In a recent CTI project with our industry partner Nektoon AG we were involved in the development of the context intelligence application Squirro. In Squirro, users can create topics that consist of various text streams such as RSS feeds, blogs and Facebook accounts (see for example the following marketing video from Nektoon):
Defaulttext aus wp-youtube-lyte.php
One particular problem was to design and implement a method to identify text documents in a stream that a user might be interested to read. For example in an RSS feed of a company, a user might only be interested in a specific product of this particular company. Thus, he will generally ignore documents about other topics and would prefer to not seeing these anymore. The chosen approach is to infer the future interests of a user based on his past interactions with documents. From these actions we can determine a set of documents which the user is expected to be interested in and create a profile for each user using state of the art text feature selection methods. This allows us to calculate how well a document matches the usual interest of a user. According to this ranking we sort the documents and thus documents matching the user’s interest profile most closely rise to the top ranks.
To validate our method we created a test collection of 20 different topics containing approximately 2700 documents in total. For each stream, the relevance of all contained documents was judged and additionally, appropriate user interactions were performed to model a typical user. Subsequently, the user’s interests were estimated using the method described above and the documents were ranked accordingly.
RSS feed readers and the like normally sort documents by their publishing date. The following plot shows a comparison of the average precision[1] for different numbers of retrieved documents between our implemented ranking and the simple ranking by date. As expected, a striking difference becomes apparent.
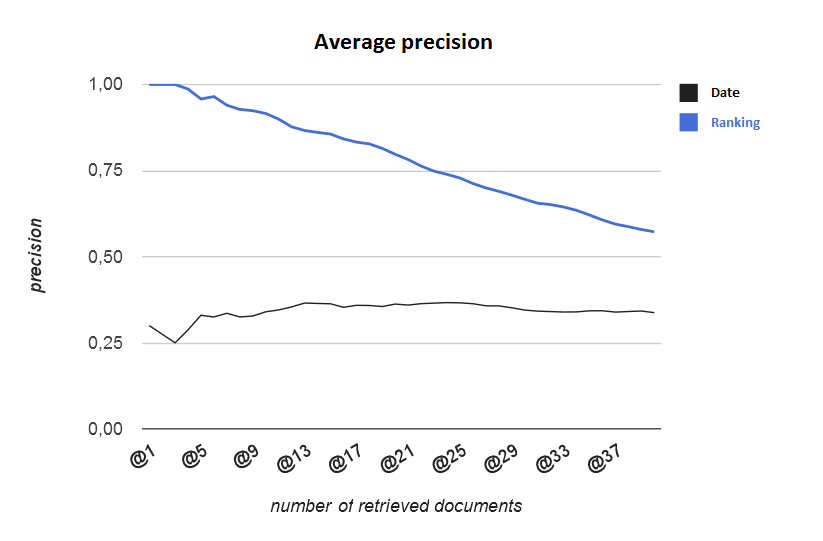
[1] Precision is a metric employed in information retrieval evaluation, which denotes the ratio of the number of relevant documents to the number of documents retrieved in a result set. The plot shows average precision over all 20 test streams (y-axis) at n retrieved documents (x-axis).