Big Data Query Processing with Mixed Workloads
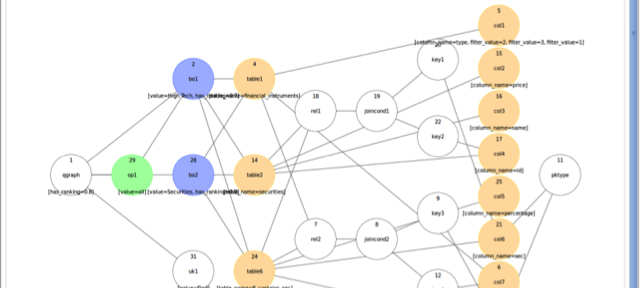
As part of a recent project called Big Data Query Processing we have evaluated complex query workloads using modern Big Data systems. In particular, we have performed benchmarks of Cloudera Impala using a business intelligence use case provided by an industry partner. The results can be found on the following blog post hosted by Cloudera: […]