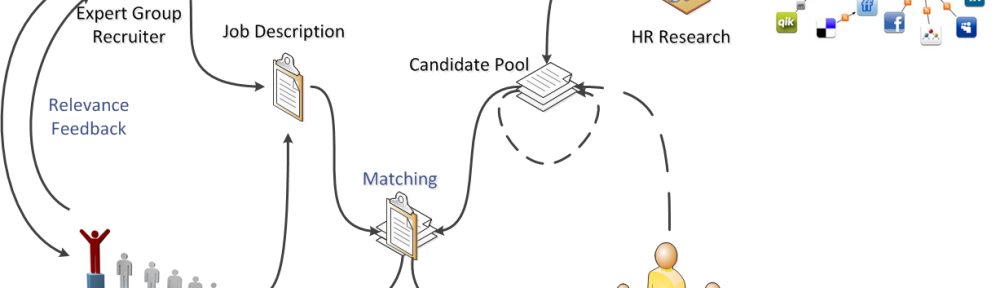
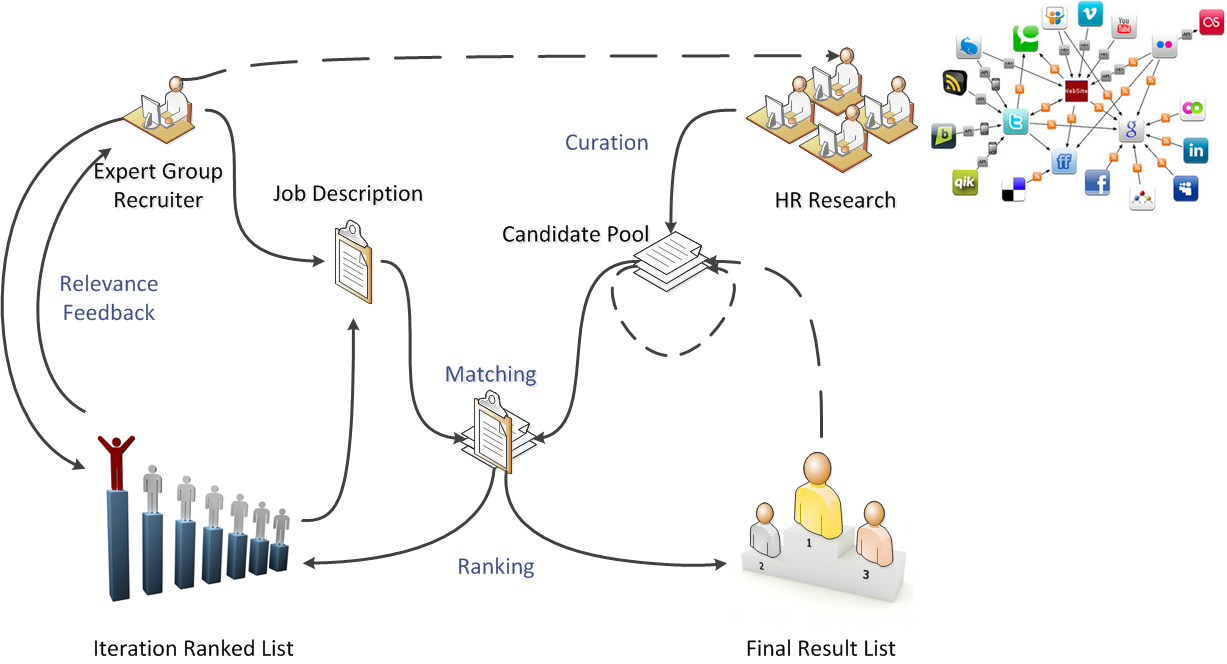
The information engineering group at InIT has recently successfully concluded a CTI funded project. The project is called “expert-match” and has been conducted in cooperation with expert group ag, a professional recruitment and consulting business head-quartered in Zurich, Switzerland.
Expert group’s recruiting focus consists of staffing high-profile expert positions (e.g. specialized senior software engineers, senior management, IT architects). Usually, there are at most a handful of people qualified for a recruiting mandate within the relevant geographical region they operate in. The problem is further compounded by the fact that qualifications are rarely obvious, requiring insight into candidates’ former positions and overall skill sets. Exact matching of job descriptions with candidate profiles, such as in a database environment, is thus unlikely to find the desired experts. By implementing an information retrieval (IR) application, we were able to mitigate the problem. The application fully supports iterative searches, especially focussing on relevance feedback.
Implementation
The application is built on existing components, so as to be able to concentrate on the actual business logic and associated interesting research issues. Terrier is used as the basic IR matching system. It proved to be stable and flexible, yet not sufficiently scalable for massive applications. For the given use case and order of magnitude of the data, however, it is perfectly suitable. For the graphical user interface, we intended to provide a highly interactive web application and therefore decided to go with GWT.
Approach
Relevance feedback plays a vital role in our approach, since it has been shown to increase retrieval effectiveness significantly in many environments, especially recall, i.e. the proportion of total relevant information which is actually found, which is crucial to the business case. Users are provided with feedback facilities in the form of positive and negative document bins. Dragging candidates to either bin influences subsequent search iterations: The query in the next iteration is expanded using selected terms from positively marked documents.
The relevance feedback mechanisms are built on top of Terrier components. To allow for the full range of positive and negative feedback, some minor extensions were necessary, since Terrier only supports positive feedback document selection out of the box. When querying, documents (resp. their IDs) marked as positive or negative by users are passed to the relevance feedback components. During query processing, the given feedback documents are scrutinized and their most characteristic terms extracted. The terms are added to the query (up to a threshold count) and the entire query is re-weighted using the well-understood Rocchio algorithm [1]. Another matching pass is then performed with the resulting modified query, yielding the final ranked list.
To appreciate the effect of the implemented feedback, consider documents and queries in vector space. Both queries and documents are represented as sparse vectors, where each dimension is the weight of a term drawn from the vocabulary of the entire document collection. The Rocchio algorithm effectively moves the query vector towards an “ideal” result document (i.e. the related documents’ centroid) based on the original query and terms from feedback documents with their associated weights. Note that this only holds true if positive feedback is valued higher than negative one. For an explanation of the effect, see the practical [2] Rocchio algorithm formula below:
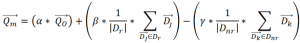
These are the main constituents of the formula:

Rocchio was chosen over probabilistic alternatives for its ease of parameterization. One of the project’s expressed goals was to evaluate optimal configuration values for the application. After evaluation and testing, the contribution parameters were eventually set to α = 0.3, β = 0.75 and γ = 0.25. In other use cases, α is usually left to be 1 as a neutral factor. But as first tests have shown the original queries’ terms to be largely dominant, their contribution was consequently lowered. Feedback becomes largely ineffective if the original query dominates. In case of entering entire job descriptions as queries, which is supported by design, feedback had entirely no visible effect at all. Conversely, skewing parameters towards feedback dominance obsoletes the original query and leads to results which have little relevance to the original information need as entered. Both extremes are undesirable for users. The intention of a formulated user information need, i.e. the query, must be respected and feedback must have visible and beneficial effects, which the previously shown parameter setting achieved for expert-match.
Results
The expert-match system is successfully used in expert group’s daily business since the first feature-complete version of the application. In fact, the new system strongly affected the business process of searching for experts: instead of only traditional database subtractive filtering, HR consultants now perform an additive IR search in parallel. This enables them to find candidates which would otherwise have been filtered away due to missing data or differing synonymous descriptions. Also, the relevance feedback facilities allow for searches of candidates which are similar to “prototype” employees as requested by their clients, which is a typical business case (e.g. “Get us another Heidi Müller, she’s a great addition to the team.”).
Much of the success of the project is due to the consistent implementation of relevance feedback in all parts of the application. It was possible to implement it in such a way because users were ready to provide explicit feedback, since they already spent significant amounts of time on searching.
[1] Rocchio, J. J. (1971). Relevance feedback in information retrieval. In: Salton, G. (1971). The SMART retrieval system—experiments in automatic document processing. pp. 313 – 323