The MAO-MAO research collaboration aims to provide metrics, analytics and quality control for microservice artefacts of all kinds, including but not limited to, Docker containers, Helm charts and AWS Lambda functions. As such, an integral part of prior research has been the various periodic data collection experiments, gathering metadata and conducting automatic code analysis.
However, the ambition of the project to collect data consistently, combined with the need for the collaborators to be able to use each other’s tools and access each other’s data, have created a need for a collaboration framework and distributed execution platform.
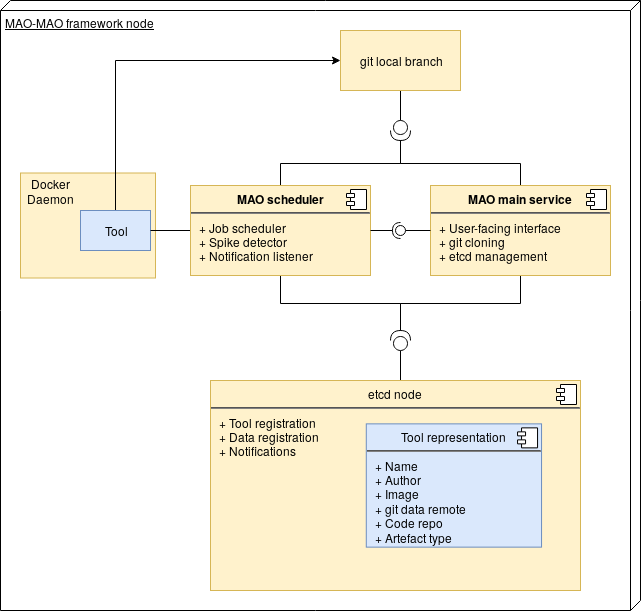
In response to this need, we present the first release of the MAO Orchestrator, a tool designed to run these experiments in a smart way and on a schedule, within a federated cluster across research sites. As a plus, there is nothing implementation-wise tying it to the existing assessment tools, so it is reusable for any use-case that requires collaboratively running periodic experiments.
Features
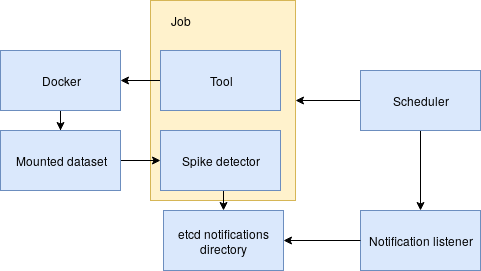
- Scheduler subsystem combined with Docker interface to execute the tools
- Etcd cluster to share data among collaborators
- Built-in spike detector with notification system to notify the operator of anomalies/regressions in the data
Setup and Usage
Assuming the host already has Python 3 and Docker installed, the only tricky component to setup would be etcd. For basic testing it is enough to install and run etcd and make sure the host and port in the config.ini file of the tool is correct, but for proper clustering one would have to use one of the clustering methods mentioned in etcd’s documentation. We plan to develop our own automated discovery system once we have enough volunteers to test the system in a real federated cluster.
Once the platform is running, the interactions can be made using our command-line client, maoctl, which we will now briefly present. Detailed documentation is available on Github, where you can also find a set of guidelines for creating compliant tools that can be run on the platform. If that sounds intimidating, rest assured that if a tool can be run from a single Docker container non-interactively and write output to a file, it can very easily be made to comply with the Orchestrator.
MAOCTL
maoctl is a command line client for the Orchestrator, serving to eliminate complex HTTP requests and provide unified I/O for all user interactions with it. It has two subcommands:
- tool which allows users to list, register, test or schedule their tools
- dataset which allows users to list, register or clone datasets
Demo
Here is an example of using the Orchestrator with maoctl to run a tool:
First we list the tools to see what tools we have available. In a real cluster, tools registered by a user are visible to and usable by all other users.

Now we can schedule the tool we want to run, but before we do that, we should test it by running it immediately, this is done with the run subcommand. Here it also prints the result of the spike detector. If this is the first time we run the tool, it will also clone the associated dataset.
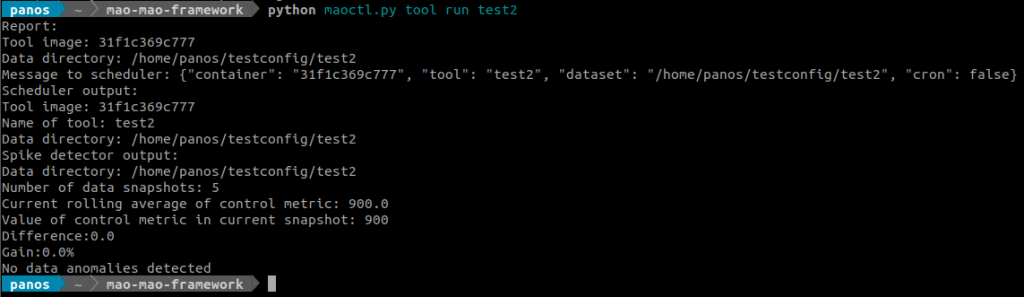
Here is the JSON object representing the tool in etcd:
{
"name": "test2",
"author": "panos",
"image": "31f1c369c777",
"data_repo":"https://github.com/EcePanos/sar-static-data.git",
"code_repo":"https://github.com/EcePanos/sar-static-data.git",
"artefact":"test"
}
Now we can schedule it to run daily or weekly.

If a user is not interested in running the tools but only wants access to the datasets, they can use the dataset subcommand to clone registered datasets directly.

The orchestrator will thus help to maintain and operate a resilient research infrastructure for empirical research on software quality. Of course, the development of the Orchestrator is meant to be community-driven and we welcome all feedback. Check out the code!