 Introduction
Introduction
SODA (Search over Data Warehouse) provides a Google-like search interface for querying an enterprise data warehouse. The tool enables non-tech savvy users, who do not have technical knowledge of the underlying database system or the query language SQL, to intuitively explore complex data warehouses. The main idea is to use metadata information about the data model as well as inverted indexes about the base data to generate executable SQL. SODA thus combines methods from database systems, information retrieval and semantic web technology to enable self-service business intelligence.
SODA was originally developed as a joint research project between Credit Suisse and ETH Zurich as part of the Enterprise Computing Center (http://www.ecc.ethz.ch/research/semdwhsearch). At Zurich University of Applied Sciences we will continue the research jointly with ETH Zurich.
SODA Architecture
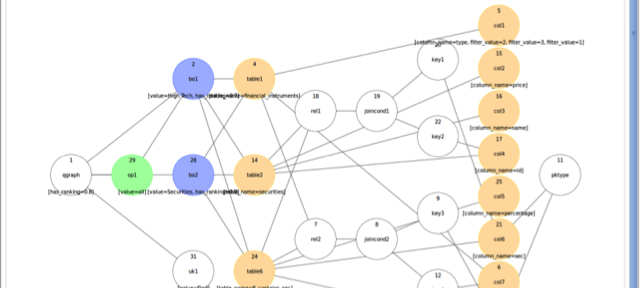
The main idea of SODA is to use a meta data graph as the basis for automatically generating executable SQL based on a Google-like search query [1]. The following figure illustrates the meta data graph.
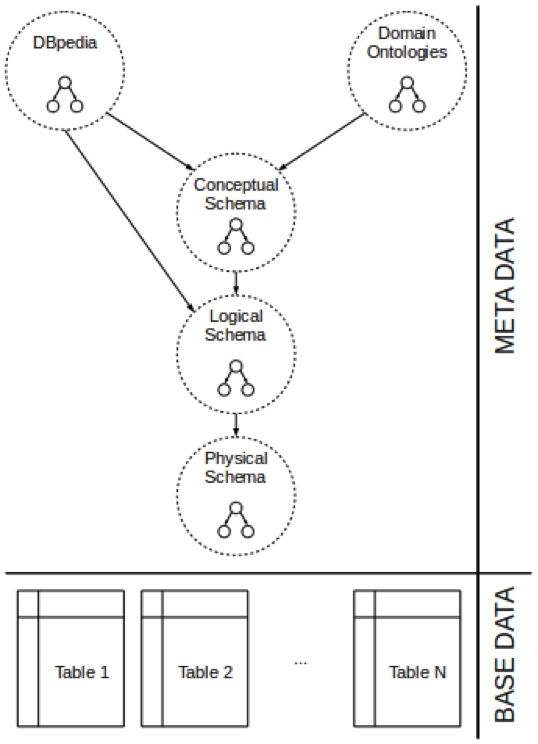
At the bottom of the figure we see the typical database tables of a data warehouse. We call them the base data.
Above the base data, we can see the physical, the logical and the conceptual data model. These models contain various levels of detail and are intended for different audiences. For instance, the business users typically use the conceptual data model, which shows the main entities of a data warehouse such as products, people and transactions. The logical data model contains more information while the physical data model contains the most detailed information, such as partitioning strategies of tables or indexes for fast data access.
In addition to the data models, SODA also stores information from DBpedia for handling synonyms. For instance, if a user searches for “customers” but the database only contains information about “clients”, she will not get any results back. However, since DBPedia contains the information that customer is a synonym for client, this query will yield correct results.
Moreover, the meta data is extended by a domain ontology which provides additional information about a specific field. For instance, a bank might have information about financial instruments and categorize them as options, futures or other structured products. If someone searches for bonds, the answer will be all financial instruments that are characterized as bonds.
SODA stores this meta data information as a graph that can be searched. In addition, SODA indexes all base data and stores the information in an inverted index – a data structure that is typically used in search engines to quickly retrieve content from web pages.
SODA Functionality
Let us now have a look at how SODA uses this meta graph as well as the inverted index to interpret user queries and to automatically generate executable SQL statements. Assume that the user searches for “customers Zürich financial instruments” as shown in the following figure:
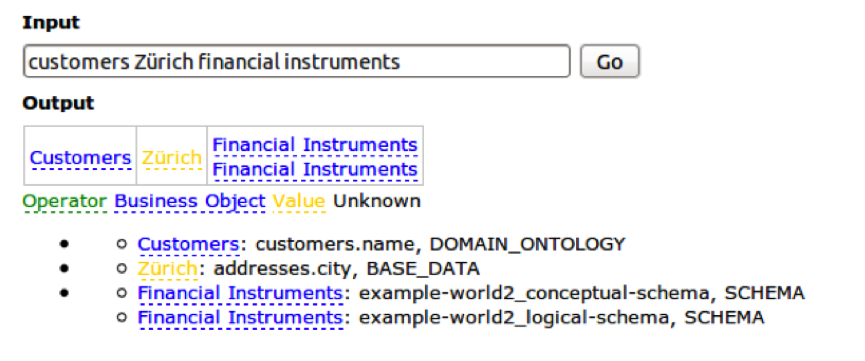
SODA analyzes each query string and categorizes it according to three items:
- Business object: A string can be found in the meta data graph, e.g. a database table is called “customers” or the domain ontology contains information about customers (see blue parts of the figure).
- Operator: Typical operations are top n, max, min etc.
- Value: A string can be found in the base data, e.g. the value “Zürich” is contained in the table cities (see yellow items of the figure).
Once the query is analyzed, SODA needs to find out which database tables are involved in the query. The following figure gives an overview of this mechanism.
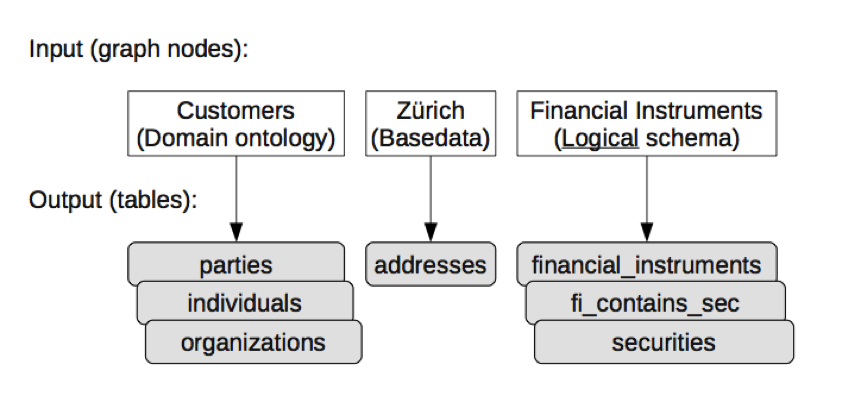
After the database tables are identified, the SQL statements are generated automatically. Since the meta data graph also contains information about primary-foreign key relationships, the join conditions are added as well.
An end-to-end view of SODA is given in the following figure which consists of these steps:
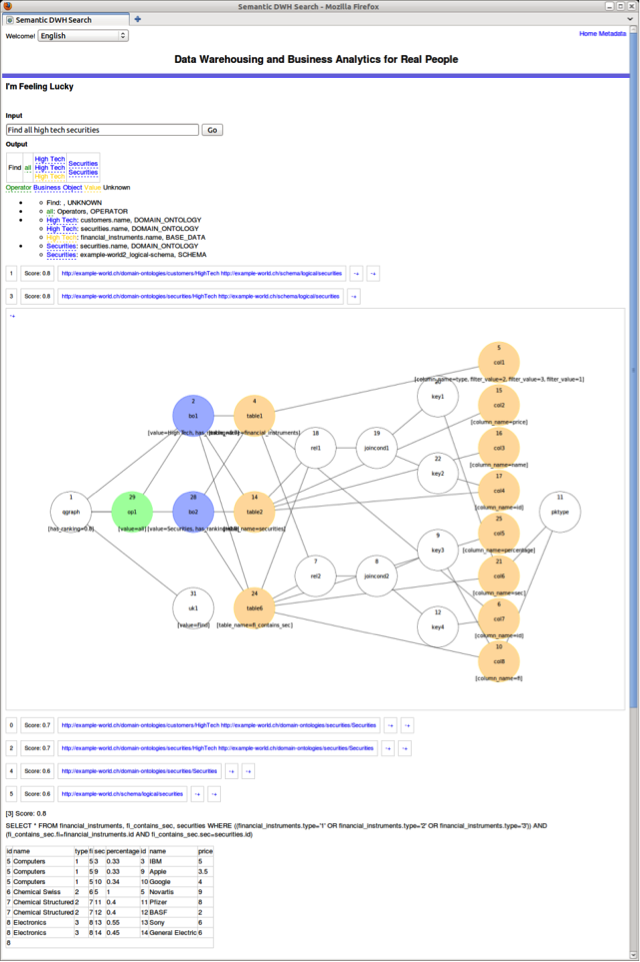
- Entering of keyword word
- Query analysis and categorization into business objects, operators and value
- Ranking of the results
- Visual interpretation
- SQL statement
- Query results in table form
Experimental Results
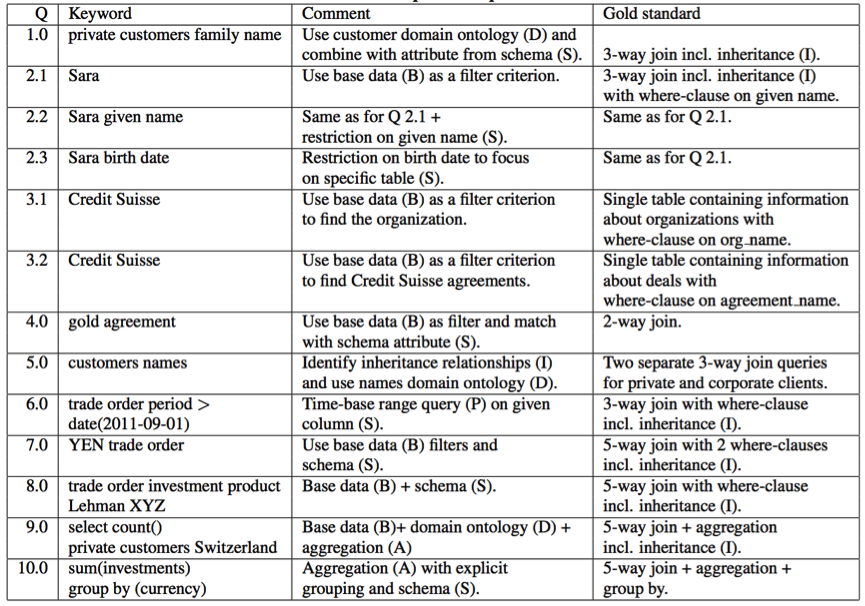
We evaluated to functionality of SODA against the enterprise data warehouse of Credit Suisse containing some 400 base tables. The table below shows the keyword queries that we used for our evaluation. In addition, we manually created the SQL statements that are the ideal answers to theses queries (gold standard). The goal was to compare the SQL statements that were generated by SODA against the gold standard.
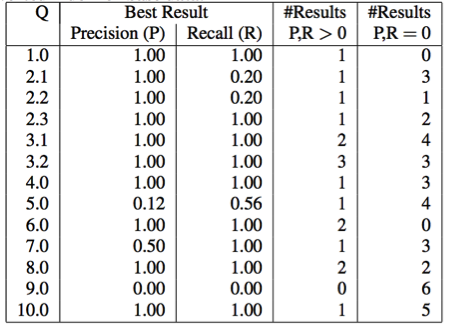
The table below shows the results of our evaluation in terms of precision and recall. As we can see, for a majority of the queries we have reached a precision and recall of 1.0 – which is optimal [1]. The table also shows how many resulting SQL statements were generated where precision and recall are above 0 and exactly 0, respectively.
The results were published at the major international database conferences and journals such as PVLDB (Proceedings of Very Large Databases) [1], ICDE (International Conference and Data Engineering) [2] and CIKM (Conference on Information and Knowledge Management) [3].
Future Research
The following section gives an overview of potential research avenues that can be explored to enhance the functionality of SODA:
- User Experience: Currently the users query SODA via a Google-like search interface. The next step is to provide faceted-search capabilities where the user will receive some suggestions about how to explore the data warehouse.
- Result Ranking: Currently SODA uses a simple ranking algorithm to prioritize search results. In order to come up with even higher quality results, a more sophisticated ranking algorithm needs to be applied on the generated SQL statements.
- Data Set Exploration: SODA was mainly tested on a large data warehouse from a major global bank as well as a sample data set to test corner cases of the SODA algorithms. Applying SODA to other domains such as bioinformatics or telecommunications will enhance the power of SODA.
Interested students and researchers who want to get involved in shaping SODA should contact Kurt.Stockinger@zhaw.ch.
References
[1] Lukas Blunschi, Claudio Jossen, Donald Kossmann, Magdalini Mori, Kurt Stockinger. SODA: Generating SQL for Business Users Proceedings of Very Large Databases. PVLDB 5(10):932-943, 2012.
[2] Claudio Jossen, Lukas Blunschi, Donald Kossmann, Magdalini Mori, Kurt Stockinger. The Credit Suisse Meta-Data Warehouse. International Conference on Data Engineering (ICDE 2012), April 2012.
[3] Lukas Blunschi, Claudio Jossen, Donald Kossmann, Magdalini Mori, Kurt Stockinger. Data-Thirsty Business Analysts need SODA – Search Over DAta Warehouse. Proceedings of the 20th ACM Conference on Information and Knowledge Management (CIKM 2011), October 2011.