here the Superflake service runs on KNative. Read below for details.
Serving through Google Cloud Run
Google divides its serverless offerings into two main products – Cloud Functions as traditional FaaS that works with code-level functions similar to PaaS, and for some of them now requires the Cloud Build API, and Cloud Run that uses KNative Serving atop Kubernetes to schedule short-lived container invocations, permitting scaling down to zero instances in contrast to conventional PaaS/CaaS. Note how this is different from IBM Cloud Functions that offers both code-level functions and Docker container serving within the same product.
To turn a Flask app into a Cloud Run service, the following steps are necessary:
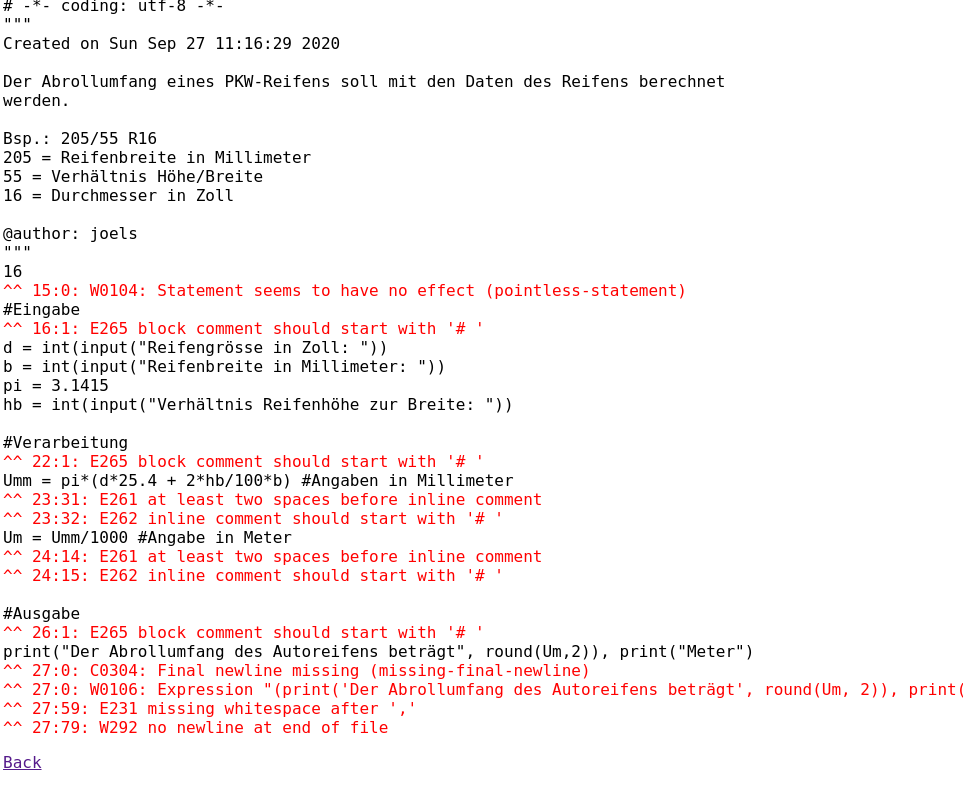
- Preparation for dynamic serving. Instead of hardcoding the port number to 8080, this should only be the fallback, with the environment variable
$PORTtaking precedence. - Creation of a Dockerfile. This could for instance derive from the
python:3-slimbase image and add through pip the Flask framework and the linting dependencies. An example is shown below. - Building the Dockerfile and pushing it to the Google container registry, e.g.
gcr.io/superflake/superflake. This requires all sorts of permission/login things, among others the presence of the thedocker-credential-gcloudtool from the Google Cloud SDK in$PATHor else weird error messages ensue. - Deploying in Google Cloud Run with the right characteristics. For a simple Flask app that uses Flask’s own single-threaded web server, the permitted concurrent requests should be set to 1 (
containerConcurrency: 1in KNative parlance) so that any parallel request will rather result in a second container to be started instead of having to wait for the first one to finish. (Is this really faster? This is surely unverified knowledge and could lead to another investigation!)
The Dockerfile:
FROM python:3-slim
RUN pip3 install flask flake8 pylint
COPY superflake.py /opt
CMD ["python3", "/opt/superflake.py", "web"]The KNative configuration (excerpt):
apiVersion: serving.knative.dev/v1
kind: Revision
metadata:
name: superflake-00005-xim
labels:
serving.knative.dev/route: superflake
serving.knative.dev/configuration: superflake
serving.knative.dev/configurationGeneration: '5'
serving.knative.dev/service: superflake
cloud.googleapis.com/location: us-central1
...
spec:
containerConcurrency: 1
timeoutSeconds: 300
serviceAccountName: 5284XXXXXXXX-compute@developer.gserviceaccount.com
containers:
- image: gcr.io/superflake/superflake
ports:
- containerPort: 8080
resources:
limits:
cpu: 1000m
memory: 128MiThe performance (request latencies):
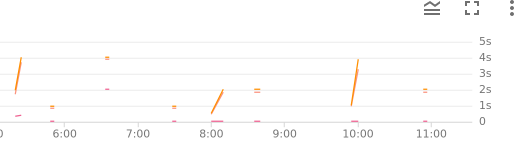
Serving through AWS Lambda
While Zappa is not the only tool to turn web applications into ‘fat functions’, that means inclusion of all framework dependencies beyond what the native FaaS language runtimes offer, it is considered one of the more mature tools. However, trying to deploy to AWS Educate (the service we have been given), we stumbled on some issues – some of them could clearly be handled better in Zappa, while others may be undefeatable obstacles through the reduced permissions in Educate.
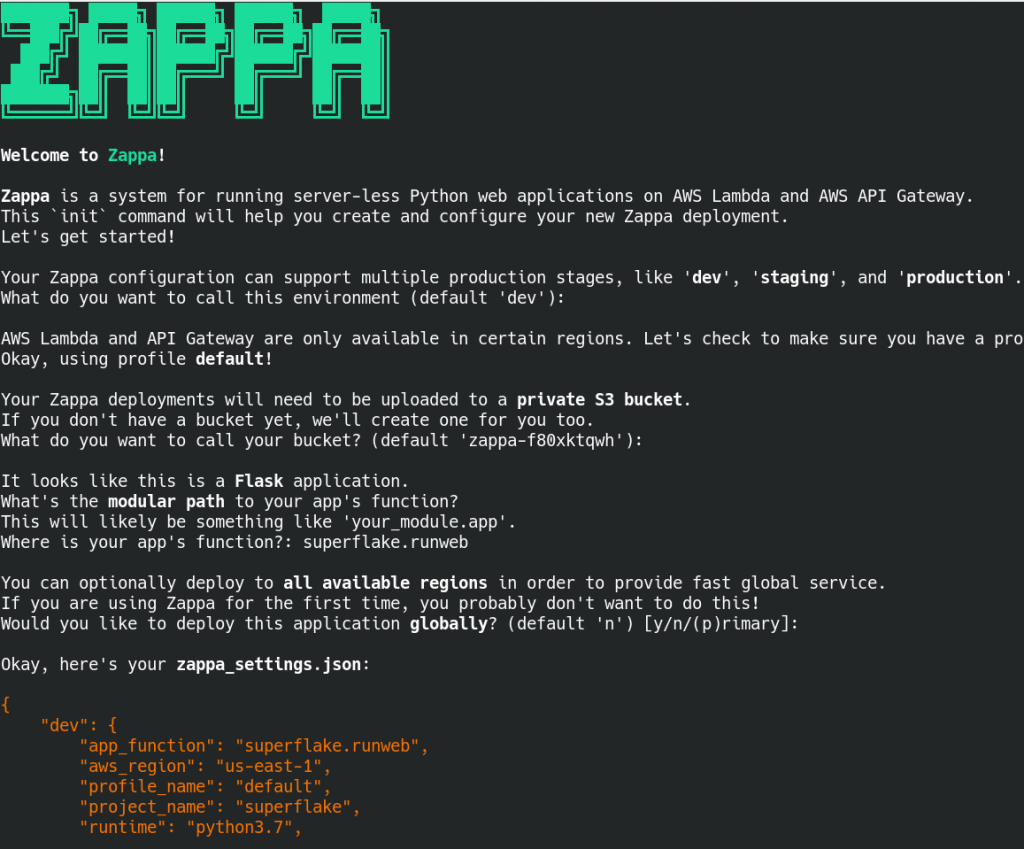
To turn a Flask app into a Lambda with Zappa, the following steps are necessary:
- Creation of a virtual environment for Python 3, i.e.
virtualenv -p /usr/bin/python3 venvfollowed bysource venv/bin/activate - Initialisation of Zappa, i.e.
zappa initthat will generate the configuration filezappa_settings.json. - Actual deployment, i.e. zappa deploy that will create a ZIP and upload it to S3 as well as create the Lambda, pointing it to the ZIP file and connecting to the API Gateway along with other deployments through Cloud Formation.
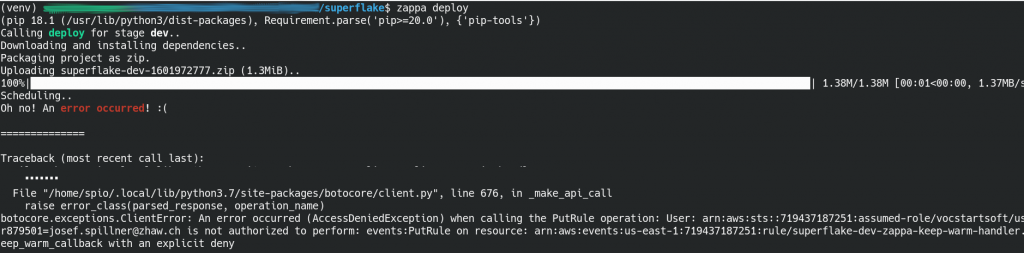
The ease of use of Zappa under ideal conditions is certainly good. For us, the conditions were not ideal. First, it tries to add a keep-warm ping for which the permissions on Educate are not sufficient. As this is only a minor optimisation against coldstart effects, the deployment should not fail when this single step fails. Thanksfully, it is possible to disable it manually in the configuration file by adding "keep_warm": false. Still, it then fails with other operations such as DescribeStackResource, and furthermore the deployed Lambda is incomplete regarding the Flask dependencies.
The configuration process:
The deployment:
The attempted (incomplete) Lambda execution:
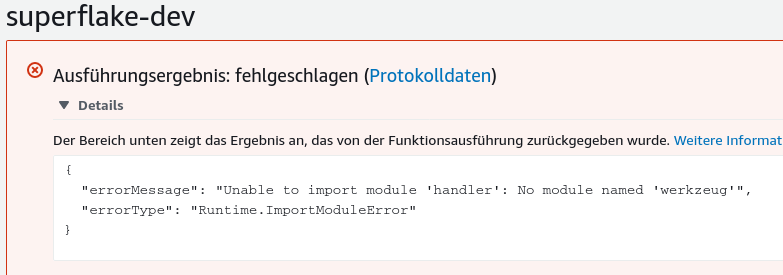
The presentation of the two paths towards is neither conclusive nor entirely fair, given that both require a relative high amount of manual steps that work well or less well depending on the system privileges and the available prior knowledge. Still, we publish it here as early result to convey the approximate effort necessary in 2020, and to generate new research ideas about how we can make this process radically more simple in the future.