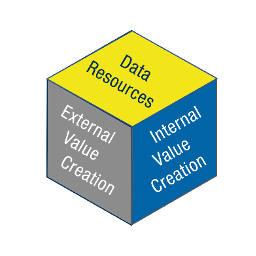
Value Creation with Digital Twins – a Conceptual Framework: Dimension der Datenressourcen
Blog-Autoren: Barth, Linard & Ehrat, Matthias Im ersten Blogbeitrag zum Digital Twin Conceptual Framework der Fachstelle für Produktmanagement des Instituts für Marketing Management wurde das Rahmenmodell im Überblick vorgestellt und mögliche Anwendungen erläutert. Um die Wertgenerierung mit digitalen Zwillingen ganzheitlich zu erfassen, werden im Rahmenmodell die drei Dimensionen «externe Wertgenerierung» (im Markt, bei den Kunden, in der Anwendung und Nutzung), «interne Wertgenerierung» (innerhalb des Unternehmens) […]