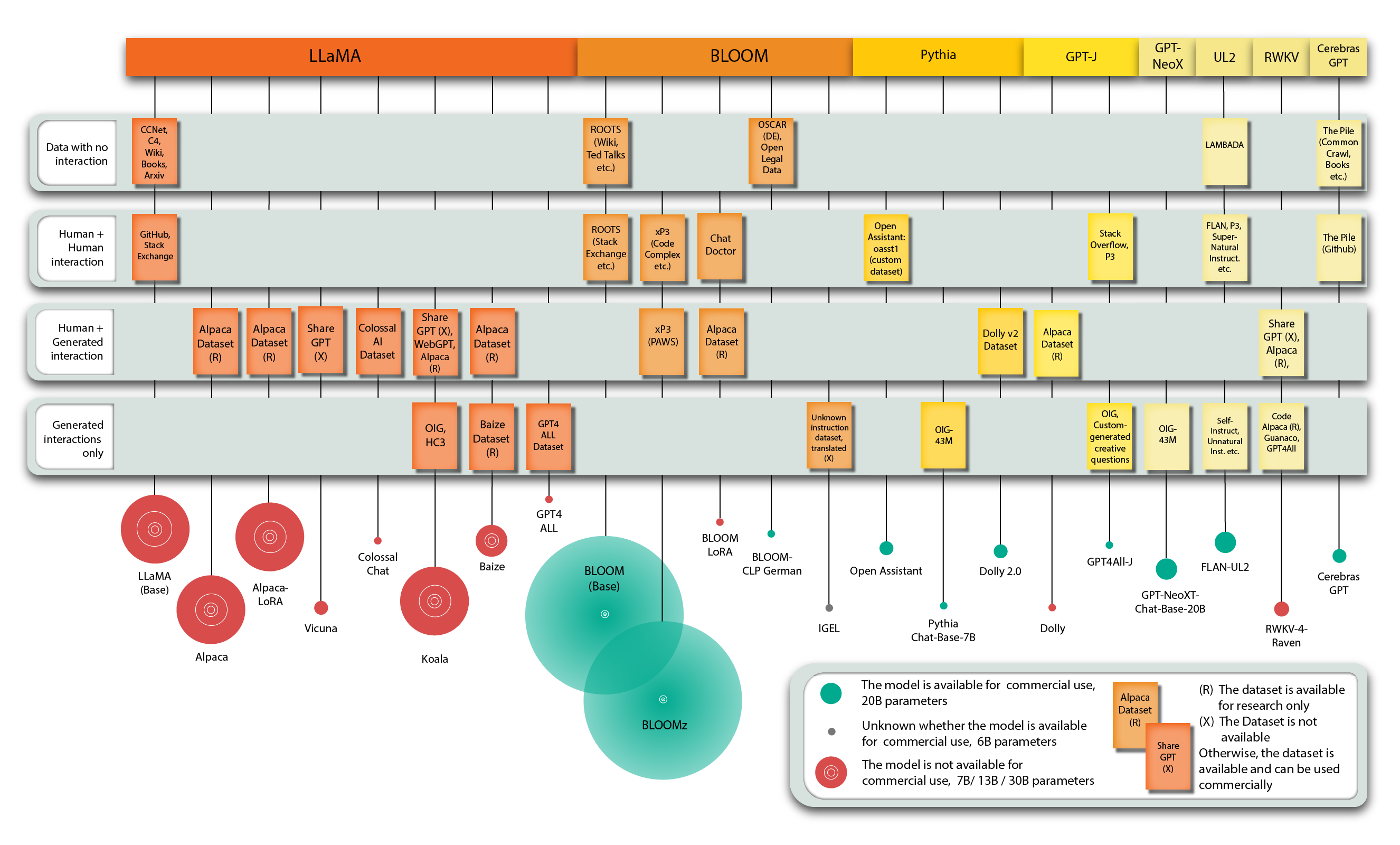
Deploy your own Open-Source Language Model: A Comprehensive Guide
ChatGPT caused quite a stir. While impressive, it’s a “black box”: it’s unclear how it was trained, what data it used, and it cannot be fine-tuned for specific use cases or sensitive data. The release of the more transparent LLaMA model (and likely its leakage on the internet) has led to rapid model development. First, a new model was released every month, then every week, and now every second day. Keeping up with the latest advancements is challenging and exhausting, but this blog post offers a guide to running open-source language models locally for researchers and businesses.