The first four “wild” years of serverless computing, starting with simple Function-as-a-Service (FaaS) launches in 2014, are over, and we are in the fifth year now. All major cloud companies offer FaaS, corresponding Backend-as-a-Service (BaaS), and related “serverless” services such as frameworks for cloud function-based data processing at the edge or in constrained environments. Researchers from universities, research institutes and research divisions in companies have covered this development, and proposed improved systems and frameworks, since 2016 – trailing two years behind industry initially, but with promising designs and prototypes which may give the necessary impetus for a next-generation serverless computing paradigm. We have surveyed 130+ research papers and announce the Serverless Research Output website which makes the results accessible.
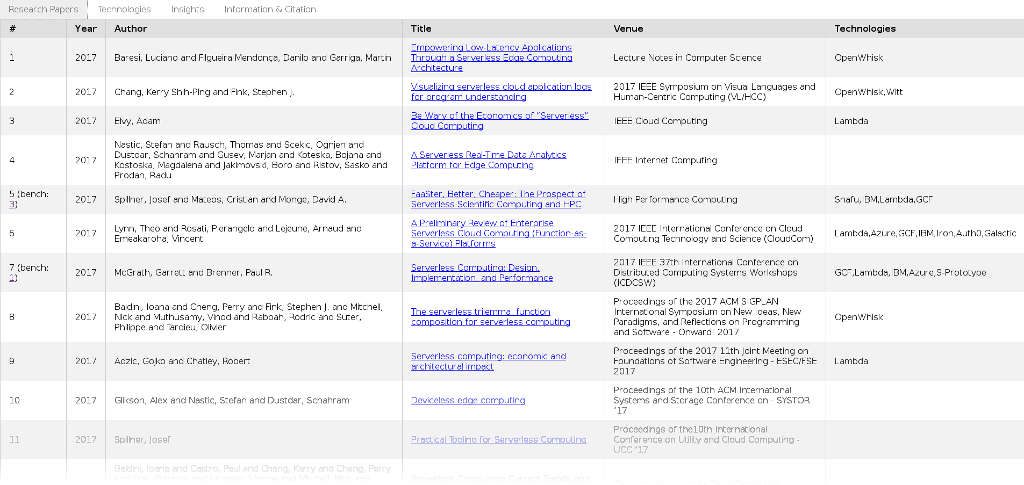
134 papers covering 58 technologies (more than half open source), many contributed by the researchers from 33 countries – most people will not have read the 1360 pages totalling around 5.3 million characters but in the course of preparing the dataset, we had the honour to do so, of course often more superficially than we would like. All papers, technologies and extracted graph relationships are published on the Serverless Research Output (SRO) website and the underlying Serverless Literature Dataset (SLD) has just been published at Zenodo in its third revision. We hope that both become a useful tool to researchers who can count on stable “SLD” identifiers with few digits to cite relevant works, for example. Give us feedback on any omission or incorrect analysis! As one reviewer noted on the ESSCA paper describing the second revision of the dataset (SLD#133), a blog post is perhaps more suited than a paper describing the dataset, so here we go (and give the opportunity to others to exploit the data in papers). In this post, we share some background information and general (perhaps not fully objective) thoughts on the technological progress.
For us, ESSCA 2018 along with WoSC4 in Zurich brought together a number of researchers in this field. There was a general understanding that as the field is still new, shaping the community early would lead to better research output compared to for instance the general field of cloud computing which has become impossible to follow in all directions. Researchers from TU Berlin brought their community ideas on comparable benchmarking forward (SLD#119). We promised to reference entries in their dataset which they marked as accepted based on fulfilling defined benchmarking criteria, and this revision of SLD indeed contains such references, although only in simple form for now. Unifying the paper identifiers and adding more high-level details on experiments would contribute to faster finding relevant papers.
SLD is around 3500 lines of pretty-printed JSON. Of what use is this dataset, what can we learn from it to offset the effort in making it? Remarkable is the growth beyond what we initially estimated. We count 7 papers in 2016, 37 in 2017, 69 in 2018 and 21 in just the first months of 2019 (the 1st revision of SLD contained 34 papers in a spreadsheet, the 2nd one 60 in the current JSON format). Growth is also evident in how many classic research fields get linked to serverless. We increasingly see mathematics, formal methods, database (think CIDR) and event processing (think DEBS) backgrounds along the usual suspects from cloud, data analytics and scientific computing. Given the strong influence of event-driven architectures on FaaS, the rather late but presumably now strong interaction between the communities, as the papers on serverless actors (SLD#126 and SLD#132) indicate. With Trapeze, S-FaaS and Se-Lambda, several interesting system contenders are now also bridging between FaaS and security research communities.
The involvement of industry remains high, more than a third of the works, with 10.4% of papers written by industry researchers alone, and another 25.4% of papers written collaboratively by industry and academia. The serverless programming, deployment and execution model appears to be of interest to IBM, Huawei, Microsoft, Platform9, VMware, Engineering Ingeneria Informatica, Intel, Nokia Bell Labs, Ericsson, SAP, and a number of smaller companies. The percentage of open access papers remains high with 18% arXiv (although some duplicate), 7% USENIX and 6% CEUR-WS, along with a number of open access papers at ACM and IEEE. Around 31% of the works are published in journals, magazines and on preprint servers, leaving 69% for conferences and workshops. Most works are original, only 11 have been identified as shortened or revised version, or preprint of a published article.
The range of technical contributions is wide. The following list gives an overview, without claiming completeness even within the scope of the dataset:
- Analysis of commercial FaaS services — the “classic four” AWS Lambda, IBM Cloud Functions, Google Cloud Functions and Azure Functions, but also Greengrass, Auth0 and other alternatives.
- New FaaS engines or significant extensions to open source ones such as OpenWhisk — EdgeScale, Solo5, OpenLambda, SAND, Snafu, RETRO-λ, GPU-SCF, ServerlessOS, SOCK, WebAssemblyPrototype, Kappa, S-FaaS and Knative.
- OS/cloud and security support for FaaS — EMARS, MPSC, Trapeze.
- Backend-as-a-service, primarily low-latency storage — Zion, Pocket, Locus, TrIMS, Sanity.
- Tracing and debugging frameworks — Lowgo, Witt, GammaRay.
- FaaSification and FaaS enablement — Termite, Podilizer, Lambada, PyWren, numpywren, SCAR, Flint, ExCamera/mu workers, Luna, Function Hub.
- Workflow systems — DEWE, Hyperflow.
- Benchmarks — µ-benchmark, SPF.
In the future, we intend to complete the FaaS Chracteristics and Constraints knowledge base which has been dormant for about a year now. With its evolution-capturing approach, it could serve as time machine to see how previous experiments compare to current ones. For instance, Lambda may offer 1000 concurrent instances but that used to be 300 and previous experiments results may be interpolated to account for these differences. This dataset will then also be referenced from SLD for all commercial FaaS providers. Moreover, long-term measurements (explained in SLD#33) could be linked to commercial providers. We also intend to remain active on the technical research side with practical tools and frameworks to make serverless applications easier for, as some would probably say (SLD#110), the 99% of users out there for whom exploiting the benefits is currently too hard.