Blog-Autoren: Barth, Linard & Ehrat, Matthias
Im ersten Blogbeitrag zum Digital Twin Conceptual Framework der Fachstelle für Produktmanagement des Instituts für Marketing Management wurde das Rahmenmodell im Überblick vorgestellt und mögliche Anwendungen erläutert.
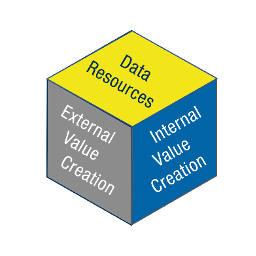
Um die Wertgenerierung mit digitalen Zwillingen ganzheitlich zu erfassen, werden im Rahmenmodell die drei Dimensionen «externe Wertgenerierung» (im Markt, bei den Kunden, in der Anwendung und Nutzung), «interne Wertgenerierung» (innerhalb des Unternehmens) und die dafür benötigten «Datenressourcen» unterschieden. In diesem letzten Beitrag unserer Reihe zum Rahmenmodell beleuchten wir die dritte Dimension «Datenressourcen». Wir erläutern dazu die drei Achsen und deren Spezifikationen.
Datenressourcen
Daten werden oft als das Öl des digitalen Zeitalters bezeichnet und sind für die Wertgenerierung mit digitalen Zwillingen unerlässlich. Die Analogie stimmt zwar hinsichtlich der zentralen Bedeutung dieser Ressource. Im Gegensatz zu Öl vergrössern sich jedoch die Vorkommen von Daten stetig.
Was ein digitaler Zwilling genau ist und wie welche Datenressourcen zur Realisierung verwendet werden, ist in Literatur und Praxis unterschiedlich definiert. Unter einem digitalen Zwilling wird jedoch immer eine Art von Datendrehscheibe verstanden, welche Daten erhalten, generieren, verarbeiten und weiterversenden kann. Damit ein Unternehmen die in der Betrachtung der externen und internen Dimension definierten Werte mit digitalen Zwillingen realisieren kann, ist es unabdingbar über die benötigten Datenressourcen zu verfügen.
Dabei stellen sich grundsätzlich die Fragen, über was beziehungsweise von was das Unternehmen Daten benötigt (Data Category), aus welchen Quellen (Data Sources) diese Daten gewonnen werden können und in welcher Qualität (Data Format) diese Daten benötigt werden. Hinsichtlich der letzten Teilfrage ist zudem zu beantworten, mit welchen Methoden und Werkzeugen die Aufbereitung und Analyse der Daten erfolgen soll.
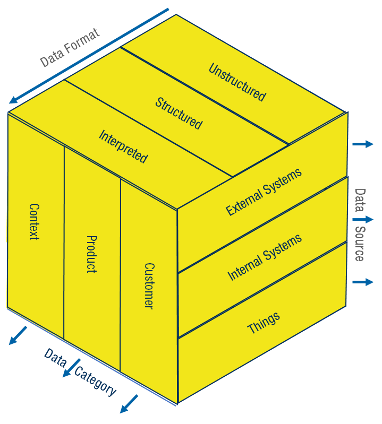
Data Category
Über was/von was benötigen wir Daten?
Viele Unternehmen geben darauf eine vermeintlich einfache Antwort: Wir müssen über alles möglichst viele Daten generieren und speichern – so haben wir alle benötigten Daten für aktuelle und zukünftige Anwendungen, die wir teilweise auch erst mit «Big Data Mining» im so angestauten «Data Lake» entdecken werden. Diese Antwort mag für einige Unternehmen wie Facebook oder Google durchaus richtig sein. Für die meisten Unternehmen ergeben sich dadurch jedoch mehr Herausforderungen als Mehrwerte: Die Preise für Cloud-Speicher sinken zwar stetig, dennoch sind die Kosten für Datenseen, die keinen unmittelbaren Mehrwert bringen, nicht zu unterschätzen. Zudem sind auch die Aufbereitungs- und Analysemethoden mittels Algorithmen, wie «Machine Learning» oder «Artificial Intelligence», selten in der Lage unbekannte Muster zu entdecken, ohne dass vorgängig zumindest eine Idee vorhanden ist, wonach gesucht werden soll. Schliesslich steigen die Kosten und Zeitaufwände mit der Menge an zu verarbeitenden Daten, falls diese überhaupt in einem austausch- und verarbeitbaren Format vorliegen. Deshalb sollte aus unserer Sicht Folgendes die Antwort auf obig gestellte Frage sein: Wir benötigen vorrangig jene Daten, welche notwendig sind, um die vorgängig definierten internen und externen Werte zu realisieren. Dabei können die folgenden drei Hauptkategorien unterschieden werden:
Kundenorientierte Daten (Customer)
Dazu gehören sämtliche Daten, die Auskunft über die Nutzer der eigenen Leistungen geben. Dadurch kann die Beziehung zum Kunden im Kundenlebenszyklus optimal gestaltet werden und Kunden können gezielt einzelnen Segmenten zugeordnet werden. Beispiele entlang der «Customer Journey» sind die erstmalige Wahrnehmung des Angebots («Impression»), die Phasen der Bedarfsentwicklung, die Aktivitäten des Such-, Vergleichs- und Auswahlprozesses, die Wahl geeigneter Konfigurationen, oder das Verhalten während der Nutzungsphase und darüber hinaus.
Produktorientierte Daten (Product)
In diese Kategorie fallen alle Daten, welche Aufschluss über das eigene Marktangebot in Form von Produkten und Dienstleistungen geben, sowohl historisch, aktuell, als auch zukunftsorientiert. Dazu gehören unter anderem Eigenschaften, Prozesse, Funktionalitäten und Zustände. Gerade hier kann der digitale Zwilling eine zentrale Rolle als Drehscheibe produktorientierter Daten aus der externen Nutzung und aus der eigenen, internen Wertschöpfung über den gesamten (Produkt-) Lebenszyklus einnehmen.
Kontextorientierte Daten (Context)
Die dritte Kategorie enthält sämtliche Daten, welche Aufschluss über die umgebenden Systeme geben und nicht direkt produkt- oder kundenorientiert sind. Dazu gehören Daten über Umwelt, Wirtschaft, Gesellschaft, Bezugs- und Absatzmärkte oder Konkurrenten. Die Kontextdaten scheinen auf den ersten Blick weniger relevant zu sein als die beiden anderen Kategorien. Doch die Kenntnis des relevanten Kontexts ist oftmals unerlässlich für eine erfolgreiche Interpretation der produkt- und kundenorientierten Daten (vgl. «Data Format»).
Data Sources
Aus welchen Quellen können wir die benötigten Daten gewinnen?
Sind die benötigten Daten identifiziert und definiert stellt sich die Frage, aus welchen Quellen diese Daten bezogen werden. Oft sind bereits Daten im Unternehmen vorhanden, weshalb eine gründliche Inventur und Analyse der vorhandenen Daten meist den ersten Schritt darstellt. Gerade in grossen Unternehmen sind die Daten oft unkategorisiert in fragmentierten (Teil-) Systemen unterschiedlicher Verantwortungsbereiche abgelegt. Hinsichtlich der nicht bereits vorhandenen Daten stellt sich im nächsten Schritt die Frage, aus welchen Quellen diese gewonnen werden können.
Things
Eine der zentralen Quellen für die Wertgenerierung mit digitalen Zwillingen sind die Instanzen. Diese generieren Daten über Sensoren und kommunizieren diese über das Internet der Dinge («Internet of Things»). Eine Instanz kann hierbei ein «Connected Product», ein «System» oder ein «System of System» sein, wie wir in der Dimension der externen Wertgenerierung ausgeführt haben. Diese «Things» sind jedoch nicht nur Datenquellen, sondern auch Datenempfänger. Genau dieser bidirektionale Datenaustausch zwischen digitaler Repräsentation und realem Gegenstück ist charakterisierend für digitale Zwillinge. Die «Things» sind oft die einzig mögliche Quelle für Daten direkt aus der Nutzungsphase und können alle Datenkategorien umfassen. So können z.B. Daten zum Zustand und der Performance (Product), zu den Nutzungspräferenzen (Customer) oder der Umgebungstemperatur und Feuchtigkeit (Context) generiert werden.
Internal Systems
Hierzu gehören sämtliche verfügbaren internen Informationssysteme eines Unternehmens. Im Kontext der Wertgenerierung mit digitalen Zwillingen sind das typischerweise CAD, CRM, MES, ERP, PLM, PIM und weitere Service-Systeme. Auch diese Systeme sind sowohl Quellen als auch Empfänger von Daten des digitalen Zwillings.
External Systems
Viele der benötigten und nicht von «Things» oder internen Systemen erhältlichen Daten können über externe Systeme als Quellen bezogen werden. Dazu gehören neben öffentlichen Systemen wie Datenbanken staatlicher Institutionen, Forschungseinrichtungen und Non-Profit-Organisationen auch kommerzielle Datenanbieter, sowie die internen Systeme anderer Unternehmen. Weiter stellen das Internet und die sozialen Plattformen nicht zu unterschätzende Datenquellen für die Wertgenerierung mit digitalen Zwillingen dar. Oftmals sind externe Systeme alternative Datenquellen, sodass Unternehmen ähnlich wie für physische Ressourcen im klassischen Supply Chain Management auch bei den Datenressourcen systematische Make-or-Buy Analysen durchführen sollten.
Data Format
Welche Datenqualität und -wertigkeit benötigen wir?
Daten an sich stellen noch keinen Wert dar. Erst durch deren Verwendung in einem konkreten Anwendungsfall wird Wert generiert. Für einfache Anwendungen mag es ausreichend sein, die Daten unaufbereitet beispielsweise als Datenpunkt oder Verlauf zu visualisieren. Für anspruchsvollere Anwendungen ist es dagegen erforderlich, Daten mit geeigneten Verfahren aufzubereiten oder sogar anzureichern. In der Folge repräsentieren diese, analog zur DIKW Pyramide, keine reinen Daten, sondern Informationen, Wissen oder gar Weisheit.
Unstructured
Unstrukturierte Daten sind nicht aufbereitete Rohdaten. Sie liegen häufig in herstellerspezifischen, nicht austauschbaren Formaten vor. Diese Art von Daten machen den Grossteil aller auf der Welt vorhandenen Daten aus, da das Strukturieren und Aufbereiten der Daten Kosten verursacht und daher oft erst im Bedarfsfall durchgeführt wird. Zu den unterstrukturierten Daten gehören z.B. Sensormesswerte der «Things» oder Daten in internen Systemen, die nicht mit anderen Systemen kompatibel sind und somit zu den bekannten Datensilos führen. Einfache Beispiele wären eine Audio-Datei eines Interviews oder ein einzelner Messwert z.B. von einem Ultraschallsensor.
Structured
Werden die unstrukturierten Daten aufbereitet, liegen sie in der Folge als Informationen vor. D.h. sie liegen nun in austauschbaren, durchsuchbaren und/oder interpretierbaren Datenformaten vor und sind nun anwendungsbereite Informationen. Die oben erwähnte Audio-Datei des Interviews wurde transkribiert und liegt nun z.B. im .xml-Format vor, welches von unterschiedlichen Programmen gelesen werden kann. Der Messwert des Ultraschallsensors wurde in eine Distanzmessung von 50 cm übersetzt und in der Cloud abgespeichert.
Interpreted
Auch Informationen stellen noch keinen Wert dar, dafür müssen sie zuerst verwendet werden. Um die richtigen Entscheidungen und Aktionen abzuleiten, müssen die Informationen jedoch zuerst interpretiert werden. Erst die interpretierten Daten repräsentieren eine hinreichende Basis für die Entscheidungsfindung, sie implizieren folglich Wissen (bedingen also «sense-making»). Sollen Entscheidungen oder Aktionen automatisiert ausgelöst werden, muss dieses Wissen auf Basis der Informationen generiert und in Verbindung gesetzt werden. Dieser Prozess ist aufwändig und fehleranfällig, da unter Umständen eine Vielzahl an Interdependenzen berücksichtigt und Unsicherheiten abgewogen werden müssen. Auch wenn beispielsweise Methoden der künstlichen Intelligenzen diese Aufgabe übernehmen können, wird sie in vielen Fällen noch den Menschen überlassen. Bei unseren Beispielen könnte das transkribierte Interview mit einem kognitiven Dienst auf Präferenzen und Einstellung der Person analysiert werden. Die gemessene Distanz des Ultraschallsensors könnte als Überschreitung eines Behälterfüllstandes interpretiert werden und dieser für die nächste Leerungstour disponiert werden.
Ausblick
Die Möglichkeiten zur Wertgenerierung mit digitalen Zwillingen sind sehr umfangreich und können je nach Unternehmen und Anwendung sehr unterschiedlich ausfallen. Ein Rahmenmodell hilft zur Orientierung und zur Definition und Kommunikation des eigenen Verständnisses innerhalb des Unternehmens. Das in diesem abschliessenden Beitrag vorgestellte Rahmenmodell wurde im April 2020 im Rahmen der «International Conference on Information Science and Systems» publiziert und wird auf Anfrage gerne zugesendet.
Das Modell wird zudem kontinuierlich für den Einsatz in der Praxis optimiert. Wir freuen uns daher über Ihr Feedback. Wir sind auch an der Diskussion konkreter Anwendungen und deren Realisierung interessiert.
Autoren & Kontakt

Linard Barth ist Wissenschaftlicher Mitarbeiter, Projekt- und Studiengangleiter am Product Management Center der ZHAW. Seine Interessen gelten in erster Linie dem Zusammenspiel einzelner Elemente in grösseren Systemen und wie diese konsistent nachhaltig funktionierend ausgerichtet werden können. Dazu erforscht er den Einfluss von Internet of Things, Smart Connected Products und Digitalen Zwillingen auf Business Modelle und Value Propositions. Als ehemaliger Gründer schlägt sein Herz insbesondere für Start-Ups, Entrepreneure und innovative Firmen, welche die genannten Konzepte in der realen Welt umsetzen und berät diese in unterschiedlichen Projekten. Nebenbei leitet er den Studiengang CAS Pricing & Sales, ein Weiterbildungsangebot des Instituts für Marketing Management der ZHAW.
linard.barth@zhaw.ch / Telefon +41 58 934 68 67

Dr. Matthias Ehrat ist Dozent, Projektleiter und Start-up Coach am Product Management Center der ZHAW. Bereits seit seiner Ausbildung an der Eidgenössischen Technischen Hochschule (ETH) und der Universität St. Gallen (HSG) faszinieren ihn technologiegetriebene Innovationen. Durch langjährige Erfahrungen in verschiedenen Positionen in der Anlagenbau-Industrie konnte er sich ein breites Wissen im Betriebsmanagement aneignen. Er hält selbst mehrere Patente und berät Start-ups bezüglich den Schutzmöglichkeiten und der Anmeldungsverfahren ihrer technologischen Entwicklungen. Nebenbei leitet er den Studiengang CAS Industrial Product Management, ein Weiterbildungsangebot des Instituts für Marketing Management der ZHAW.
matthias.ehrat@zhaw.ch / Telefon +41 58 934 66 31