
What is the difference between human and ChatGPT’s understanding of language? Let’s ask linguistics.
It’s over a year since ChatGPT’s release to the world. There is still a lot of hype going around regarding whether ChatGPT and its later versions, including GPT-4, have a “true” understanding of human language and whether we are now close to an Artificial General Intelligence (AGI) that is as intelligent as (or even more intelligent than) humans and could possibly enslave humanity. In this article, we will explore the fabric of what ChatGPT learns about human language from a linguistic vantage point, uncovering the similarities and vast disparities to our human understanding, which will hopefully help to put some of the claims made by AGI evangelists into perspective and alleviate fears of AI domination of the world.
How does ChatGPT “learn” human language?
It’s shockingly simple. Large Language Models (LLMs) like ChatGPT are trained with a task called “next token prediction”. This simply means that the model is presented with a few words of a human written sentence (e.g. taken from Wikipedia) and is asked to predict the next word. The model prediction is compared to the actual word that follows in the sentence. If the prediction is incorrect, the model (which is a neural network, i.e. lots of matrices stacked onto each other) is updated so that the next time it sees the sentence (or a similar one), it is more likely that the actual next token is predicted. That’s it, really.
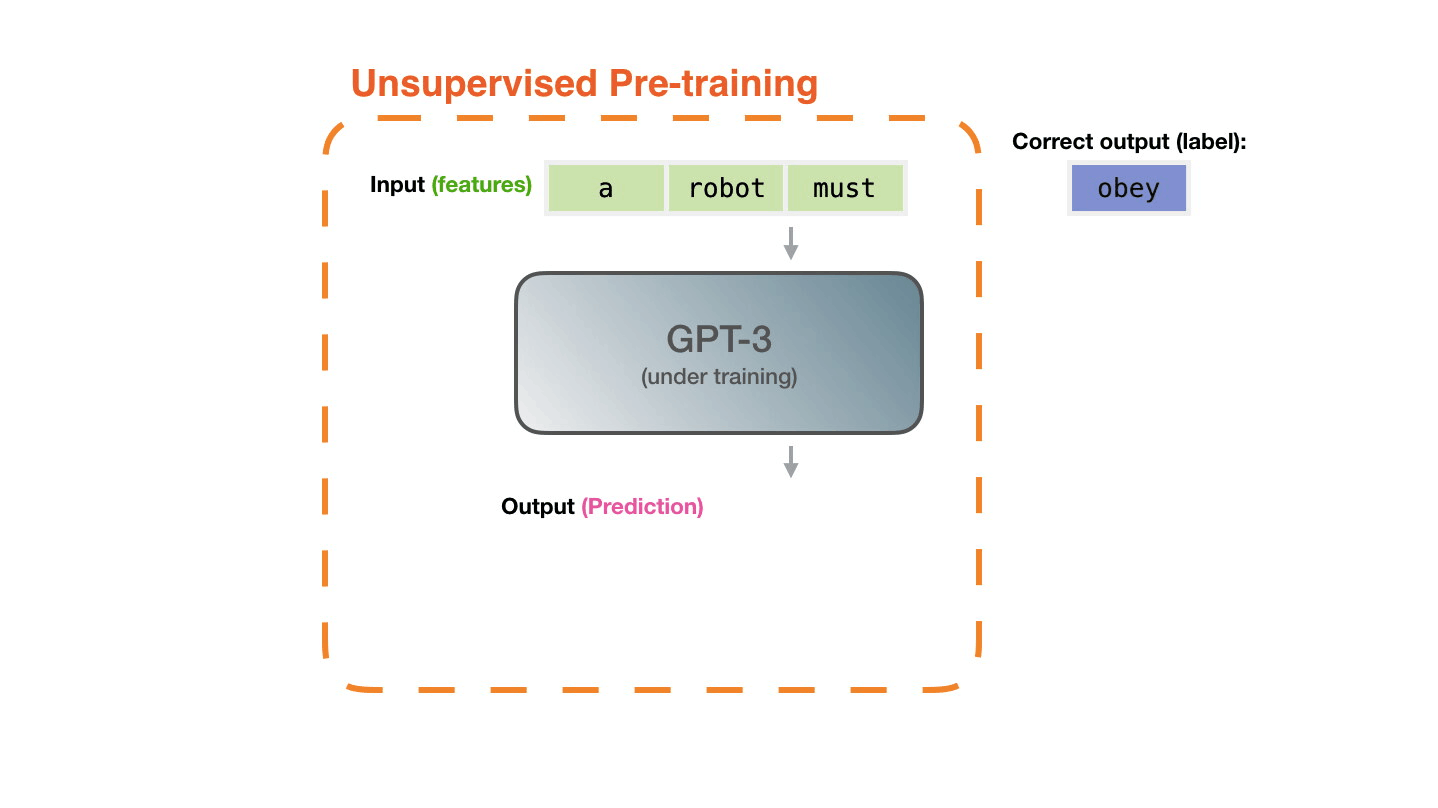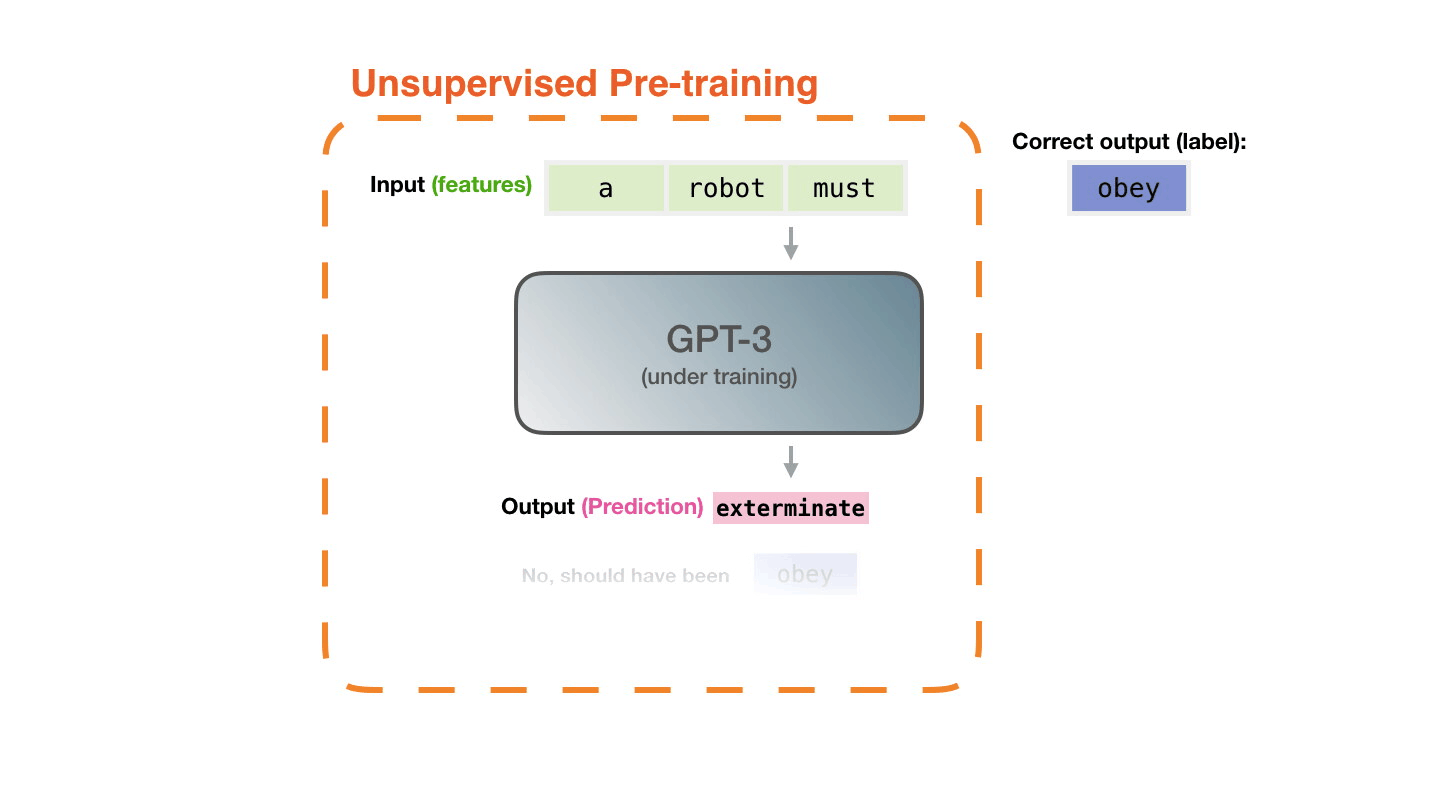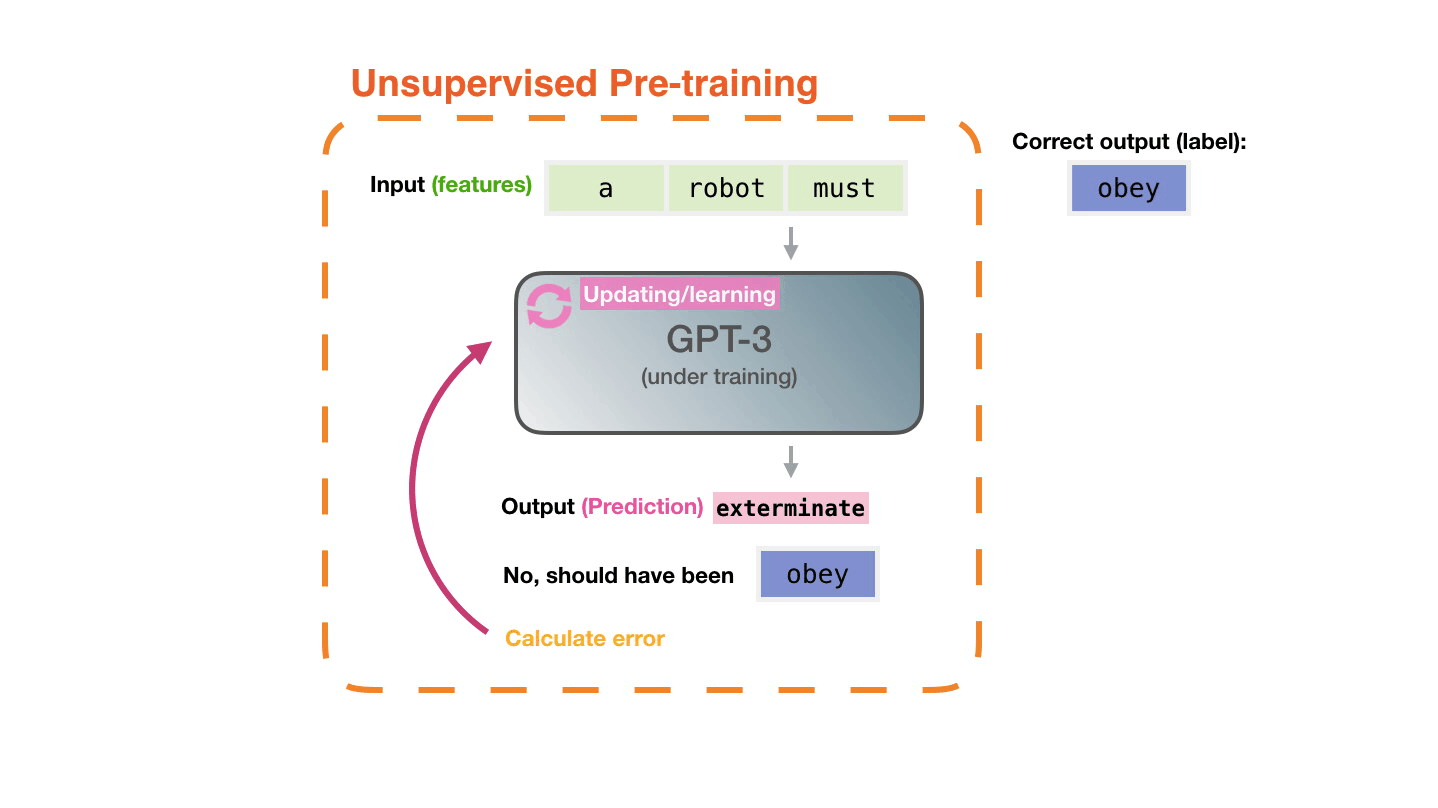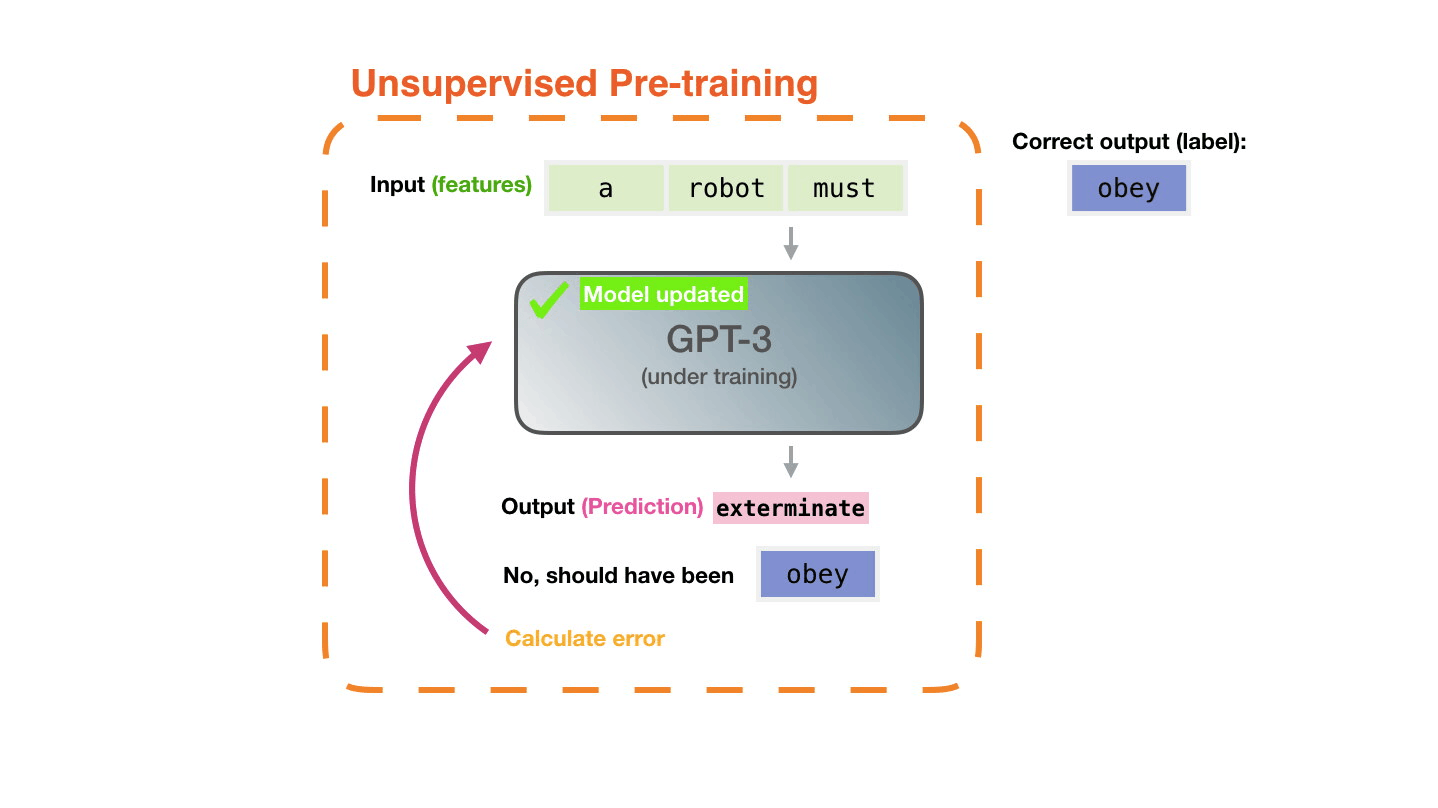
Now, the next shocking thing is that this actually works quite well, and we discovered the “scaling laws”: The more you scale up the neural network size (more matrix stacking) and the more sentences you give the model to train on, the more capable the model becomes. Google Research has made a nice analysis and visualization of the scaling laws:
They found that a model with 8 billion parameters (8 billion numbers in those stacked matrices) can do some question answering quite well, but it isn’t any good at, for example, translation or summarization. When the model size is increased to 540 billion parameters (but the model architecture concept and training procedure stay the same), the capability to, for instance, translate and summarize text emerges in the model. Surprisingly, we can’t really explain why this happens, but it’s something that we observe and exploit by making models bigger and bigger.
Alright, that’s how ChatGPT learns language. Why does it know so much?
ChatGPT and its siblings have ingested billions of words in their training – a lot more than any human in their upbringing. To give you an impression of how much 300 billion “tokens” (ChatGPT’s version of words)1, the training data size of GPT 3, are: If you print out 300 billion tokens on A4 paper (500 words per page) and stack them, you get a tower that is roughly 60 kilometers high – that’s where the stratosphere begins, or the height of stacking more than 70 Burj Khalifas on top of each other.
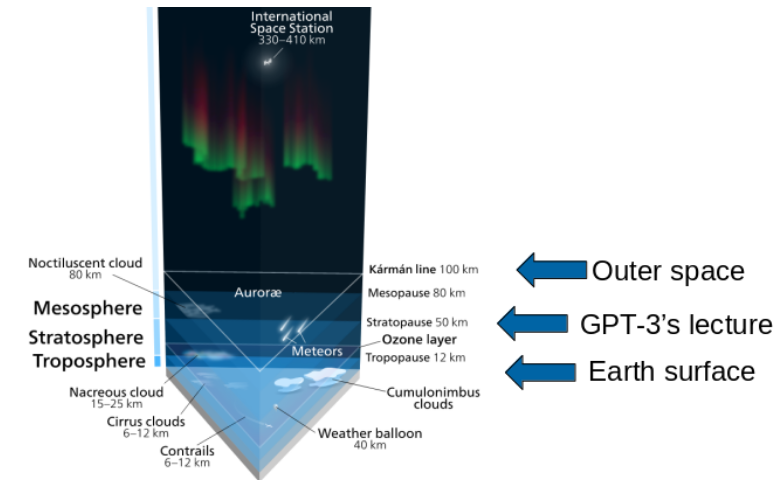
Clearly, that’s a lot more than what any human has read – You could do it in about 5700 years if you read 200 words per minute for 12 hours a day. When it comes to reading history and volume, ChatGPT clearly has the upper hand.
Okay, so ChatGPT has ingested a lot more texts than I can ever read. What’s the difference then between my language understanding and ChatGPT’s?
Yes, is ChatGPT not simply more powerful than you because of how much it has read? Well, let’s take a look at how we humans understand and represent the meaning of a word that we have read, let’s say the word “pipe” (as in smoking pipe). There is a famous painting by the painter Magritte:

The painting has a text written in it that says “This is not a pipe” while there clearly is a pipe visible in the painting. But wait.. is there really a pipe in the painting? Of course not, there is only a painting of a pipe. This funny and ingenious painting demonstrates an intuitive but not always obvious distinction in a simple way: There is a difference between the things we refer to and the things we use to refer to them. Trivially, a painting of a pipe is not a “real” pipe, it can be seen as a symbol that references a (real or imaginary) pipe.
You might be wondering by now why we are talking about paintings of pipes when we try to drill down on the difference between our understanding of language and that of large language models. Bear with me, because through this door, we have entered the domain of semiotics, the study of signs and symbols. We can apply this distinction between real-world things and the symbols that we use to reference them to language and words seamlessly: The Swiss linguist Ferdinand de Saussure presented a well-known model that consists of “the signified” (signifié; i.e. a real pipe) and “the signifier” (signifiant; i.e. the word pipe or Magritte’s painting of a pipe).

While this seems to represent something trivial and obvious in hindsight if you think about it, it builds the basis for a more refined model of how we humans use and work with symbols to communicate with each other, which we can use to illustrate the difference of how we humans and large language models learn and represent the meaning of words differently: The Semiotic Triangle.
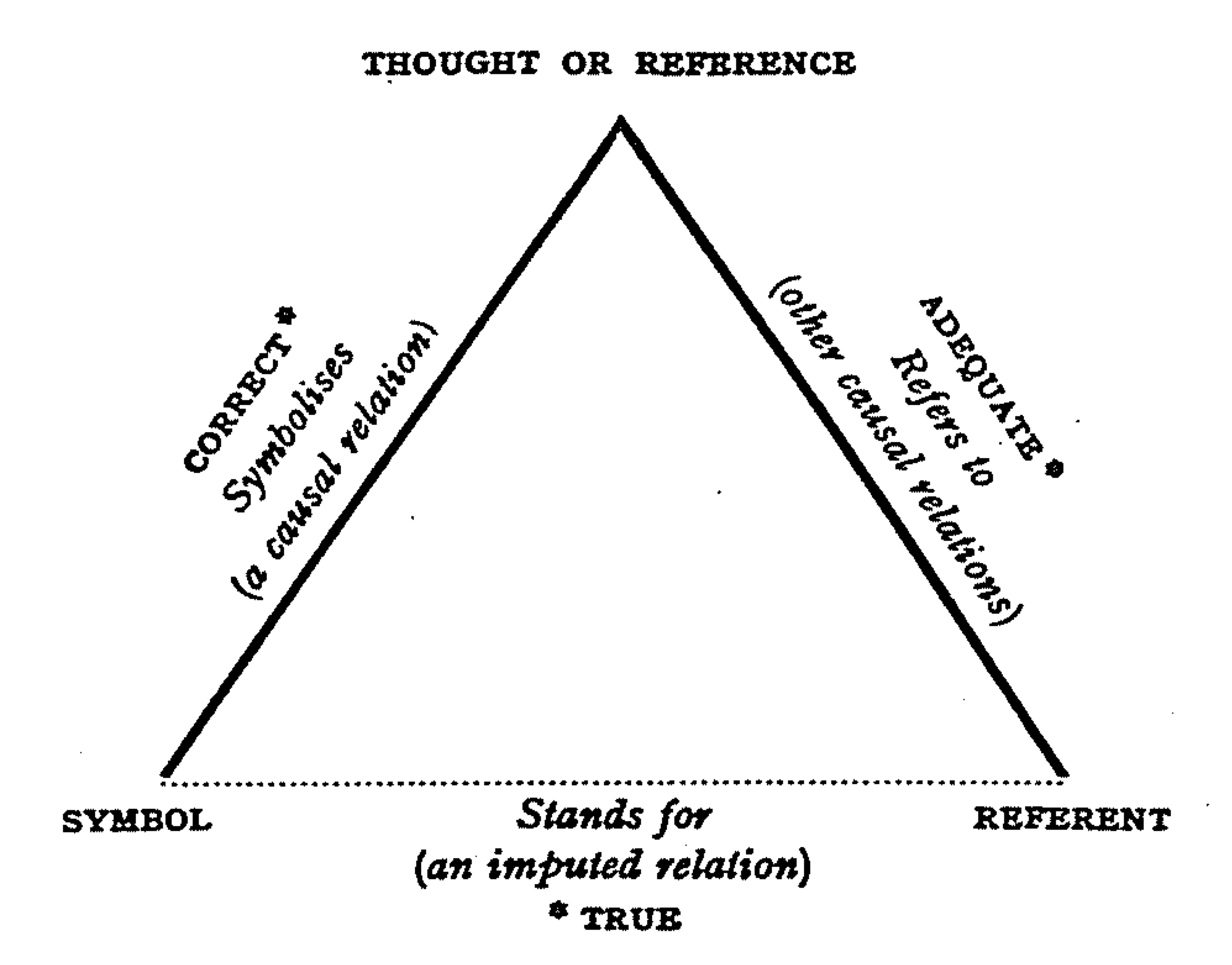
While the semiotic triangle includes the symbol (signifier) and the referent (signified) of de Saussure’s model, it adds a third, crucial component – the “reference”. The reference is your internal mental representation of the real-world objects around you, for example, Magritte’s painting of a pipe. I can talk to you about a pipe without it being in the same room as we are in, because I (and you) have built an internal mental representation of a pipe: the reference in the semiotic triangle. I can use a “symbol” (i.e. a word or phrase pipe) to verbalize this reference for communication with you, and, since you also have a reference of a pipe, we can talk about it, although there is no pipe before us that we can point to (and we can also talk about Magritte’s painting of a pipe, i.e. we use a textual symbol to reference a visual symbol of a non-existent pipe – pretty wild!).
Symbols, real-world objects, and our internal reference to them, got it. We use symbols to verbalize our mental references of things to talk about the things – the semiotic triangle, neat. Now how does this help me to understand the difference to how ChatGPT understands language?
One crucial aspect of this model is the mental representation, the reference. We humans build and shape our mental representation of things as multi-sensory beings in an organic structure (the brain) that is directly coupled with the sensors. Our representation of things (the references) is an amalgam of bio-chemical and bio-electrical processes and experiences of our interactions with the real world and its effects on us. Let’s take an emotionally loaded word like “love”, for example: If we think about the word, it can trigger all sorts of memories and associations: our personal experiences, songs, poems, movies; the activation of the representation can even invoke physical pain or exaltation, i.e. the activation of the reference that in turn re-activates certain bio-chemical processes.
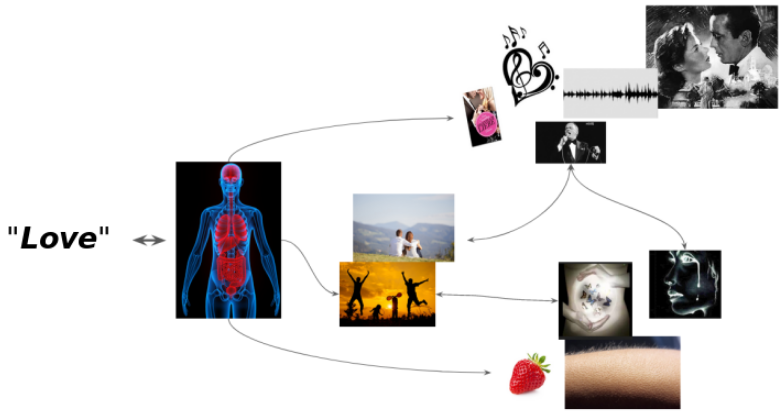
Now, an interesting property of the relation between the symbol and the reference (or referent in de Saussure’s model) is that it is arbitrary. There is no system, algorithm, or rule that helps you figure out why a tree is called tree. Nothing, none of the properties of a real-world tree gives you any hint why you should call it tree; the sequence of characters tree does not have any obvious connection to an actual tree. You could use any other (made up) word to refer to a tree, so long as all other speakers agree to use this word to refer to trees. That is, words can be seen as arbitrary artifacts that we use to communicate about our representations of things in the world. We learn the assignment of words to real-world entities throughout our childhood and through demonstration and experience (Your parents point to a tree and say This is a tree.)
I sense that you’ll be saying that a computer is not a bio-chemical system and that’s the difference. But ChatGPT is an artificial neural network, isn’t that somehow like the human brain?
Sorry for taking so long, we are arriving at the crux! Yes, artificial neural networks are inspired by the human brain, but that’s not the important part now. Let’s now (finally) put the semiotic triangle to good use to see what differs between human word representation and word representations in large language models. The main differences are simply:
- ChatGPT never has direct access to the referents, i.e. the real-world objects. It has no memory of real-world interaction with, for example,a tree. It has no sensory apparatus to experience a tree.
- Therefore, it cannot build a reference of objects in the way we humans do.
- There is nothing that the symbols in the triangle can be assigned to!
So ChatGPT is missing two out of three components that our language understanding encompasses in the Semiotic Triangle!
But then how can ChatGPT learn anything about language at all? It clearly does!
Good point! What actually happens during the training of LLMs is that they do build a kind of reference, or better, representation of the symbols, i.e. words, but not the referents (the models have no access to the real-world objects). These LLM representations are simply numbers in matrices that are optimized during the training procedure. As we said at the beginning of the article, the task used to optimize these numbers is next word prediction. Given, for example,an incomplete sentence: what is the next (missing) word in the sentence? That is, LLMs learn to predict which words fit into which contexts and they do so by updating a randomly initialized matrix representation of words which they use for the predictions. That means everything that an LLM ever “sees” in the symbolic triangle are symbols. Through optimizing the word prediction task, the underlying neural network (the word representations) in LLMs picks up patterns and regularities in the word sequences. These representations can be thought of as representing the meaning of words, similar to how the reference in the human brain represents the meaning of a word. Crucially, this meaning representation in LLMs is formed only by observing symbols and the relations between them. And this works surprisingly well!
There is an actual theory of meaning in linguistics that describes this kind of meaning acquisition through symbol observation only: Distributional Semantics. This is, in fact, the whole linguistic theory on which modern NLP since the inception of word embeddings like Word2Vec (and even before that) relies! So what does it say? A colloquial phrasing of distributional semantics is: “Know a word by the company it keeps”, or “The meaning of a word is derived by the context it occurs in”. This observation is the basis for, for example, the Cloze tests in language learning, where the learners have to fill in missing words into a given sentence. And this is exactly the task that LLMs learn to solve!
So what does this difference mean for the language understanding of ChatGPT?
Or put differently: Does it really matter that LLMs have a different mechanism to learn meaning representations? The answer is: it depends. We all know that we can do and achieve amazing things with LLMs that took way more effort before November 2022 or weren’t even thought possible back then. There are two things to consider:
- One has to be aware of the limitation of the meaning representations of LLMs: Because they lack a human reference system, they cannot infer and reason in the same way we do. For creating a spam classifier this is probably less crucial than when trying to automate essay grading, juridical decisions, or governmental policies.
- The discussion of the potential emergence of Artificial General Intelligence or human-like intelligence in LLMs is rarely informed about linguistic aspects of language learning and processing. Having a linguistic understanding of what happens when we communicate certainly helps clear up some expectations and fears in that regard!
I hope this article helped you gain a (better) understanding of what ChatGPT does with language. If you’d like to read on, there are two bonus questions below!
- Tokens are ChatGPT’s version of words. A token is usually a bit shorter and a simplified version of a word. For example, the word “playing” is divided into two tokens, “play” and “###ing”. Similarly, German compound words are split into their constituents e.g. “Rindfleisch” becomes “Rind” “###fleisch” etc. This reduces the size of the vocabulary (the set of tokens) that ChatGPT has to learn. ↩︎
Bonus 1: I don’t like this circular definition of word meaning that ChatGPT uses. Can’t we do something else to teach machines human language?
Indeed, it is quite surprising how brittle modern language models seem sometimes when they fail at the simplest tasks. One explanation for these failures is actually that they do not have any experience of the real world and are trapped in circles of symbols. Cognitive scientist Harnard called this the symbol grounding problem. How can machines acquire the meaning of symbols without ever interacting with the referents in the physical world? The concept of embodied cognition stipulates that our cognition, communication, and language are strongly driven by our biological shape and its features and sensory capacities. So do you need a human-like body to understand human language and to develop general intelligence? This idea and many failures in classical AI have led to a partial paradigm shift in research towards embodied AI.
Bonus 2: But if ChatGPT doesn’t “understand” language as I do, why does it “get” what I ask it to do so well?
That’s a good question. How is it possible that a token-prediction machine understands my instructions? The trick that teaches language models to follow your instructions so well is showing them a lot (tens of thousands) of instructions and their completions. These examples of instruction following are hand-crafted (in most cases) and are the last batch of input data that such a language model sees in the token prediction training stage.
What does this hand-crafted instruction following data look like? The OpenAssistant project collected and curated a large amount of such instructions and made them freely available to anyone. Let’s look at an example:

The dataset contains special tokens in angled brackets that signify turn taking in the conversation, and the first token of a turn indicates who is speaking. This dataset contains over 13 ‘000 such examples. There are many more of these datasets that are available under open licences.
What effect does the instruction tuning yield then in a language model? Let’s look at an example where we use the same (arbitrary) writing prompt for GPT-3 (not instruction fine-tuned) and ChatGPT.


As we can see, there is a big difference between the two outputs. The Curie GPT-3 model, that is not instruction fine-tuned, picks up the style and pattern of the prompt and reproduces it in variations. It doesn’t recognize and react to the pragmatic intent of the instruction in the prompt. ChatGPT, by contrast, perfectly understands what the prompt asks for and delivers the desired text. That is, through examples of instruction following, ChatGPT learns to process the pragmatics of human language to some extent.