Linux Driver for LT6911UXC HDMI to MIPI CSI-2 now available for Linux for Tegra R36.X
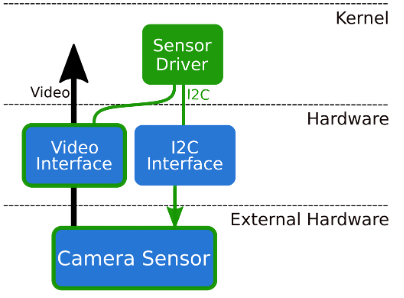
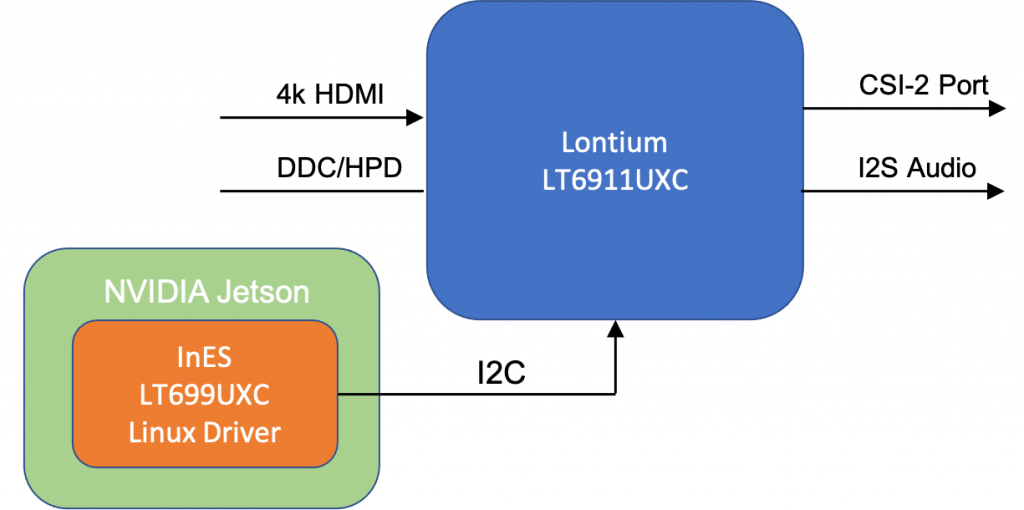
The ZHAW Institure for Embedded Systems (InES) is happy to announce the new and revided version of the Lontium LT6911UXC driver compatible with the newest Jetson Linux version L4T R36.X. The driver can be downloaded from now on from the Lontium_lt6911uxc Github repository. Depending on the firmware running on the Lontium LT6911UXC (which has to […]