Software developers and service operators need log files to identify issues, detect anomalies and trace execution behaviour. The amount of generated log data is increasing, and often log files need to be kept for longer periods of time due to regulations. To preserve logs in a cost-efficient manner, they are typically compressed, at certain cost for running the compression, and then stored in long-term archives, again at certain cost per size-duration products. The goal is decrease both cost components, but there are certain trade-offs, for instance a highly efficient compression that consumes a lot of CPU but leads to better compression ratios, consuming less storage capacity as a result. The decision which compression tools and parameters to use is usually hardcoded. We present a smart knowledge-based advisor service to query goal-based adaptive compression commands to maximise savings.

Compression tooling knowledge can be thought of as a graph containing file formats, standards, compression/decompression tools and further tools to handle the compressed files, for instance in text searching. Not only the tools, but also their characteristics, retrieved through representative benchmarks, should be captured so that the best compression method can be searched for any given situation. An excerpt of such a graph is shown below along with some explanations.
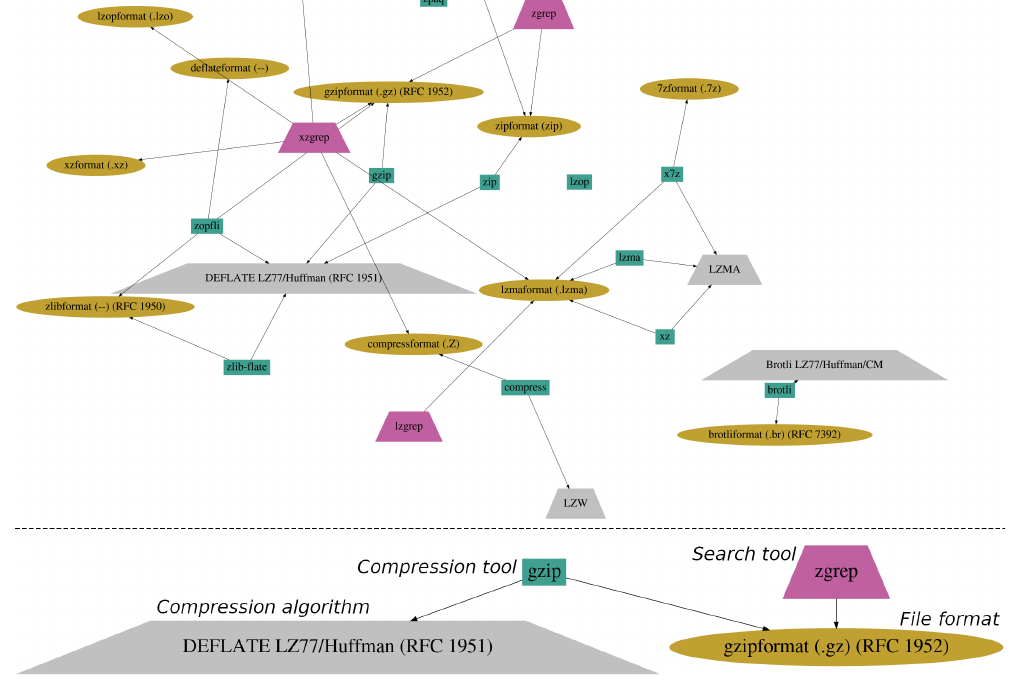
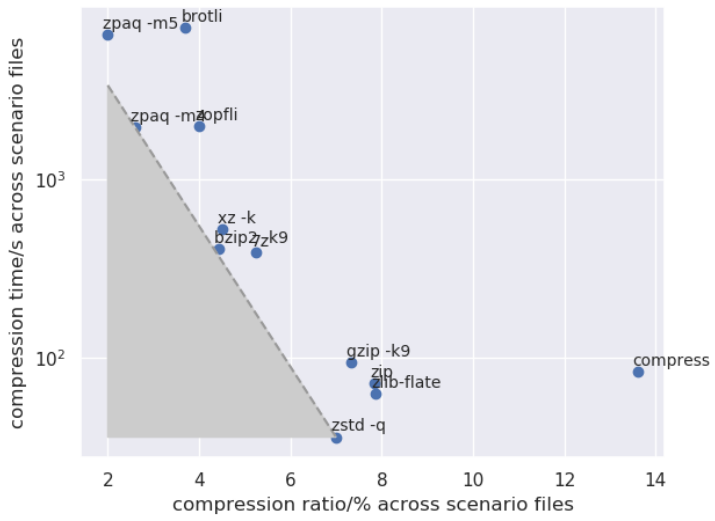
Precise knowledge on compression is important. Of key interest is the relation between ratio and timing – we often want fast and best compression combined, although in practice, we might have to make a compromise for one of them. Also, there are some restrictions, e.g. some of the best compression tools might have a 2GB file size limit. The duration/ratio trade-offs are shown below, along with the “pareto front” that prevents us from reaching absolute optimums.
Having access to such a graph and the compression duration/memory/ratio/limits information is the first step towards a holistic solution. A second step is then the logic to determine the best tool and its parameters for a given goal, e.g. “best compression ratio” or “fastest decompression time (for searching)”. The third step is to make this functionality available as an API, to align with various cloud service models. Our system, compressadvisor, along with the compressgraph model and the automated benchmarking is shown below.
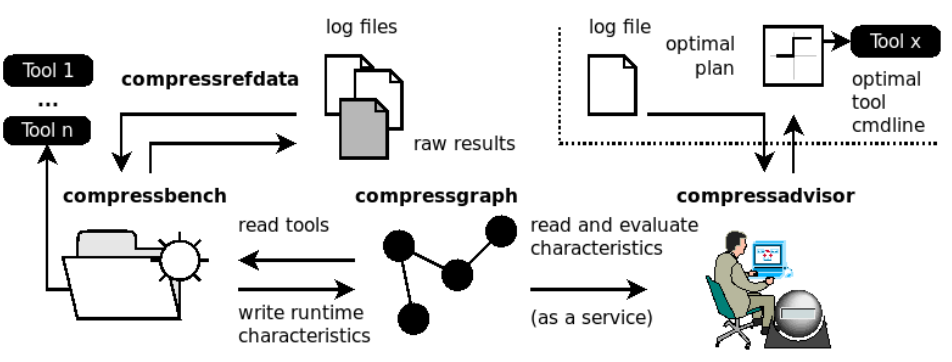
The compressadvisor is simple to use through a RESTful API along with a provided CLI tool so that e.g. scripts can always query the advisor instead of hardcoding the execution commands.

We provide a demo instance of the advisor running at Google App Engine along with an upcoming code/data/benchmark repository. The innovative log management solution will be presented at the CCCI 2020 conference in November where the open source repository will be launched as well. The work is based upon work supported by Google Cloud, with GCP Research Credits for Serverless Data Integration, and furthermore linked to other log management activities supported by an innovation starting grant of the Swiss Leading House MENA.