Serverless applications is one topic that SPLab has been working on for a couple of years now, with, for example, our work on a stand-alone FaaS platform Snafu, work on disaggregating applications into serverless functions, Podilizer and other activities. Having organised ESSCA some weeks ago, we are now again exploring the technical limits and challenges in this space. This blog post reports about our experience of running the combination of OpenWhisk, Kubernetes, Helm and OpenStack.
OpenWhisk was an early mover in this area and we did look at it some time ago, albeit with limited success due to installation woes; we decided it was time to take another look at OpenWhisk to see how it stacks up in 2019 and what potential non-trivial enhancements of the platform could be.
Launching OpenStack Instances
We wanted to set up OpenWhisk on some VMs on our lab’s OpenStack cluster. Hence we created 3 virtual machines on OpenStack – a single Kubernetes cluster master with 2 worker nodes; of course more than 2 worker nodes is possible.
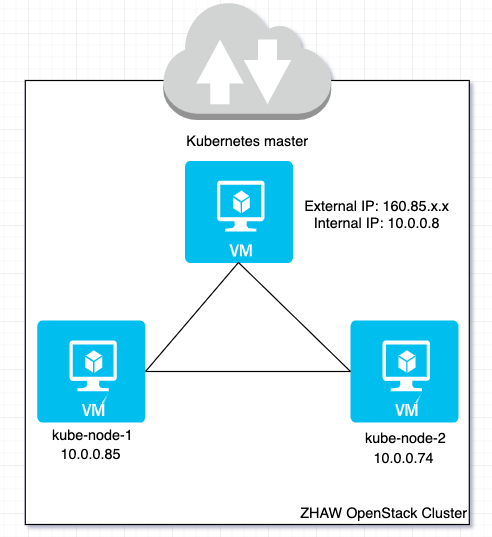
We required at least 4 GB of RAM per machine. We did try VMs with a smaller amount of RAM but some containers could not start due to insufficient memory. Also, the Kubernetes master must have at least 2 CPUs.
SSH access to all machines is required; in our case, the Kubernetes master had an associated floating IP and this could be used as a proxy to access the other nodes. If the nodes are on the same network and within the same security group in OpenStack this is possible by default.
Creating the Kubernetes Cluster
We decided to use kubeadm to create the Kubernetes cluster on the VMs and used this how-to to bring everything up.
To confirm that everything is configured correctly run:
$ kubectl cluster-infoThe following output shows everything is healthy:

We installed OpenWhisk using the Kubernetes package manager, Helm. We used this guide to install helm.
Once Helm was installed, we configured it as follows:
$ helm init$ kubectl create clusterrolebinding tiller-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:defaultThis installed and configured the Helm server component, Tiller, on the Kubernetes master. You can check that Tiller has has been successfully installed by running:
$ helm versionYou should get a similar output:

With an operational Kubernetes cluster with Helm installed, it was time to turn our attention to OpenWhisk.
Deploying OpenWhisk
We started by cloning the OpenWhisk git repository:
$ git clone https://github.com/apache/incubator-openwhisk-deploy-kube.gitTo install OpenWhisk, it was necessary to tell it a bit about the environment to which it was being deployed; this was done by creating a mycluster.yaml file. In our case the file looked like this:
whisk:
ingress:
type: NodePort
apiHostName: x.x.x.x
apiHostPort: 31001
nginx:
httpsNodePort: 31001
invoker:
containerFactory:
impl: "kubernetes"
k8s:
persistence:
enabled: falseThe apiHostName that we used was the internal IP address of the Kubernetes master (in our case it was 10.0.0.8) obtained via:
$ kubectl cluster-info
Kubernetes master is running at https://10.0.0.8:6443
KubeDNS is running at https://10.0.0.8:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxyNext, we had to add some labels to nodes on the Kubernetes cluster; this information was used by Helm to determine where to deploy certain capabilities. We needed to differentiate between so-called core nodes and so-called invoker nodes; the former operates the OpenWhisk control plane (the controller, kafka, zookeeeper, and couchdb pods), while the latter schedules and executes user containers. More details here and here.
$ kubectl label nodes <CORE_NODE_NAME> openwhisk-role=coreSimilarly an invoker node was configured using:
$ kubectl label nodes <INVOKER_NODE_NAME> openwhisk-role=invokerOnce that was set up, we were in a position to deploy OpenWhisk using the following:
$ helm install ./helm/openwhisk --namespace=openwhisk --name=owdev -f mycluster.yamlThe process was generally quite smooth; we did have some small issues during the first OpenWhisk install due to an error in the mycluster.yaml file; the API hostname of the whisk ingress was misconfigured and hence the invoker pod got stuck in a Crashloop trying to talk to the ingress. Once that error was fixed – by modifying the mycluster.yaml file – we redeployed OpenWhisk again and everything worked as expected.
This created all the required Kubernetes artifacts (containers, networks, volumes etc) required to run OpenWhisk. For us, this took somewhere between 5 and 10 minutes depending on network bandwidth, VM memory consumption etc.
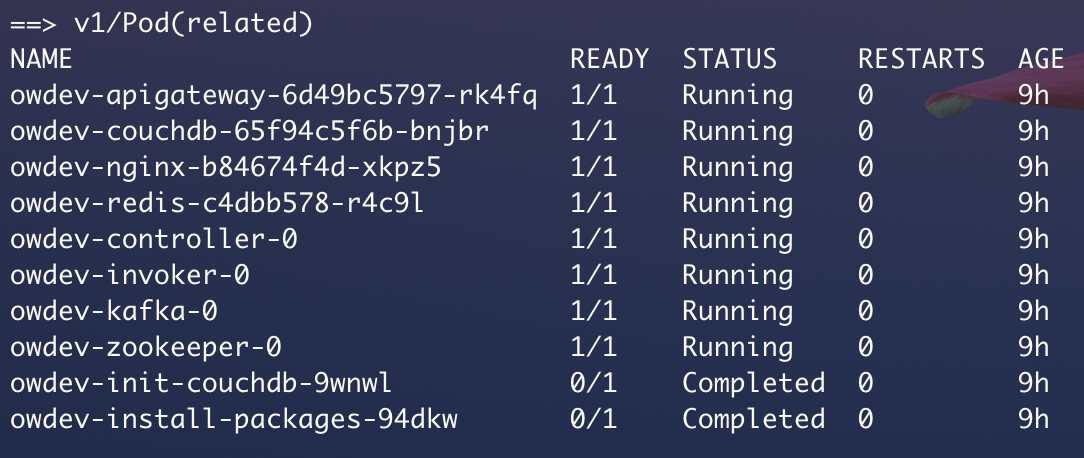
We used the following command to periodically check the status of the deployment:
$ helm status owdevThis provides dynamic content which shows the state of the deployment as it evolves. We checked this frequently as the deployment was ongoing. The process is finished when the install-packages pod enters the Completed state. This is how the Pods section of the status report looked like when the deployment was ready:
All we needed then was a CLI to talk to our new cluster – we downloaded it from here.
It was necessary to configure it as follows:
$ wsk property set --apihost <whisk.ingress.apiHostName>:31001Where <whisk.ingress.apiHostName> is the public address of the machine running the Kubernetes master.
$ wsk property set --auth
23bc46b1-71f6-4ed5-8c54-816aa4f8c502:123zO3xZCLrMN6v2BKK1dXYFpXlPkccOFqm12CdAsMgRU4VrNZ9lyGVCGuMDGIwPAnd the long token specified is a default token baked into OpenWhisk for the guest account.
IMPORTANT: The auth token MUST be overridden in production environments by editing the values.yaml file that belongs to the OpenWhisk Helm chart.
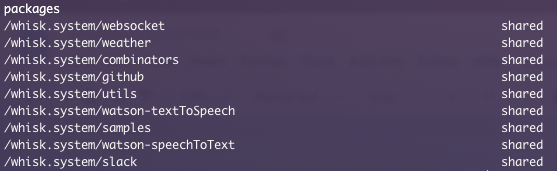
With that configuration, it’s possible to list the installed packages, for example:
$ wsk -i package list /whisk.systemAnd this is the output that we got:
We found out that deploying OpenWhisk on Kubernetes in 2019 was quite straightforward using the available Helm chart. The containerised environment comes up reasonably quickly and exhibited acceptable stability in our initial testing.
We were then ready to start using our shiny new OpenWhisk cluster. The next steps were to create new users using wskadmin (note that this had to be used from inside the owdev-wskadmin container) and start adding functions, triggers and event streams.
More on that in the next post!
A Note on Tear Down
In the unlikely event that you’re unhappy with your OpenWhisk cluster you can run the following command and Helm will take care of deleting all the resources that it created:
$ helm delete owdev --purgeYou can then tear down the Kubernetes cluster using these instructions.
Alternatively, you can just shut down the VMs.
Configure persistent storage for OpenWhisk on Kubernetes: https://blog.zhaw.ch/splab/2019/02/28/reliable-openwhisk-deployment-on-kubernetes-with-persistent-storage/