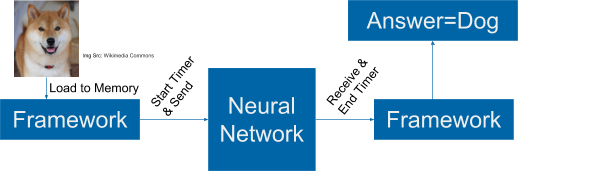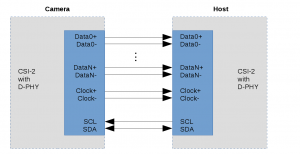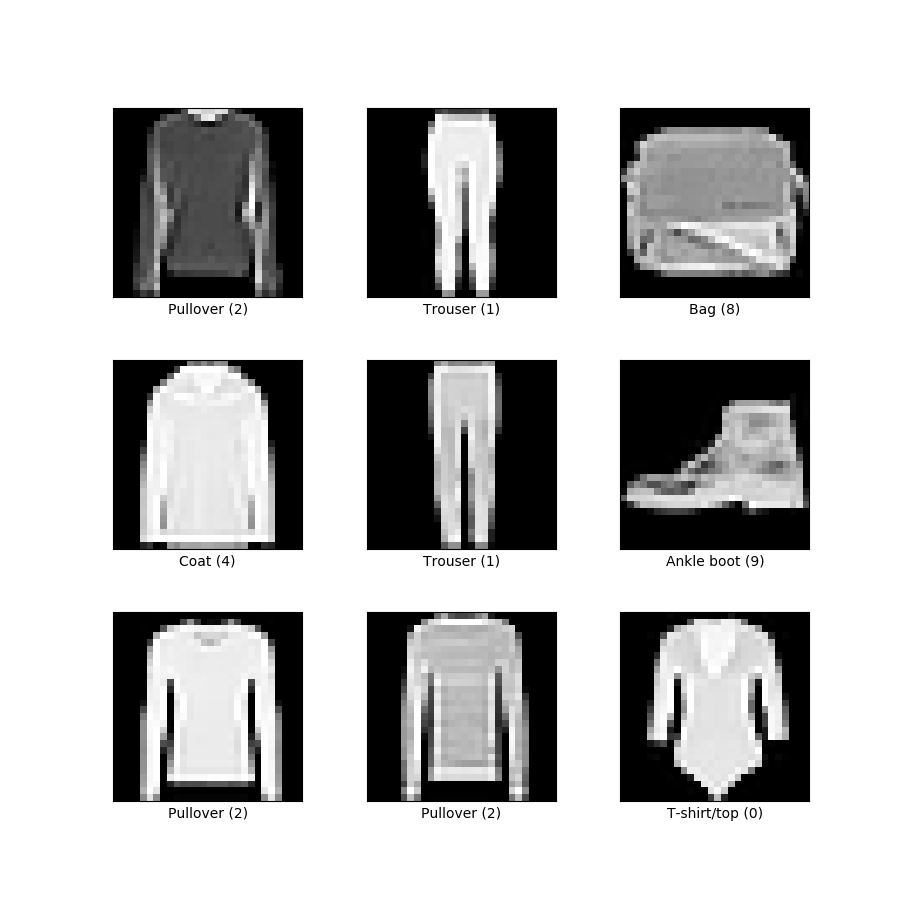
Train Analog Devices MAX78002 directly from Jupyter Notebook
For the past several months, we have been deep in the trenches with the ai8x-training tool and the training of various Convolutional Neural Network (CNN) architectures tailored explicitly for the MAX78000 and MAX78002 devices. Nevertheless, the ai8x training tool was more of a hindrance than a help. Among the myriad challenges we encountered, the inability to make […]