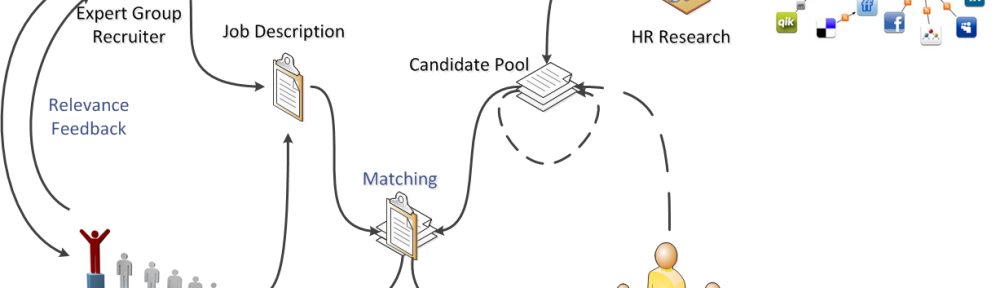
When A Blind Shot Does Not Hit
In this article, I recount measures and approaches used to deal with a relatively small data set that, in turn, has to be covered “perfectly”. In current academic research and large-scale industrial applications, datasets contain millions to billions (or even more) of documents. While this burdens implementers with considerations of scale at the level of infrastructure, […]