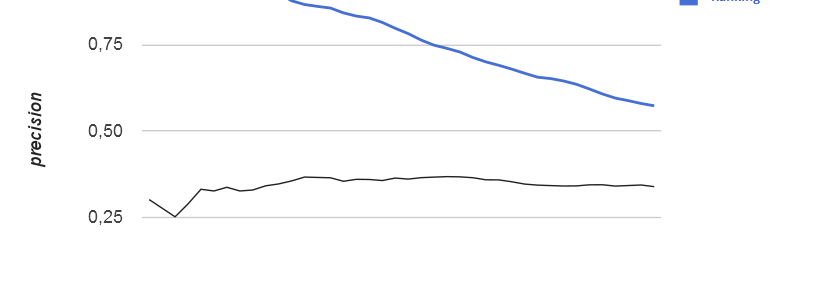
User-centric Learning to Rank
In a recent CTI project with our industry partner Nektoon AG we were involved in the development of the context intelligence application Squirro. In Squirro, users can create topics that consist of various text streams such as RSS feeds, blogs and Facebook accounts (see for example the following marketing video from Nektoon): Watch this video on […]