ChatGPT was a total bombshell, right?! It caused such a stir that some began questioning the very existence of Google Search and wondering if we should eliminate AI entirely before it eliminates us 😅. Despite these fears, it’s worth acknowledging that ChatGPT impressed both researchers and the public. It demonstrated that large language models can perform some tasks as well as humans. So, why would you want to deploy your own open-source language model? That is because there is a significant problem with ChatGPT: it is a black box. It’s unclear how it was trained, what data it used, and it cannot be fine-tuned for specific use cases or sensitive data.
And then LLaMA by Meta emerged as an alternative to ChatGPT, providing transparent data and training and was supposed to be shared with researchers globally. However, it leaked onto the internet, and the rapid pace of model development began. First, a new model was trained on top of LLaMA every month, then every week, and now every second day. Models such as GPT-J, Pythia, and BLOOM (which have been around for a while) have also joined the race. With the lightning-fast rate of model development, keeping up with the latest advancements has become exceptionally challenging. This blog post tries to offer a comprehensive guide to running open-source large language models locally and provides practical tips for researchers and businesses.
Just be aware: while I’m writing this words, there might be a new model or multiple models released, new methods developed that make this blogpost completely outdated 😅
Open-Source ≠ Free for commercial use
“I find ChatGPT really impressive, but my company deals with sensitive data. I’ve heard about LLaMA, an open-source model that I could deploy locally for my use-case. Is that right?”
The code used to train the LLaMA model was publicly released under the open-source GPL 3 license [1], and yes, you could deploy it locally if you officially apply for the model weights from Meta and receive them. However, you cannot use it commercially. LLaMA models are only intended for research purposes and are subject to a custom non-commercial license.
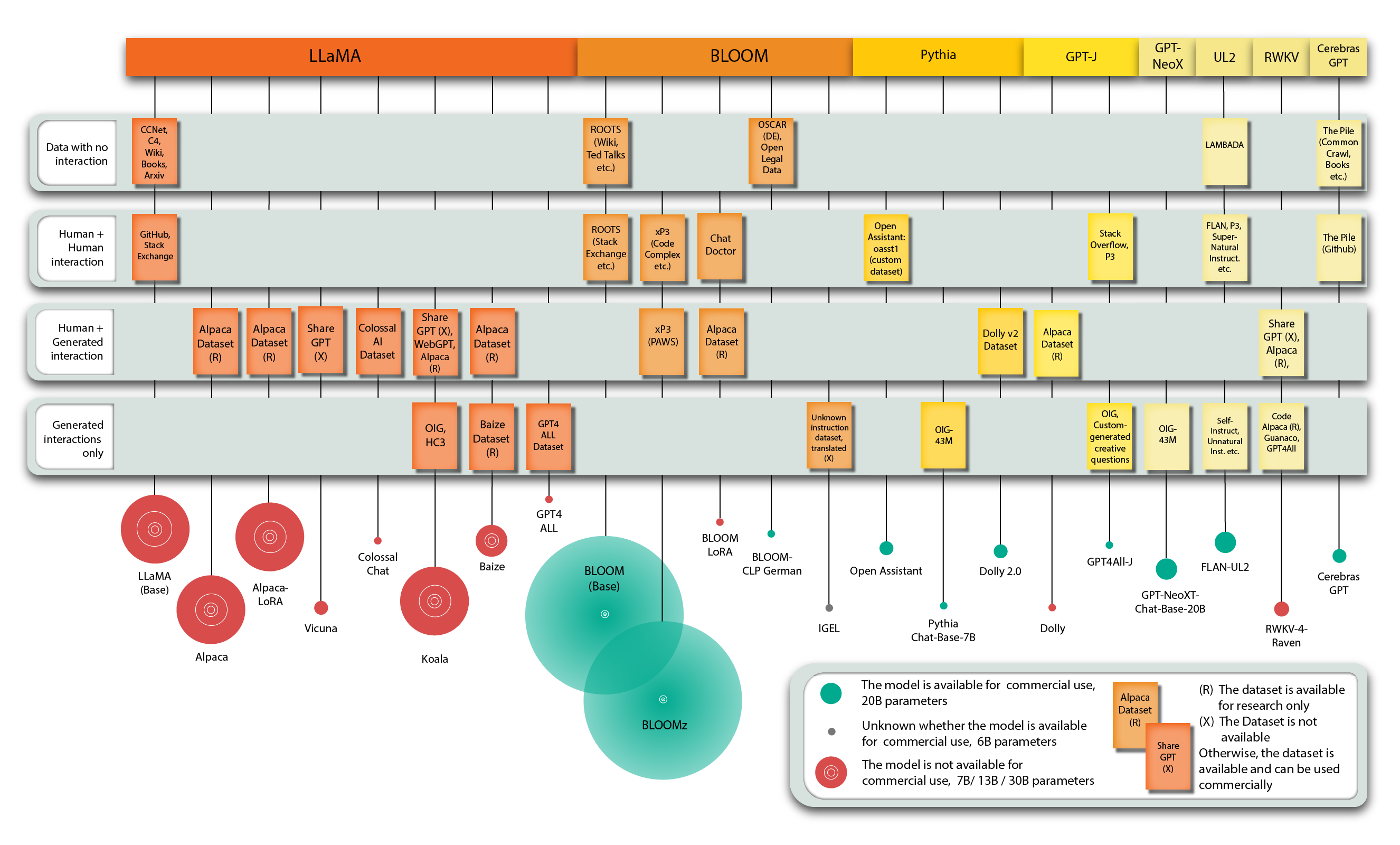
Below, you will find a list of “truly” open-source language models that can be used commercially, as well as open-source models intended for research purposes only.
Open-source-for-research-only models:
- All models based on LLaMA: Alpaca, Vicuna, ColossalChat, Koala, Baize, GPT4All,
- All models using Alpaca Dataset: BLOOM-LoRA, Dolly, RWKV-4-Raven.
Truly open-source models:
- BLOOM, BLOOMz, Open Assistant (Pythia models), Pythia Chat-Base-7B, Dolly 2.0, GPT4All-J, GPT-NeoXT-Chat-Base-20B, FLAN-UL2, Cerebras GPT
Deploying your own open-source language model
Let’s say you have decided on a model and are ready to deploy it locally. But what does “locally” mean? Can you deploy the model on your RTX 4090? The answer is, it depends. The following factors determine whether or not you can deploy your own open-source language model locally:
- The model itself
- The size of the model, i.e., the number of parameters the model has; the more parameters, the more powerful hardware you will need
- Whether or not you are using the full version of the model (as discussed in the next segment)
For example, one of the lightest models, Alpaca, has 7 billion parameters and can run with just 5 GB of RAM and no GPU required when using a 4-bit quantized model with alpaca.cpp (details below). On the other hand, one of the heaviest models, BLOOM, has 176 billion parameters and requires 8 80GB A100 GPUs to run the full version.
You mentioned the “4-bits quantized model” above. What is that all about?
If you come across something like LLaMA (8-bit) or Alpaca (4-bit), it means that it is a “lighter” version of the named model. This process is called Quantization.
Quantization involves converting floating-point numbers to integer numbers to save memory and perform faster arithmetic operations. This is achieved by using a lower bit precision (e.g., 4 or 8 bits) for the integer numbers, compared to the higher bit precision (e.g., 16 or 32 bits) used for floating-point numbers. You can apply quantization to the weights, which reduces memory usage, or to both weights and activations, which allows for faster arithmetic operations. Quantization can be applied during training/fine-tuning as well as during inference (post-training quantization, PTQ). Most open-source language models support quantization. However, as nice as it may sound, it has been shown that quantization may result in some quality loss. One study on PTQ can be found here.
If you are using a model from Hugging Face, quantization is applied via the library bitsandbytes and you basically just have to add load_in_8bit=True to the parameters when loading the model to load an 8-bit quantized model.
You also mentioned “alpaca.cpp” above. Can you elaborate that?
If you see “alpaca.cpp” or “llama.cpp”, it means that it is an inference model in pure C/C++. Running the language model in C/C++ offers performance benefits due to the speed and efficiency of these programming languages. They also provide more control and flexibility when implementing complex algorithms or optimizing performance-critical code. Using inference models in pure C/C++ allows for running the models on CPU only and using much less memory. Here is an example of the RAM requirements to run LLaMA models:
| Model | Original size | Quantized size (4-bit) |
| 7B | 13 GB | 3.9 GB |
| 13B | 24 GB | 7.8 GB |
| 30B | 60 GB | 19.5 GB |
| 65B | 120 GB | 38.5 GB |
An even easier way to run .cpp versions of many open-source language models locally is to use Dalai.
As previously mentioned, using such models can allow you to run a large language model on your laptop or even your phone but beware: even the creator of the models admits that they were created very quickly and were not thoroughly tested for correctness [2].
| Exist | Seem not to exist |
| LLaMA Alpaca GPT4All Vigogne (French) Vicuna Koala RWKV BLOOM BLOOMz | Open Assistant GPT-NeoX-Chat-Base-20B Pythia-Chat-Base-7B Cerebras-GPT |
The model is running. But what can I do to improve its performance?
The first thing you can try is to improve your prompts. The most comprehensive guide for better prompting for commercial as well as open-source language models known to the author of this blog post is promptingguide.ai. The creators of the source have done an amazing job putting different techniques and experiences together, which is why we will not go into detail here.
If improved prompting does not help you achieve the results you are aiming for, you can try training or fine-tuning the desired model.
How to train fine-tune your open-source language model
Let’s be clear: when you come across the term “train.py”, it mostly refers to fine-tuning rather than training your model from scratch. It is not recommended to train your language model from scratch when multiple pre-trained open-source language models already exist. As an example, the BLOOM 176B parameters model was trained on 416 A100 80GB GPUs for 4 months, while training LLaMa 65B took 21 days and (!!!) 2048 A100 GPU 80GB GPUs.
For fine-tuning, you will need a powerful GPU, and in most cases, a consumer-grade GPU will not be enough. To fine-tune the full model GPT-NeoX-Chat-Base-20B, you would need 8 x A100 GPUs, for example. However, as with inference, there are ways to reduce the hardware requirements for fine-tuning, such as the previously mentioned quantization. For the same model (GPT-NeoX-Chat-Base-20B), you would only need 6 x A100 GPUs if you use 8-bit quantization.
When reading about optimizing the training/fine-tuning process, you may come across various approaches. You might have seen terms such as LoRA, PEFT, and ZeRO. Here we will dive a little bit into what some of these terms are and how they optimize the training process.
Parallelism and distribution in training.
Parallelism is a framework strategy to tackle the size of large models or improve training efficiency, and distribution is an infrastructure architecture to scale out [3]. Common types of model parallelism include data, sequence, pipeline and tensor parallelism. Most models are already using some sort of parallelism and / or distribution. One of the most used approaches for parallelism is Zero Redundancy Optimizer (ZeRO).
- ZeRO is a tool that helps in training large deep learning models faster and more efficiently by reducing memory usage and increasing the size of models that can be trained. It does this by eliminating memory redundancies in both data-parallel and model-parallel training, while still maintaining high computational granularity and low communication volume. This allows the model size to be scaled up in proportion to the number of devices being used for training, while maintaining high efficiency.
PEFT (Parameter Efficient Fine Tuning)
PEFT is a way to adapt pre-trained language models for different uses without having to fine-tune all the parameters; instead, it only fine-tunes a small number of extra parameters, making it less computationally and storage expensive, while still achieving good performance. Supported methods on Hugging Face are:
- LoRA: Low-Rank Adaptation of Large Language Models. LoRA reduces the number of trainable parameters by freezing the pre-trained model weights and adding trainable rank decomposition matrices to each layer of the Transformer architecture. Published in 2021, this method is relieving a new wave of popularity as most of the open source models have a LoRa version by now. For example, as stated in the Stanford Alpaca Github repository: “LoRA fine-tunes low-rank slices of the query, key, and value embedding heads. This can reduce the total memory footprint from 7x4x4=112GB to about 7×4=28GB.”
- Prefix-Tuning.
- P-Tuning.
- Prompt Tuning
- AdaLoRA
Other parameter-efficient fine-tuning methods are: BitFit, Diff Pruning, Adapter tuning etc.
Gradient Checkpointing.
During the backward pass, all activations from the forward pass are normally saved, which takes up a lot of memory. Gradient checkpointing saves only a subset of activations strategically during the forward pass and recomputes them during the backward pass, reducing the amount of memory needed while still maintaining efficient training (but slowed down normally by 20-30%) [4].
Gradient Accumulation.
Instead of calculating the gradients for a whole batch at once, it is done in smaller steps by iteratively calculating the gradients in smaller batches and accumulating them. Once enough gradients are accumulated, the model’s optimization step is run. This allows using larger batch sizes that wouldn’t fit into the GPU’s memory otherwise, but it can also slow down training due to additional forward and backward passes. Gradient Accumulation essentially is identical to having a larger batch size, just as with the larger batch size here you are likely to see a 20-30% speedup due to the optimizer running less often [4].
FlashAttention
FlashAttention is an exact IO-aware attention algorithm that reduces the number of memory reads/writes between levels of GPU memory by using tiling.
Mixed precision training.
Mixed precision training reduces memory usage and speeds up computations by using half (16-bit) precision for some variables and computations, but still converts the gradients back to full (32-bit) precision for optimization. But it can result in more GPU memory [4].
I’ve seen that some models use RLHF. What is that? Do I need it?
Reinforcement Learning from Human Feedback (RLHF) is a method that optimizes a language model (LM) using human feedback as a measure of performance. RLHF involves three core steps: pretraining a language model, gathering data and training a reward model, and then fine-tuning the LM with reinforcement learning. The initial LM used in RLHF is a pre-trained model that can but does not have to be fine-tuned on additional text or conditions.
To create the reward model, a set of prompts is chosen from a list or created by people. The base model generates text based on these prompts, and humans rate the quality of the text. The ratings are used to create a dataset that trains the reward model. This reward model is important because it helps the base model understand what kind of language people prefer.
Open-source models using RLHF:
- ColossalChat,
- Vicuna,
- Open Assistant (implementation in progress),
- Can be used in ChatLLaMA
Worth noting
Even though it appears on a list with other models and sounds like another LLaMA-based model, ChatLLaMAis not a stand-alone model but a library that allows you to create hyper-personalized ChatGPT-like assistants using one of several available language models (LLaMA, GPTJ, GPTNeoX, Flan-T5, OPT, BLOOM, BLOOMZ, Galactica) as a base. You can apply one of the reward models (GPT2, OPT, GPTJ, BLOOMZ, OpenAssistant) and use your own data or generate the data as a part of the pipeline by using the least amount of compute possible.
Another solution to applying RLHF to mention is DeepSpeed Chat. DeepSpeed is a deep learning optimization library that enables distributed training and inference. This technology is widely adopted in the AI community because it allows building and running very complex models quickly and efficiently on resource-constrained GPU systems as well, and it can also make the models smaller and faster to use.
Deep Speed Chat RLHF is a system that offers solutions for running RLHF training from single scripts that apply RLHF on any model present on Hugging Face through the pipeline that replicates the training pipeline from the InstructGPT paper to RLHF system that combines the training and inference into a single Hybrid Engine.
Do you have to use RLHF? According to the creators of the models that use RLHF, it improves the quality of the models, but there is no concrete data to support this claim. Evaluating text generation systems is a challenging task, and you can learn more about why that is the case by reading here.
Let’s not forget about the data. What are the options here?
Disclaimer: The following classification of data is proposed by the author of this blog post and has not been adopted by the AI community.
The first group of available data can be described as mega-datasets that consist of various smaller datasets. These are usually used to train base or text-completion open-source language models like LLaMA and BLOOM. They cover different tasks, such as summarization, question answering, and sentiment analysis, or consist of plain text or code, such as the Github, Wikipedia, Arxiv, and Books datasets. Most datasets in this group do not have an interactive nature and all datasets in the list below can be commercially used.
The datasets are:
- The ROOTS,
- The Pile,
- LAMBADA,
- OSCAR,
- xP3,
- FLAN,
- P3,
- Data used for LLaMA. Even though it doesn’t have a dedicated name, it could be one of such datasets as it consists for example from CCNet, Arxiv, Books, Github datasets etc.
In order to train a chatty model you would need data that has an interactive nature. Here, your choices are divided into three groups: data that is fully created by humans, data that is partially created by humans and partially machine-generated, and finally, data that is fully automatically generated by one or multiple language models.
The datasets in the category Human+Human are all free for commercial use:
- Open Assistant dataset,
- ChatDoctor,
- Super-Natural Instruct.
Human + Generated:
- ColossalAI Dataset,
- WebGPT,
- Dolly v2 Dataset,
- Alpaca Dataset (non-commercial use only).
Fully generated datasets:
- OIG,
- HC3,
- Baize Dataset (non-commercial use only),
- GPT4All and GPT4ALL-J Datasets
- Guanaco.
What if my model needs to answer customers’ questions based on company’s info?
In that case you probably want to check out LangChain Framework, which can help you doing that. You can learn about it now by following the link or wait for our next blog post, where we’ll explain what LangChain is, the models it supports, and how it works.
Conclusion
We hope this blogpost cleared some things for you and inspired you to try and deploy one of the models. Please let us know in the comments about your experience and stay tuned: as next we will dive into the LangChain framework.
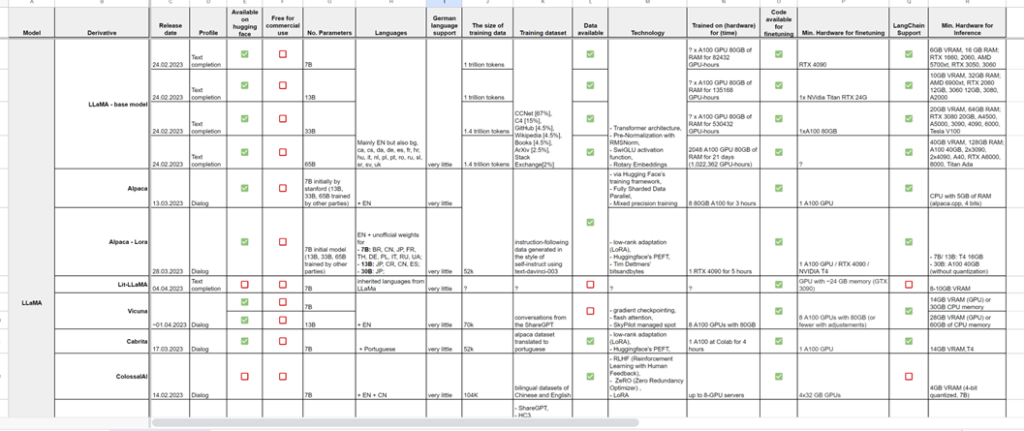
P.S. A BIG overview of the most important open-source models can be found here.
[1] https://en.wikipedia.org/wiki/LLaMA
[2] https://github.com/ggerganov/llama.cpp
[4] https://huggingface.co/docs/transformers/v4.18.0/en/performance
excellent work, excellent summary.
great work, will wait for your next blog.
Thanks, this is a very helpful overview, well done!
Looking forward to the article about LangChain