BY TOBIAS WELTI AND HANS-JOACHIM GELKE
Due to their hardware architecture, Field Programmable Gate Arrays (FPGAs) are optimally suited for the execution of machine learning algorithms. These algorithms require the calculation of millions or even billions of multiplications for each input. To successfully accelerate a neural network, parallel execution of multiplication is the key. The obvious suggestion for parallel execution is a Graphics Processing Unit (GPU), offering hundreds of execution cores. For years, GPU vendors have been adapting the capabilities of their GPUs to meet the demand for narrow integer and floating-point data types used in AI. But still, a GPU will execute one Neural Network (NN) layer after the other, with data transfers between computation cores and memory.
Implementing Neural Networks in FPGAs has several advantages:
- Flexible bit widths for both integer and fixed-point data types.
- Large numbers of scalable hardware multiplier cores.
- Flexibility due to tightly coupled memory blocks with wide parallel interfaces, allowing access to vast numbers of data points in each clock cycle.
Considering the previous points, the FPGA clearly provides all the resources required for highly parallel execution of NN algorithms.
Existing frameworks
Unfortunately, the act of porting a trained network to HDL code for implementation in the FPGA is not trivial. FPGA vendors have started to provide frameworks for running NNs in their devices. These include HDL-coded NN-coprocessor cores as IP blocks and matching compilers to convert a trained NN into a binary executable which will run on the coprocessor. However, these frameworks are based on a specific software library and therefore require a processor core running an operating system and controlling software. This means that the NN input data and network parameters are transferred from the software to the coprocessor in order to calculate the output of the NN. The output values are then transferred back to the software for interpretation.
This is substantial overhead, especially if the input data is sampled or preprocessed in the FPGA fabric. It would be preferable to implement the neural network entirely in the FPGA fabric, capable of running independently from software.
ZHAW Native Neural Network
The ZHAW Native Neural Network (ZNNN) framework is aimed at the following goals:
- Input may be received directly from FPGA fabric
- Inference independent of CPU and software
- Minimal latency
- Maximal throughput
- No access to DRAM required
With these goals in mind, it is obvious that we trade in flexibility to gain performance and simplicity. The NN is implemented as a rigid block, designed for one single NN application. To allow for minimum latency, we use dedicated multipliers for each neuron, and each layer has its own memory block for the weights and biases. Ping-Pong buffers allow to process one input vector in one layer while receiving the next input vector. With this structure, pipelining delays can be minimized to the execution time of the largest layer.
Our framework will take as input a structured text file with a description of the NN, including number of inputs, data-bit widths, fix point precision, number of neurons per layer for fully connected layers, number of filters and kernel size for convolutional layers, max pool and flatting layers. From this configuration file and a training and verification data set, it will generate:
- Input A trained NN model
- A behavioural model written in C programming language to generate a data set for verification of the VHDL code in simulation
- A test bench for verification
- The VHDL code of the NN ready for instantiation in your design.
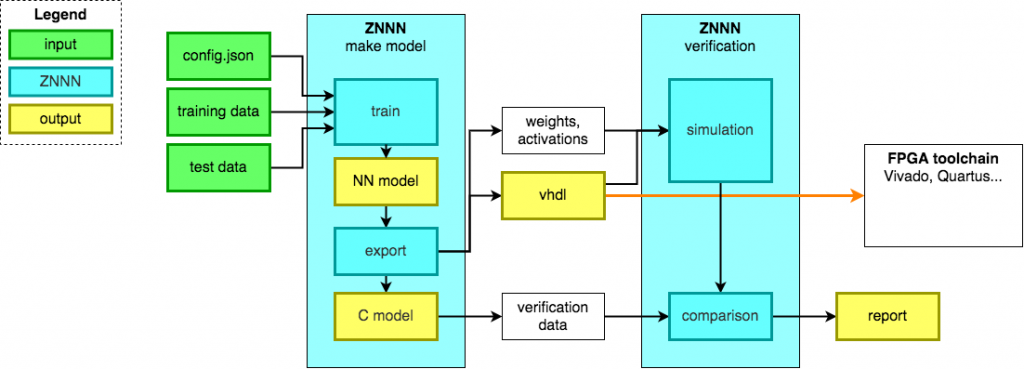
Dedicated multipliers for the neurons will use a significant amount of the available resources and it must be noted that larger networks will require considerably larger devices. This will not be suitable for all NN applications. Our ZNNN framework is optimally suited for applications such as industrial machine surveillance where only small networks will meet the latency requirements while still achieving the required accuracy.
Performance
A direct comparison of ZNNN with the Deep Learning Processing Unit (DPU) coprocessor from Xilinx shows that both have their justification, depending on the application at hand:
If you need to run multiple, different neural networks on your FPGA with a fair performance, you should go with the Xilinx solution. The DPU allows to process different NN on the same implementation but is restricted to software-controlled operation.
If performance is essential and your application needs a single neural network, you should use the ZNNN.
The amount of resources in a Xilinx Zynq UltraScale+ EG9 device used by the different solutions is shown in the following table. The ‘Xilinx DPU’ will always use roughly the same amount of resources (depending on its configuration). It can process various neural networks, including very large ones, with a trade-off in throughput and processing time (latency). The resource requirements of ZNNN strongly depend on the size and type of NN you implement. ‘ZNNN MNIST’ is a NN with only dense layers, trained for the well-known MNIST example. MNIST is a NN application that recognizes handwritten numbers. ‘ZNNN CONV’ is a NN using 1D-convolutional layers for non-linear signal processing in an industrial application which accepts 64 data points as input. ‘ZNNN VIS’ is a dense network with 2304 inputs and one single output, used for an industrial application. According to the large number of inputs, the number of multipliers required is very large.
| NN | LUT | BRAM | DSP | Throughput (FPS) |
| Xilinx DPU | 47 k (17%) | 132 (14%) | 326 (13%) | 2.5 k |
| ZNNN MNIST | 34 k (12%) | 182 (20%) | 947 (37%) | 8510 k |
| ZNNN CONV | 20 k (7%) | 124 (13%) | 712 (28%) | 291 k |
| ZNNN VIS | 87 k (32%) | 182 (20%) | 2467 (98%) | 4081 k |
Throughput of a NN can be measured in the number of inputs processed per second (FPS). On the Xilinx DPU, the whole NN is processed for one set of input data before the next set can be passed. Our ZNNN framework implements layer pipelining, meaning that as soon as the first layer is processed, the next input set can be accepted as shown in the following figure.
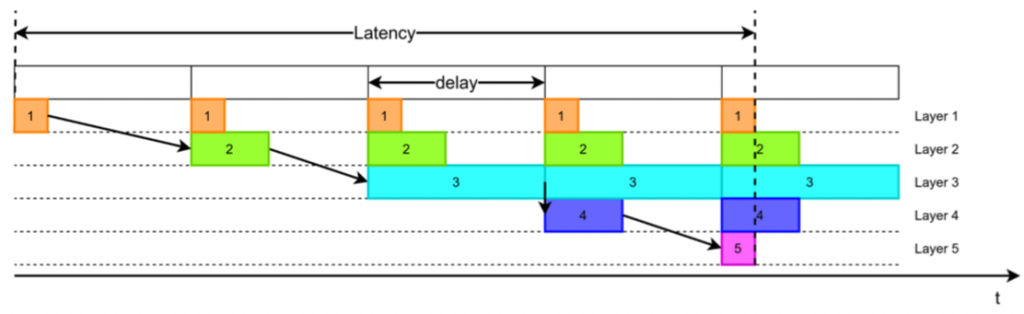
The latency is slightly increased because not all layers have the same processing time, but all the layers are processed in parallel. In return, the delay between two inputs is greatly reduced, allowing to process more FPS. Because ZNNN includes all the required weight parameters in the design, these don’t need to be loaded into the FPGA at runtime. This allows to increase the FPS by orders of magnitude in comparison with the Xilinx DPU.
Conclusion
Both the power and the cost of ZNNNs become visible in comparison with the DPU: The DPU offers the flexibility to run various NNs on one implementation, including larger NNs like Resnet50. The DPU is controlled by software and therefore requires a CPU running a Linux operating system. ZNNN implementations are ideal for small NNs and run independently from software, take their input directly from FPGA and process orders of magnitude faster than the DPU!
The ZNNN framework is suitable for low latency, high throughput execution of small convolutional and fully connected NNs. It generates VHDL code for a specific NN implementation in FGPA without the development overhead of hand-written HDL code and testbenches. The processing performance of the ZNNN is orders of magnitude faster than Xilinx’ DPU thanks to a high level of pipelining.
We are aware that the ZNNN implementation can require more FPGA resources than the DPU, but there are industrial applications where this approach is a perfect fit and the achieved performance meets the requirements. With the ZNNN running independently of CPU and software and the input data coming directly from the FPGA fabric, we have principally no bottlenecks in the design.
Our team will continually improve the ZNNN framework by making trade-offs between resource requirements and performance configurable.