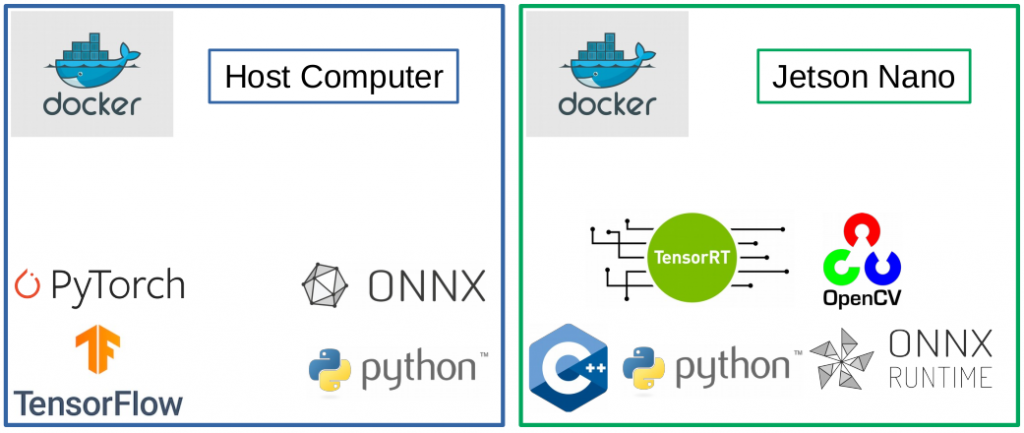
Running artificial intelligence (AI) algorithms, such as neural networks, directly on embedded devices has many advantages compared to running them in the cloud: One can save significant amounts of cloud storage, reduce power consumption and enable real-time applications. In addition, privacy is increased and required bandwidth reduced because only the AI algorithms results are forwarded to the cloud, not the full data. However, setting up the environments for custom neural networks on embedded devices can be difficult. Thats why the HPMM team provides a fully “dockerized” reference workflow for the Nvidia Jetson Nano. It includes:
- Container to convert Tensorflow and Pytorch models to .onnx models
- Container to cross-compile a C++ TensorRT applications for a Jetson Nano including opencv
- Container to run TensorRT networks on the Jetson Nano with the C++ and Python API
Please find the link to the reference workflow here.
If you are interested in running AI algorithms on microcontrollers, such as the Cortex M4, we provide the reference workflows for several frameworks such as TensorFlow lite for microcontrollers, CMSIS-NN and ST CUBE AI here.
Feel free to contact us regarding your custom application or project regarding embedded artificial intelligence!